








金磊 发自 凹非寺
量子位 | 公众号 QbitAI
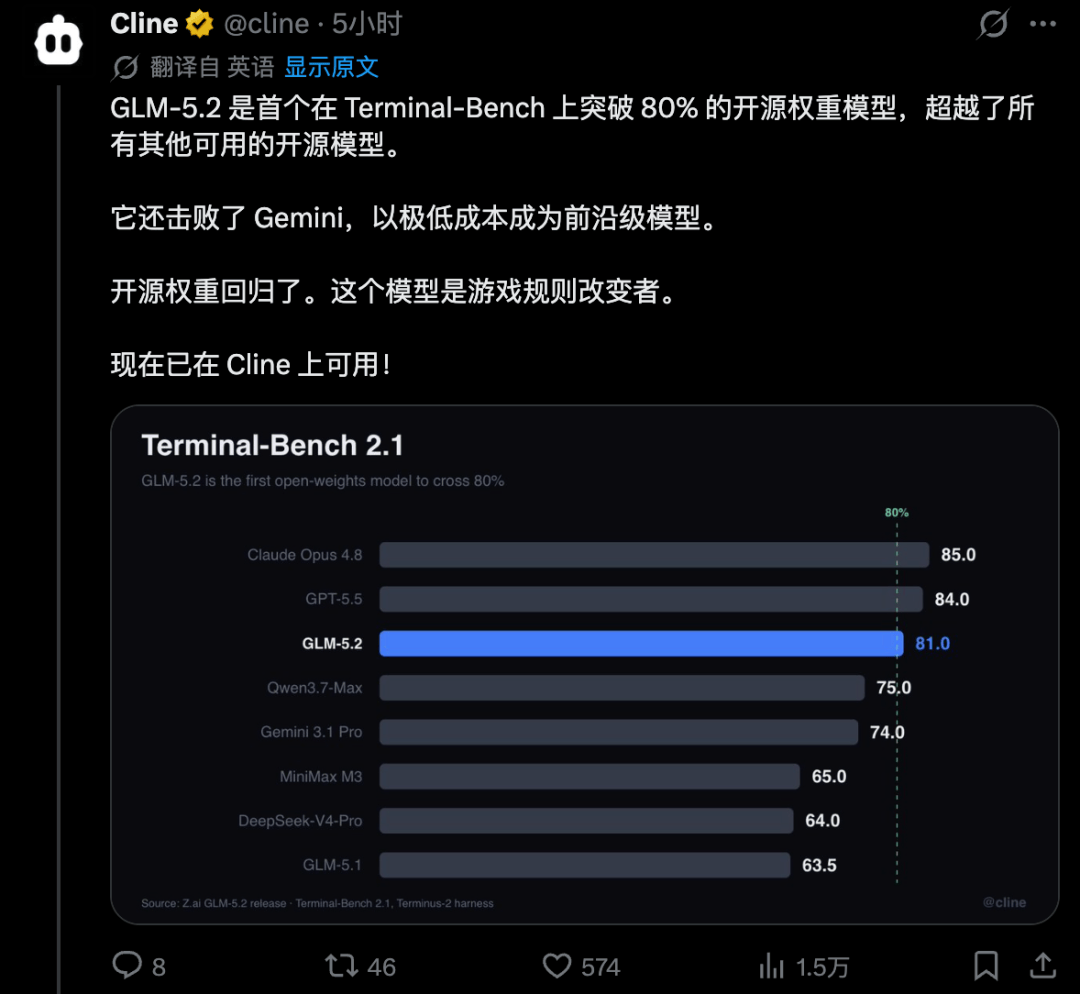
在Coding这件事上,国产AI又famous了一下。
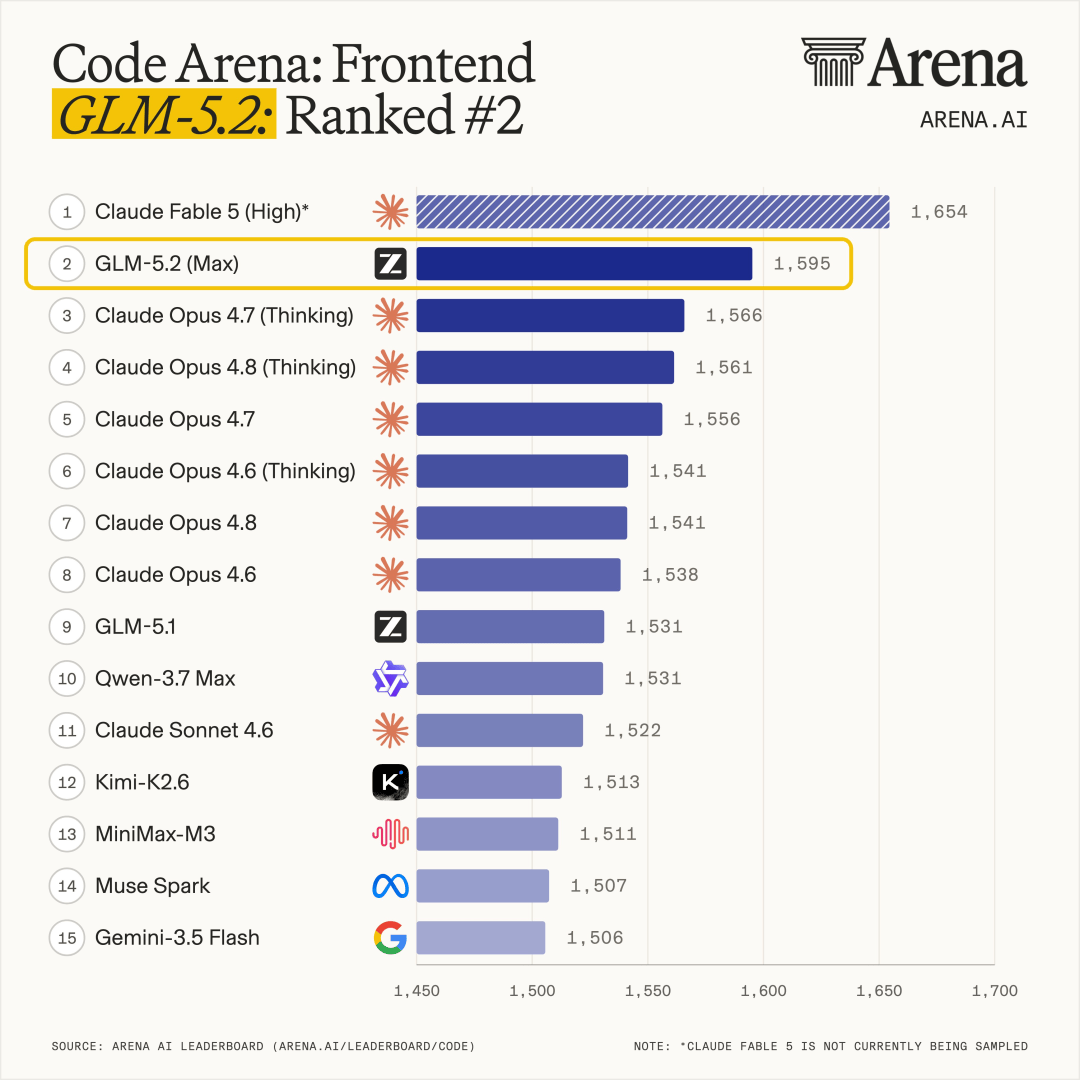
因为刚刚,在Claude Fable 5之下,开源界里拿下了AI编程第一(全球第二):

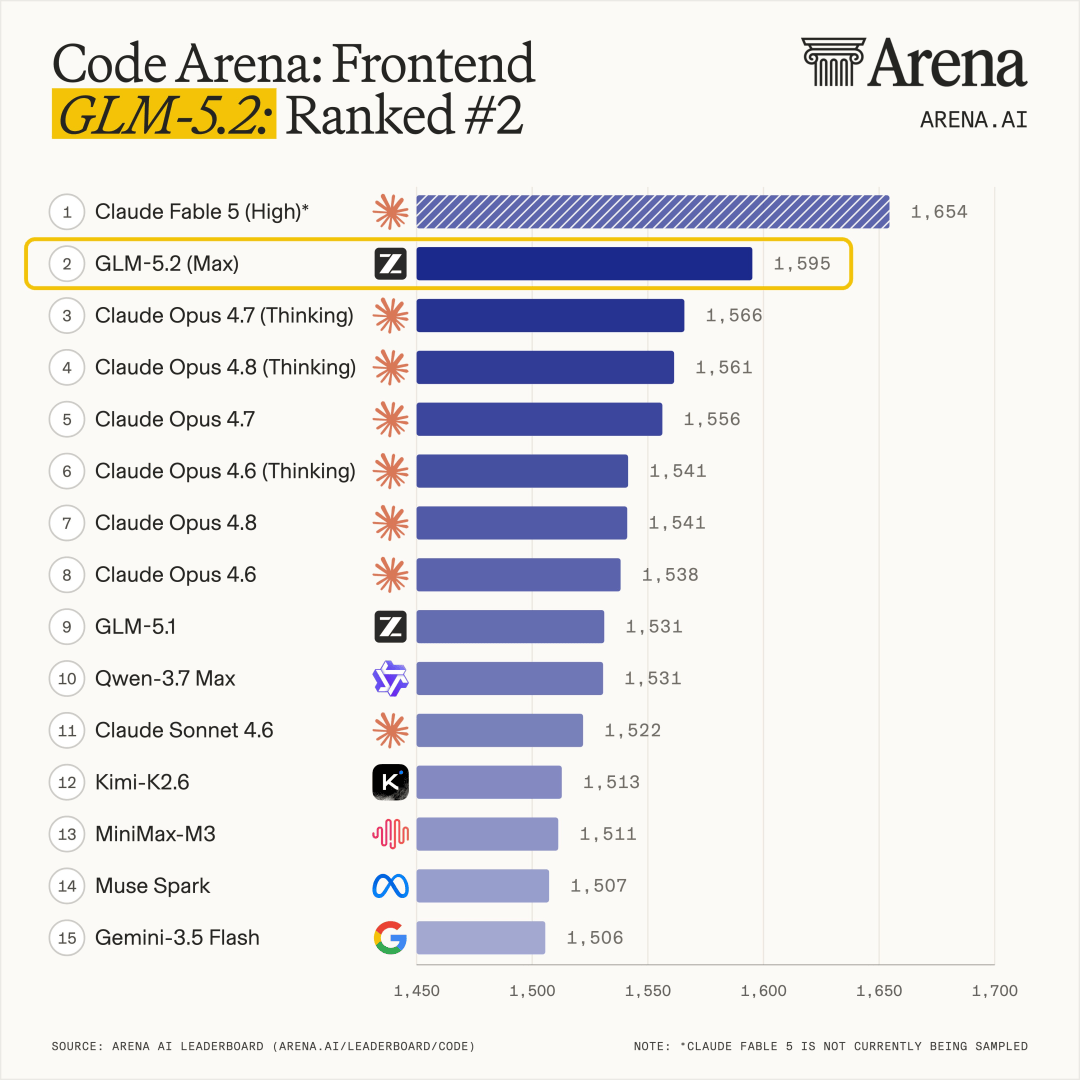
不仅Arena官方用“令人难以置信的里程碑”来形容GLM-5.2取得的成绩,很多网友也是直呼“疯狂”:
