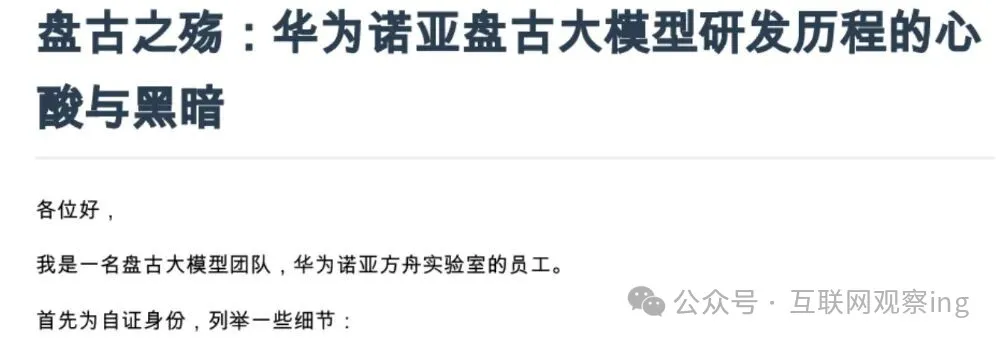
6月12日的华为开发者大会上,余承东站在聚光灯下,用他标志性的激昂语调宣告:”我是第一个做大模型的人。”接着说道:”当时全世界大家都不知道大模型为何物的时候,我们就发布了盘古大模型。”此话一出,举座皆惊。倒不是因为什么真相揭露,而是……余总的幻觉,已经比豆包还严重了。用现在流行的一句话来说,就是“该不会被天意污染了吧?”因为但凡关注过AI的人,哪怕对日期不敏感,也都知道:当华为在2021年4月正式发布盘古大模型时,大模型不仅早已不是什么新鲜事物,整个AI界甚至已经被GPT-3震撼了整整一年零四个月。时间还没过几年,不少人可能是由于过度忙碌,就忘了那个传奇故事的开端。2017年那个夏天,6月12日,谷歌研究团队在arXiv上发表了那篇划时代的论文《AttentionIs All You Need》,提出了一个从前在AI行业无人在意的Transformer架构。这篇论文颠覆了此前主导NLP领域的RNN和CNN模型,用注意力机制解决了长序列依赖问题,更重要的是,它为模型规模的无限扩展提供了可能。2018年10月,谷歌发布BERT模型,一举拿下11个NLP任务的世界第一,证明了预训练+微调范式的强大威力。同年,OpenAI也推出了第一代GPT模型,开启了自回归生成模型的技术路线。此时,”大模型”这个概念已经在学术界和工业界广泛传播,无数研究者开始投身于这场技术革命。2020年5月28日,OpenAI发布GPT-3,参数规模达到惊人的1750亿。这个能够生成真假难辨的新闻文章、写代码、做数学题的AI,几天之内就引爆了全球对大模型的关注。从硅谷到北京,从科技巨头到创业公司,所有人都在讨论GPT-3带来的可能性。而就在这个时候,华为的盘古大模型才刚刚在内部立项。2020年11月,盘古大模型项目正式启动,距离Transformer论文发表已经过去了三年半,距离GPT-3发布也过去了近半年。当余承东说”全世界都不知道大模型为何物”时,OpenAI的工程师们已经在为GPT-4的研发做准备了。不可否认,华为在大模型领域的起步并不算晚。2020年3月,曾在美国任教17年的田奇加入华为云,开始组建AI团队。他敏锐地捕捉到了大模型的发展趋势,在9月推动了盘古大模型的立项。2021年4月,盘古大模型正式对外发布,包含NLP、CV和科学计算三大基础模型。其中,盘古NLP大模型以2000亿参数的规模,成为当时业界首个千亿参数的中文预训练大模型,在CLUE中文语言理解评测中取得了领先成绩。这在当时的中国AI界确实是一个不小的突破。盘古真正的高光时刻出现在2023年。这一年,盘古气象大模型登上了国际顶级学术期刊《Nature》正刊。它能够在几秒钟内完成传统超级计算机需要数小时计算的天气预报,准确率甚至超过了欧洲中期天气预报中心的传统方法。同年,盘古气象大模型入选”十大科学进展”,这是华为AI技术获得的最高学术认可。此时的盘古,似乎正走在一条通往成功的康庄大道上。它避开了与通用大模型的正面竞争,专注于行业应用,在矿山、气象、医药、金融等领域落地了多个项目。但彼时存在一个问题,这么厉害的模型,没听说谁真正上手体验并且分享过应用心得和感受的。