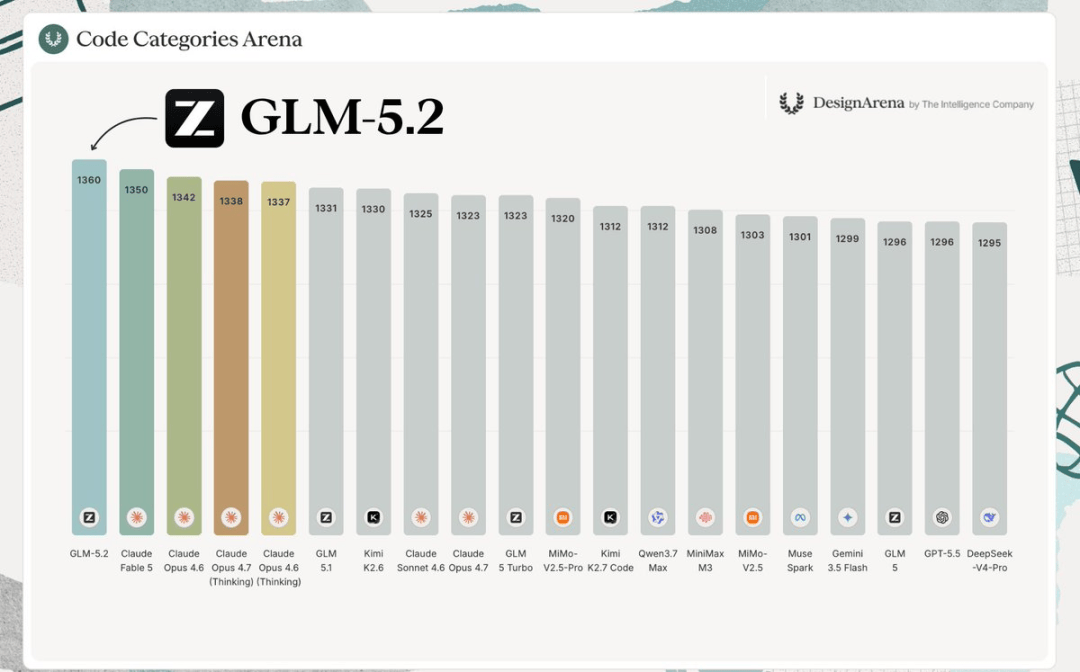
不仅如此,在专门评测模型品味(taste)的Design Arena上,GLM-5.2取得全球第一的表现。
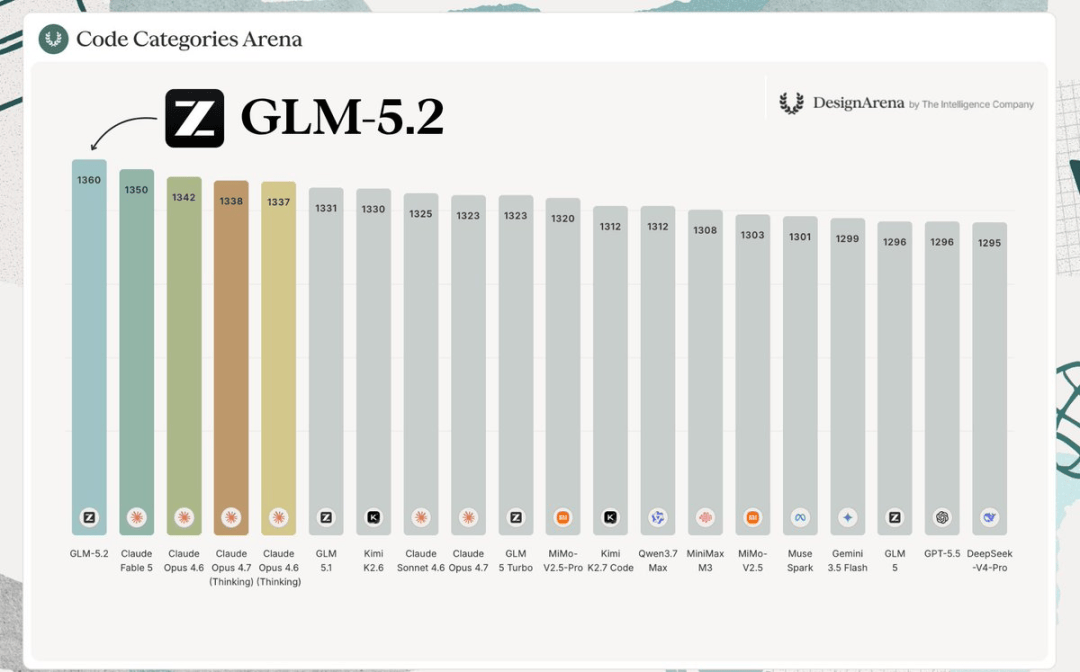
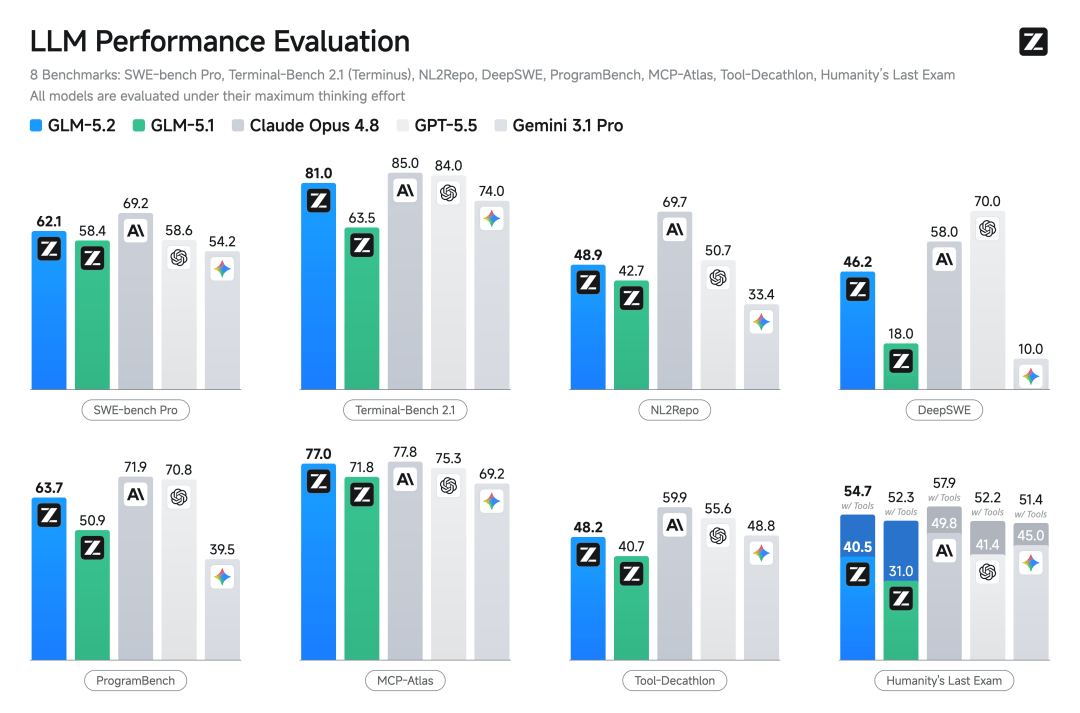
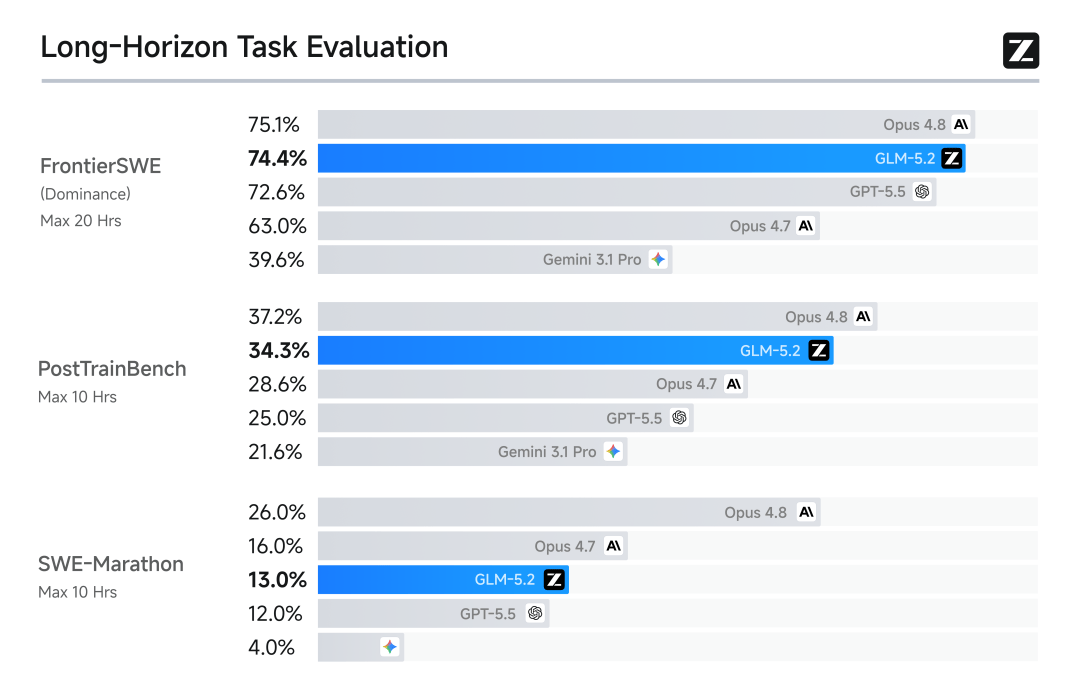
以及,在八项权威基准测试中,GLM-5.2的表现也是比较亮眼:

从结果上来看,国产、开源的大模型,可以说在Coding这件事上,首次跻身模型全球御三家(Claude、OpenAI和智谱)。
要知道,此前提到AI界的御三家,那大概率指向的是Claude、OpenAI和谷歌,不过这一次,从实打实的榜单能力来看,谷歌的Gemini实实在在地被GLM淘汰掉了。

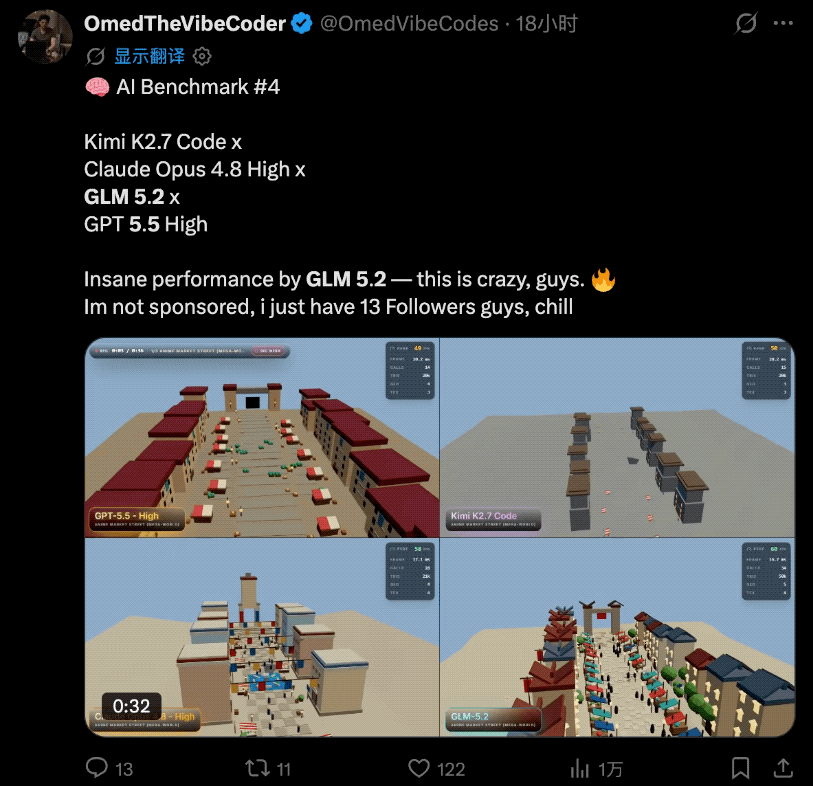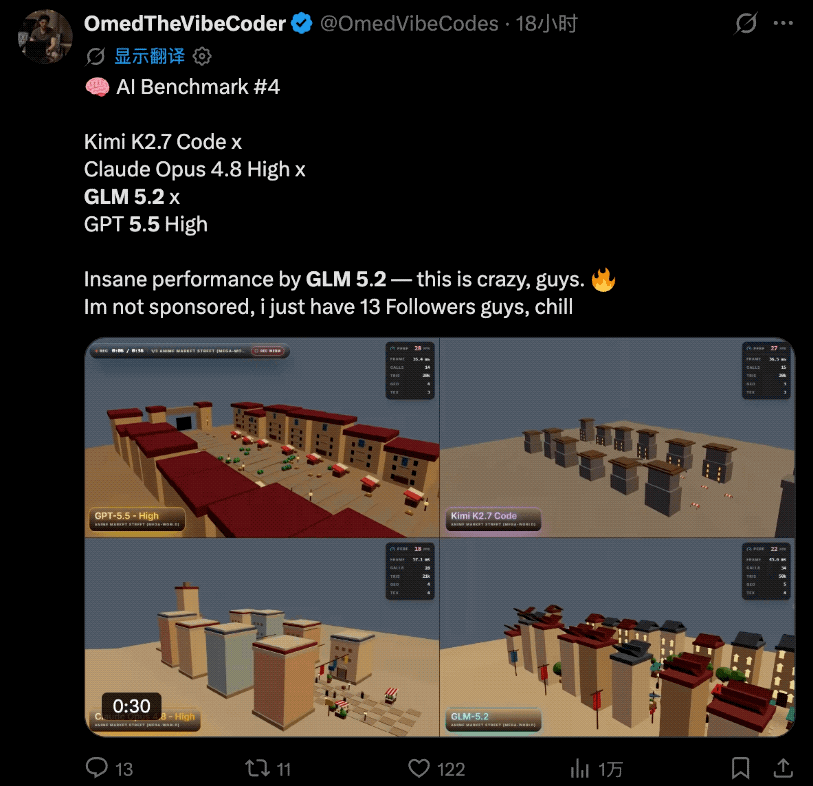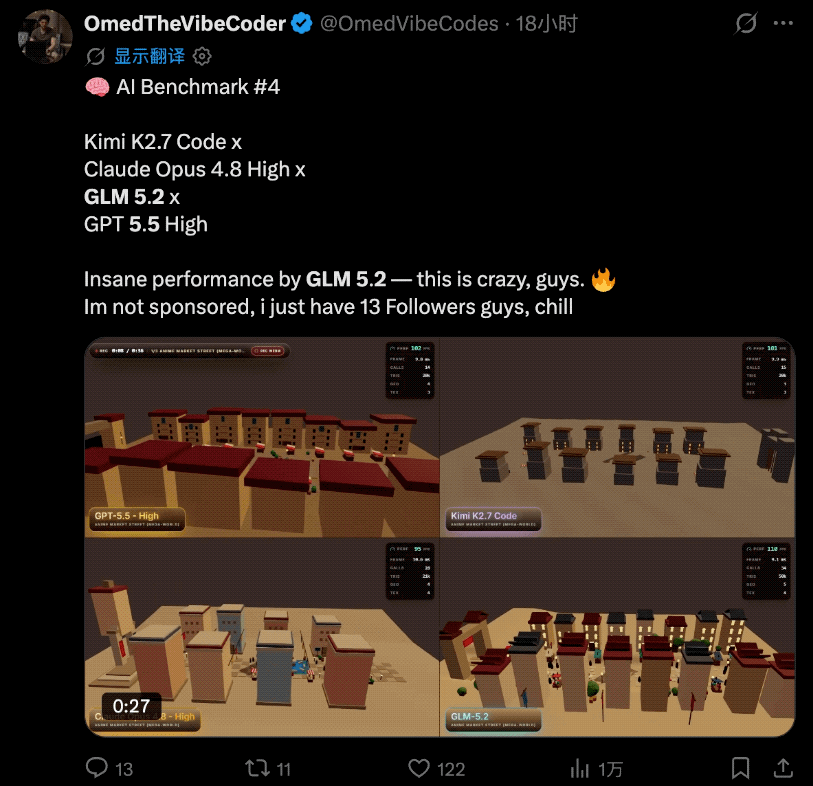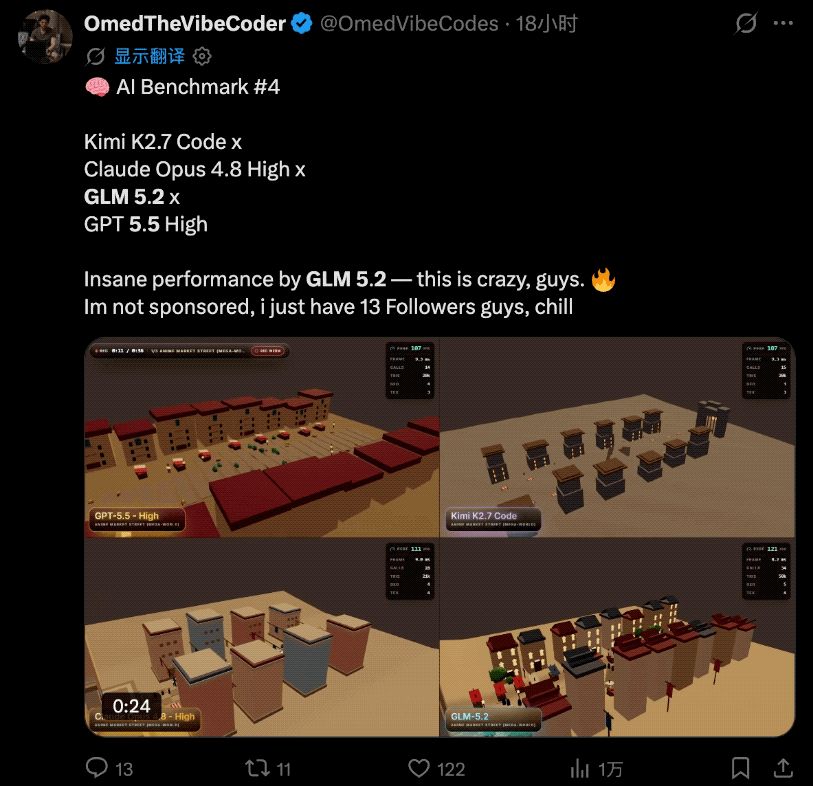
而且这几天国外各大博主陆陆续续开始了各种实测。
当然,实测的主角不只是GLM-5.2,他们还把GPT-5.5 High、Opus 4.8 High和Kimi K2.7 Code拉来一起同台竞技。
先说结论:
GLM 5.2表现得极其出色。

实际的对比效果是这样的:
这位博主认为这类测试是在X上比较能体现AI实力的那种,而GLM-5.2的表现已经接近Claude Opus 4.8。
无独有偶。
另一位外国博主同样做了类似的实测,GLM-5.2依旧是稳稳输出,让他直呼道:
This is crazy.