后来的故事不少人应该还记得, 2025年夏天,盘古的命运急转直下。2025年3月,年仅34岁的王云鹤接任华为诺亚方舟实验室主任,负责盘古大模型的研发工作。AI行业换帅,往往只有一个原因,前任不行。继任的90后AI人才履历的确漂亮,从2017年以实习生身份加入华为,一路晋升为实验室掌舵人,被业内誉为”盘古少帅”。上任仅三个月后,王云鹤在华为开发者大会上发布了盘古5.5版本,引入混合专家架构,总参数达到7180亿。同时,他宣布将盘古ProMoE模型开源,希望学习千问一样借此构建昇腾生态。这本是一件好事,却成为了一场灾难的开端。因为有人发现,盘古不仅是学千问通过开源构建生态,在模型层面,似乎学的也有点多了。2025年7月4日,一位自称哥斯达黎加大学韩国学生的研究者@HonestAGI在GitHub上发布了一份技术报告。他采用”LLM指纹”技术,通过提取Transformer层中注意力参数的标准差来生成模型的独特”指纹”。分析结果令人震惊:华为开源的盘古ProMoE模型与阿里通义千问Qwen-2.514B模型的参数分布相似度高达0.927,而业内正常独立训练的模型之间相似度一般不超过0.7。更尴尬的是,有开发者在盘古的开源代码中发现了明确的阿里的版权声明,甚至还有未清理干净的”qwen”字样。华为紧急发布声明否认抄袭,称”部分代码参考了业界开源实践,已标注版权声明,遵循开源协议”。但这个解释显然无法平息公众的质疑。就在华为的声明发布两天后,一篇署名”盘古团队前成员”的文章《盘古之殇:华为诺亚盘古大模型研发历程的心酸与黑暗》在GitHub引爆全网,一日内收获超过2500个星标。这篇长文以第一人称视角,揭露了盘古大模型研发背后的种种乱象。作者写道:”因算力紧缺与领导压力,团队采取了套壳竞品模型、续训、去水印等一系列操作。”他还提到,团队成员长期处于超负荷的工作状态,”在苏州研究所的大楼里,经常能看到凌晨三四点还亮着的灯”。懂AI行业的都知道,如果研究顺利,这都不是事儿,因为钱会如潮水般涌来。文章直指王云鹤是这些行为的主导者。“王云鹤上任后,为了快速出成果,要求我们在一个月内拿出能与GPT-4抗衡的模型。这根本是不可能完成的任务。”作者写道,”当我们提出反对意见时,他说’做不出来就滚’。”这场风波迅速发酵,对华为的品牌形象造成了巨大打击。2025年8月底,华为云启动大规模组织调整,盘古相关部门被裁撤,资源全面回撤到芯片和算力产业。曾经雄心勃勃的盘古大模型团队,一夜之间分崩离析。团队解散后,王云鹤在华为内部的处境变得十分尴尬。他被调离了核心研发岗位,负责一些边缘项目。2026年3月28日,这位曾经的”盘古少帅”在朋友圈发文,正式宣布离职,结束了他近九年的华为生涯。离职仅两个月后,王云鹤就创办了自己的AI公司——上海基元律动科技有限公司,与他一同创业的还有原华为诺亚方舟实验室首席研究员韩凯。公司聚焦AI Agent领域,华为履历成为了二人身上不愿提及的伤疤。回到余承东的演讲。当他说”我是第一个做大模型的人”时,不知道因为团队解散而被迫离开模型行业的前盘古成员们,会不会想起那个初见GPT3时的惊艳。但时间,不会给出答案,还会磨损真相。




 微信扫一扫
微信扫一扫