但体感和口碑还只是一方面。
若是深挖一下GLM-5.2,它的亮点还包括:
支持真正可用的1M上下文,并在长程任务中继续保持领先。
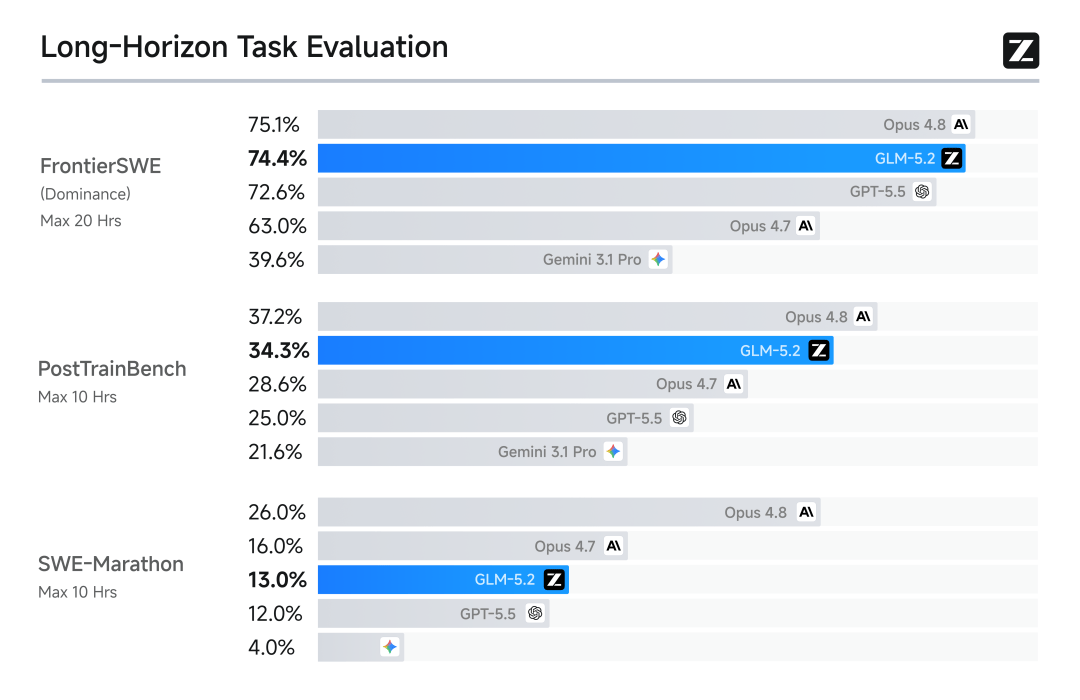
换句话说,现在的GLM-5.2可以一口气“吃”下大项目级上下文、跨数小时自主推进。在很长一段时间里,Opus 级别的长任务与大型开发任务,是国产模型与海外旗舰之间很大的gap。
那么当它走进真实工作环境,效果如何?
一波实测,走起~
是真记得,还是只装得下?完整代码库理解
首先我们要测试的是GLM-5.2的记忆力。
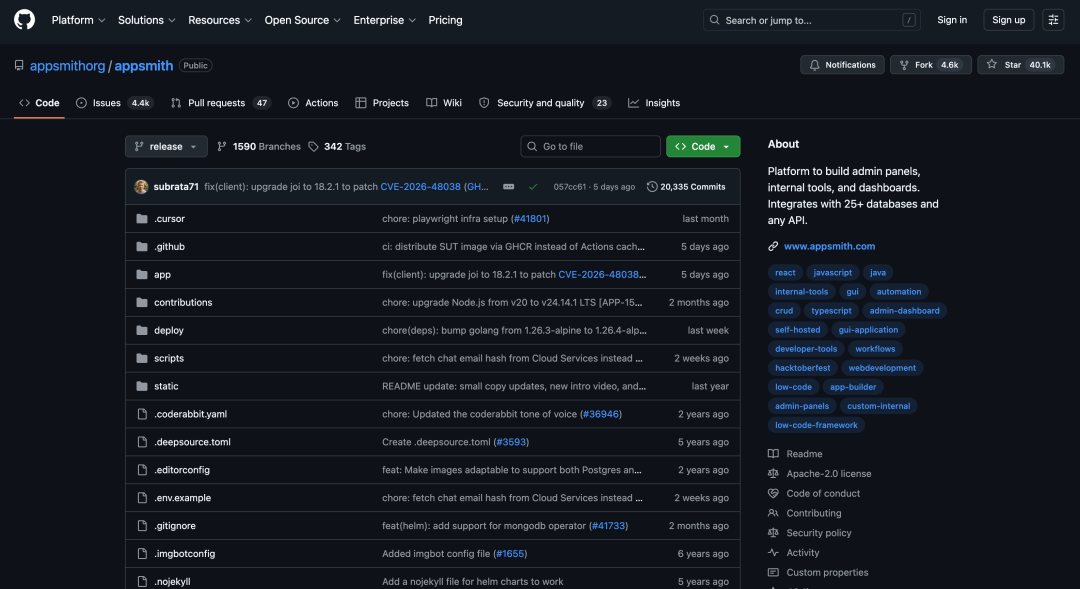
因此,我们特意准备了GitHub上的Appsmith项目。
之所以选这个项目,是因为它是一个开源低代码平台,用于构建dashboard、admin panel、IT自动化等内部应用,天然包含前端、后端、插件、部署、权限等复杂模块。
然后我们直接“喂”给GLM-5.2这样的Prompt:
你是资深软件架构师。桌面上的Appsmith是一个完整项目代码库,请先不要修改代码。 请完成三件事: 1.梳理项目整体架构,输出核心模块、调用关系和数据流; 2.找出跨模块耦合最重的3处,并说明原因; 3.给出一份可执行的重构路线图,要求不破坏现有接口和测试。
这项任务的重点看模型能否把前端、后端、插件、Git服务、运行时和部署关系串起来。
先来看GLM-5.2的结果(上下):

可以看到,GLM-5.2先把Appsmith拆成monorepo结构,前端、后端的定位,以及拆分目录也是非常精准。
更关键的是,它把几条主链路串了出来。并且在耦合点判断上,GLM-5.2也抓到了3个关键位置。
接下来是CodeX的表现(上下):

从输出的效果来看,CodeX的结果更加清爽一些,它直接画出了Appsmith的整体架构图,并且对核心模块的拆解也准确。
两者的判断有不少交集,都抓到了前端Redux/Saga中心化、后端ActionExecutionSolutionCEImpl.java过重,以及CE/EE继承结构的问题。
不过虽然Codex的可读性更强一些,但更像一份结构清晰的技术备忘;而GLM-5.2覆盖更深,文件、链路、风险点和迁移阶段给得更多,像是在给项目做一次工程体检。
跨文件追Bug
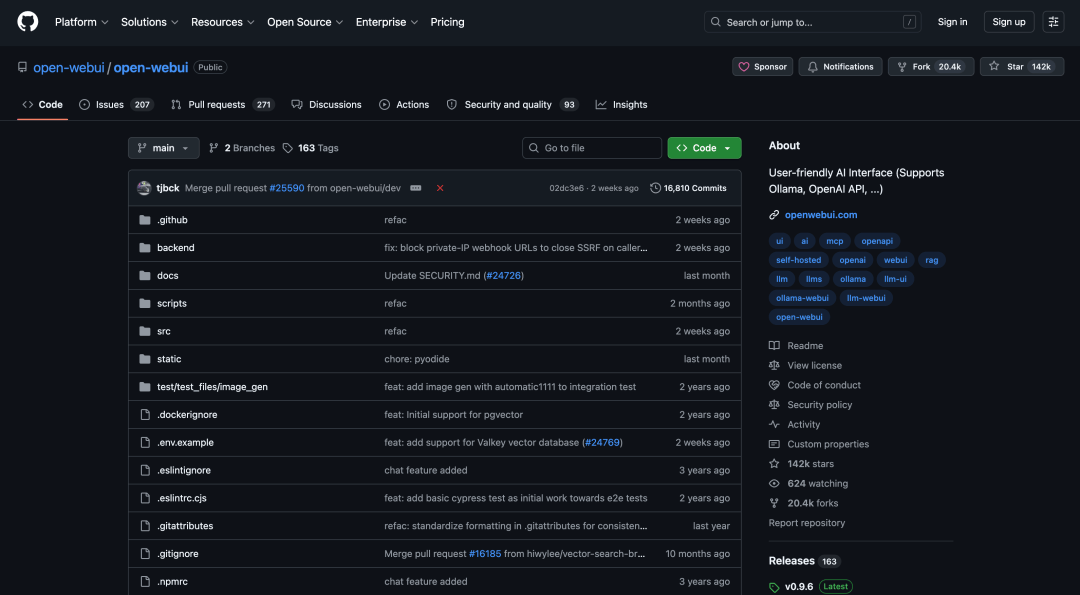
第二项实测,我们换成OpenWebUI,测试一个真实工程里常见的问题,跨文件追Bug。
Prompt是这样的:
桌面上的 open-webui项目里有一个线上Bug,请你从全库代码中定位可能原因,给出: 1.最可能的问题链路; 2.涉及文件和函数; 3.修复方案; 4.需要补充的测试用例。 不要只看单个文件,请结合调用链分析。
GLM-5.2抓住了一个核心点,也就是DirectConnection流式返回的边界不可靠(上下)。

它把问题定位到“前端把上游SSE分片后再回传,后端按完整事件解析”这条链路,并给出前后端两侧修复方向。
这一关很适合看模型有没有真正沿着调用链走。
如果只看单个文件,很容易给出“加重试”、“加日志”、“检查缓存”这类通用答案。但这个问题真正藏在前端chunk、SSE协议、socket转发和后端JSON解析之间。
新增功能
第三个实测,我们继续用OpenWebUI,任务是新增“会话摘要导出为Markdown”功能:
请在 open-webui项目中新增一个“会话摘要导出为Markdown”的功能: 1.用户可以选择一个历史会话; 2.系统生成结构化摘要; 3.支持导出Markdown; 4.补充必要测试; 5.不要破坏现有接口。 请先给出实现计划,再分步骤修改。
对于这个任务,模型需要先理解会话数据怎么存,权限怎么判断,前端菜单入口在哪里,API怎么封装,测试应该放在哪里。
GLM-5.2这一轮更像完整工程交付:

它把“Markdown导出”拆成后端工具、路由、前端API、UI入口和测试五层;最后,它跑出了38个后端测试全部通过。
这就是AgenticCoding真正要看的地方。交付物不能只是一段代码,还要能并入项目。
一口气做多项任务
第四个实测,我们这次尝试让GLM-5.2和CodeX一口完成多个任务。
Prompt是这样的:
基于公开可验证数据,构建一套可追溯、可复现的 2026 年英国 PBSA(学生公寓)行业研究与数据分析包,系统评估学生需求、供给管线、租金走势、运营商格局及投资环境,为内部投资与预算决策提供支持。
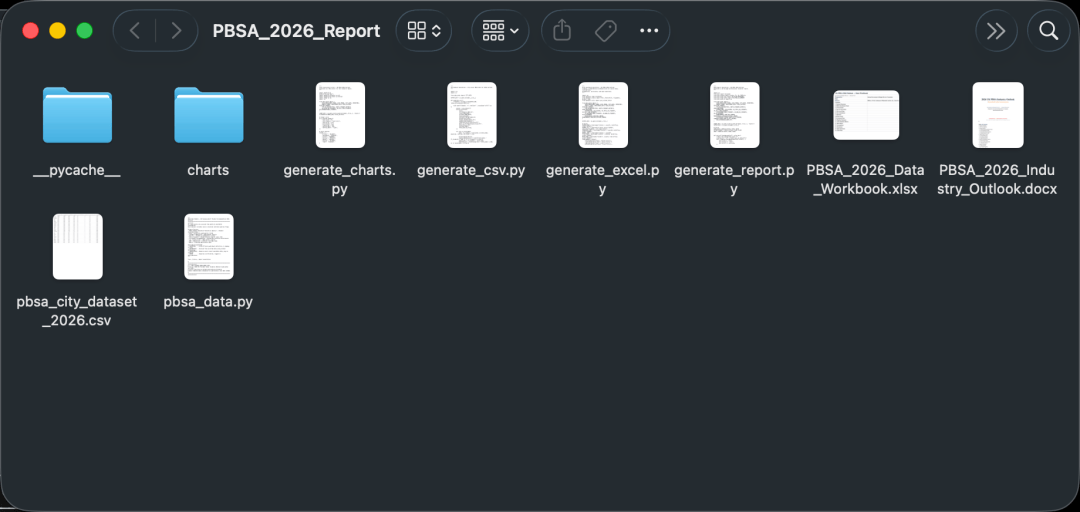
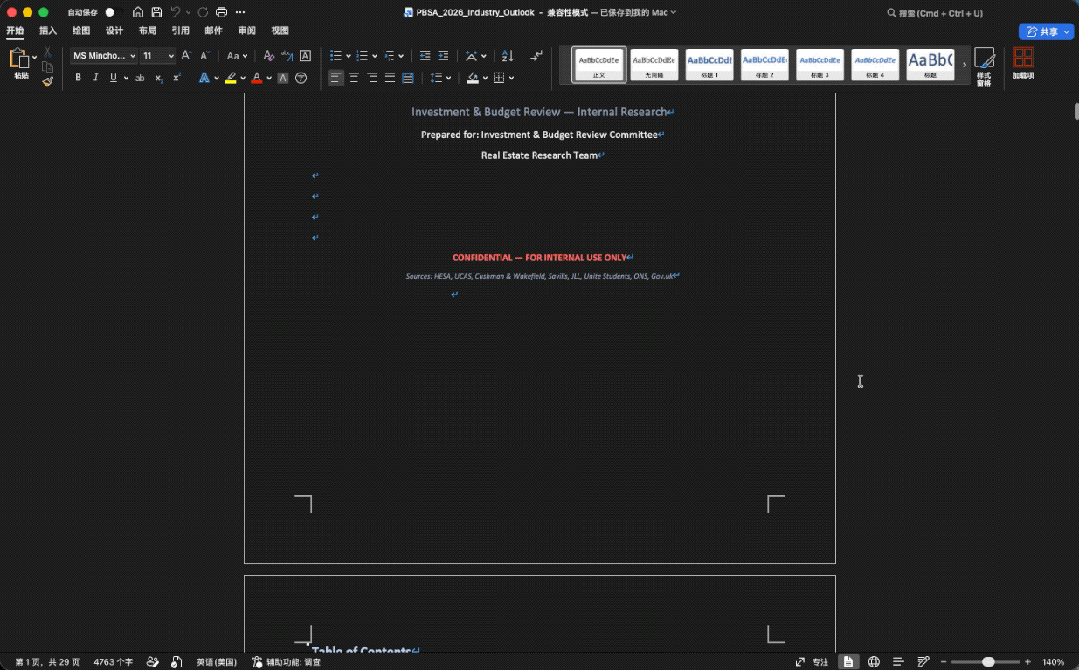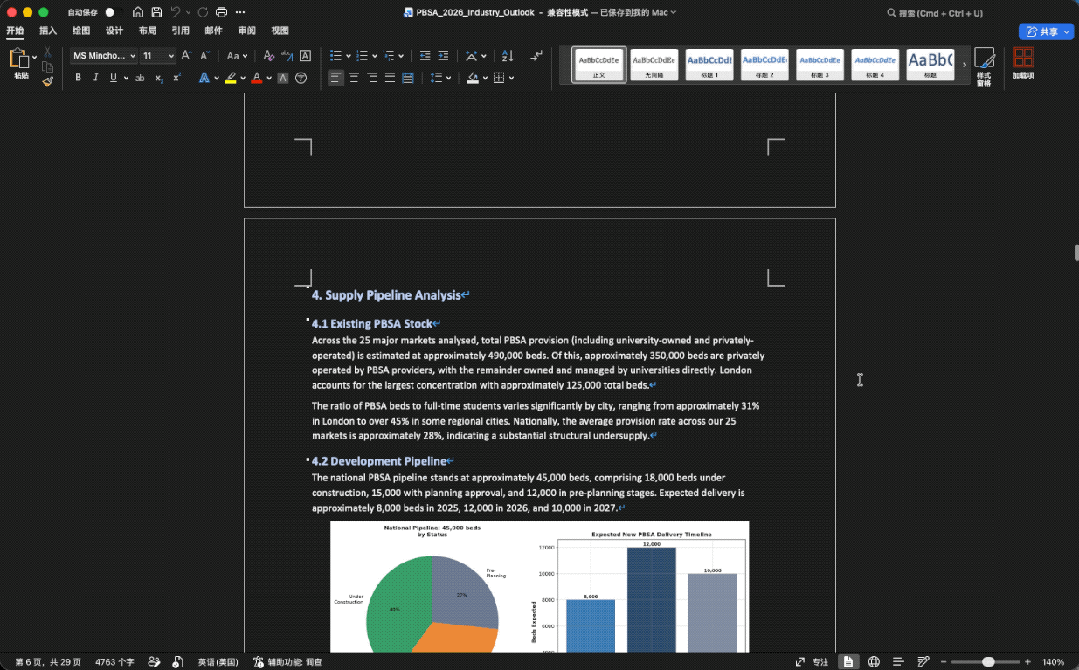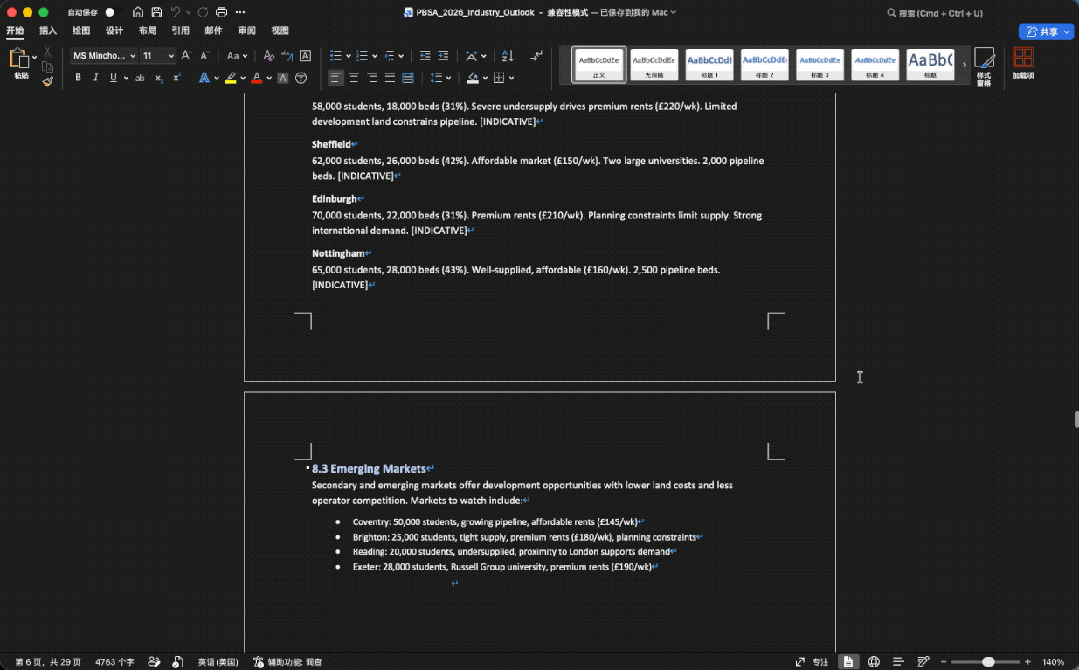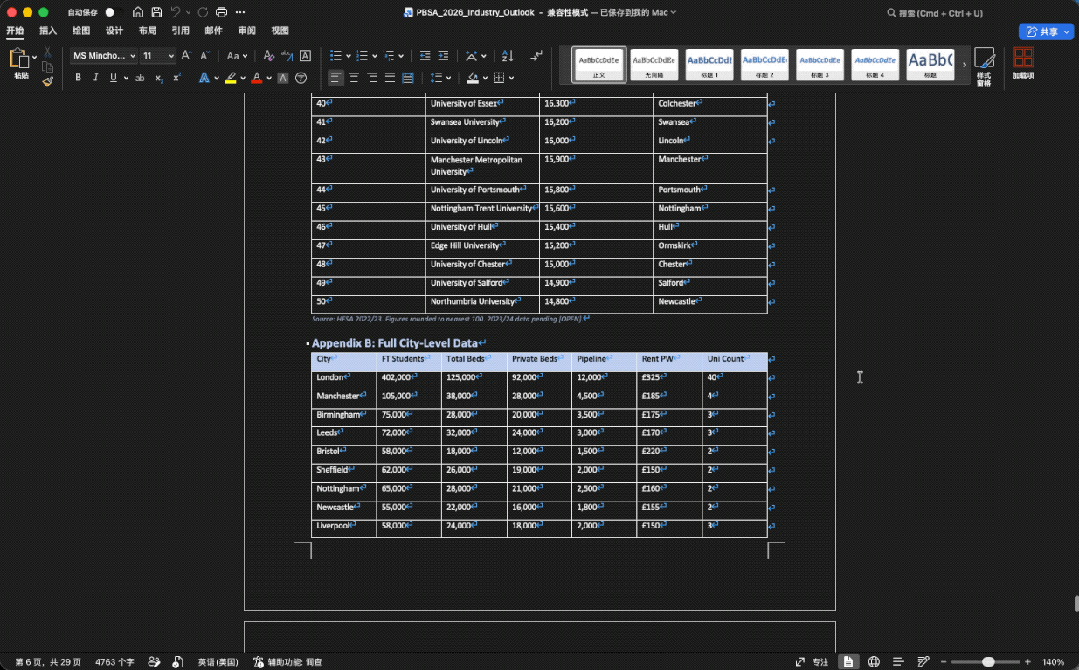
在片刻之后,GLM-5.2一口在桌面输出一整个文件夹的内容:
做的图表是这样的(上下):

也同时生成了一份完整的分析报告:
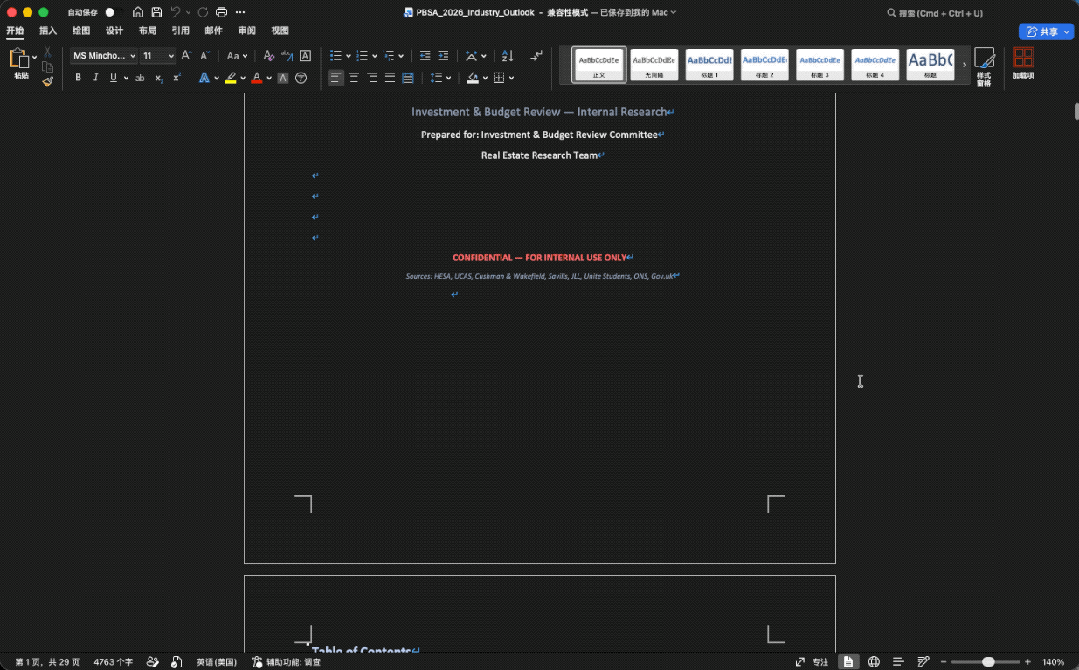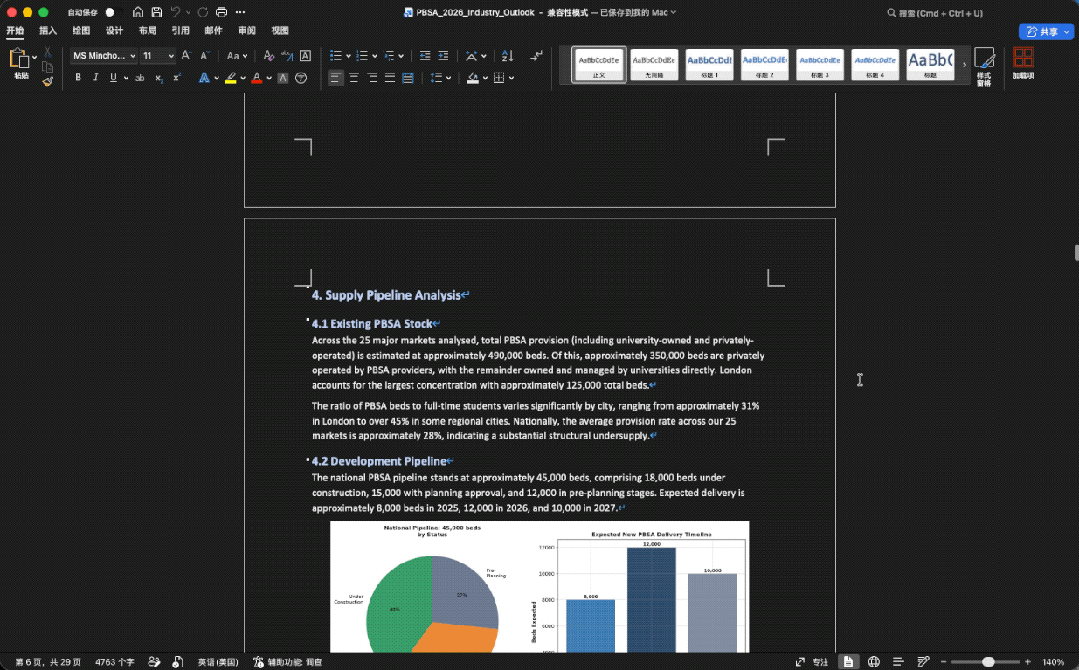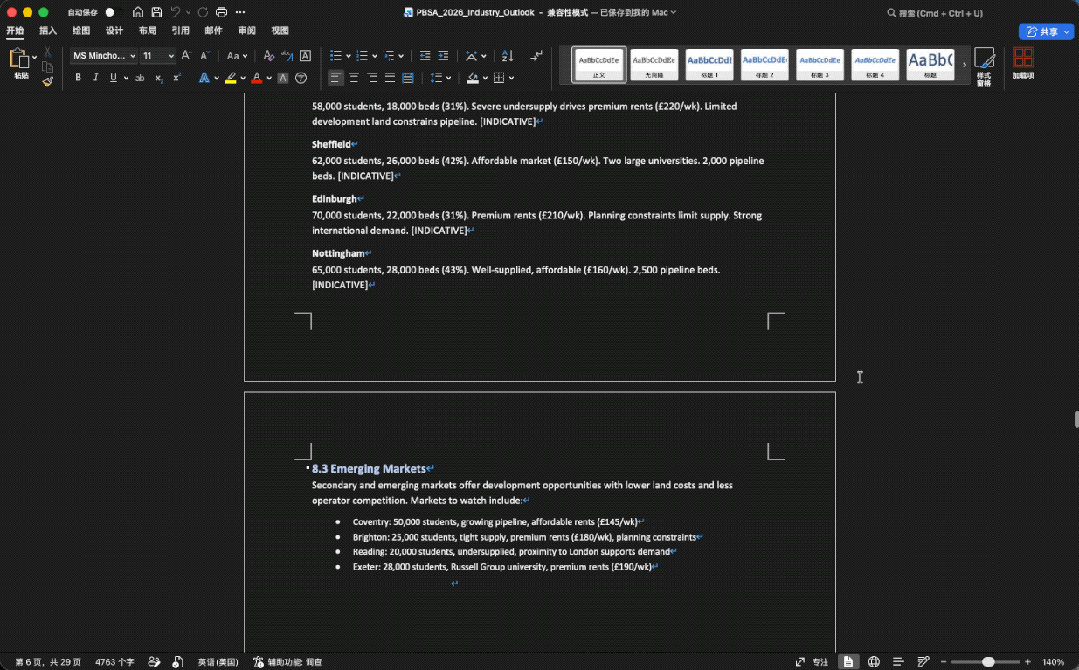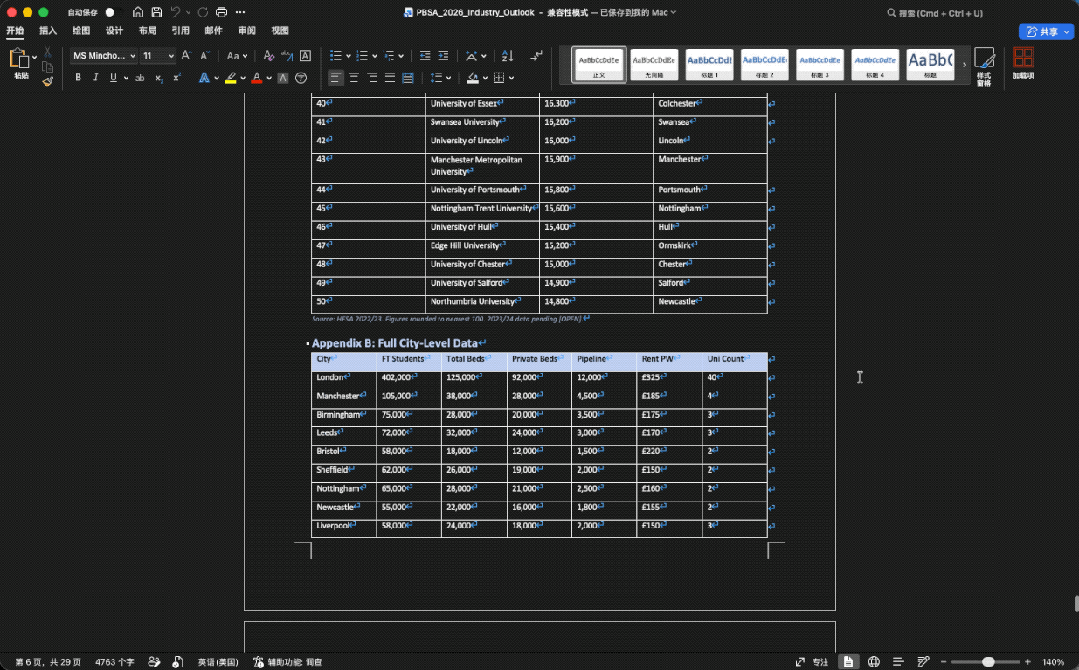
整体来看,GLM-5.2在文件数量、表格结构、图表覆盖、复现脚本和数据质量控制上更完整,最终更像一套可以拿去内部评审前继续打磨的研究材料包。
什么时候别用1M
不过有一说一,1M上下文并不是什么任务都适用。
如果只是改一个小函数、补一个简单脚本、改一个按钮文案,整库上下文的收益并不明显。很多时候,只给必要文件,模型反而更快、更干净,也更不容易过度设计。
真正适合1M上下文的,可能是下面这几类任务:
整库理解、跨文件追Bug、长期重构、复杂功能新增、多交付物研究项目、超长文档审阅、代码和文档一起分析。
也就是说,1M上下文是为了让它在真实工作里少忘事、少跑偏、少反复问你要背景。
它把长上下文从一个发布参数,拉回了开发者和知识工作者真正熟悉的现场:一个大项目、一堆历史包袱、几个跨模块Bug、一项不能破坏旧逻辑的新需求,以及一整套必须同时交付的报告、表格、图表和脚本。
模型竞争进入长期工作能力阶段
这轮测完,一个最直接感受或许是这样的:
AICoding正在换阶段。
过去大家更关注模型会不会写代码、会不会补全、会不会一次性生成一个Demo。这个阶段比的是单次输出能力。
但现在,开发者开始把模型放进真实工程流里使用。任务不再是写一个孤立函数,而是读完整项目、理解架构、追踪调用链、保持需求约束、修改多处文件、补测试、生成文档,甚至连续十几分钟、几个小时自主推进。
这时候,模型竞争的核心就变了。
上下文长度不再只是参数表上的数字,它开始变成Coding Agent的工作内存。一个Agent要持续工作,就必须记住项目结构、接口约定、历史决策、工具调用结果、中间修改状态和用户最开始给出的边界条件。只要中途忘掉一项,最后产物就可能偏。
所以长上下文真正重要的地方,在于把AI Coding从会写一段代码,推向能做一段工程。
这也是为什么GLM-5.2有机会进入AI Coding里的“御三家”。
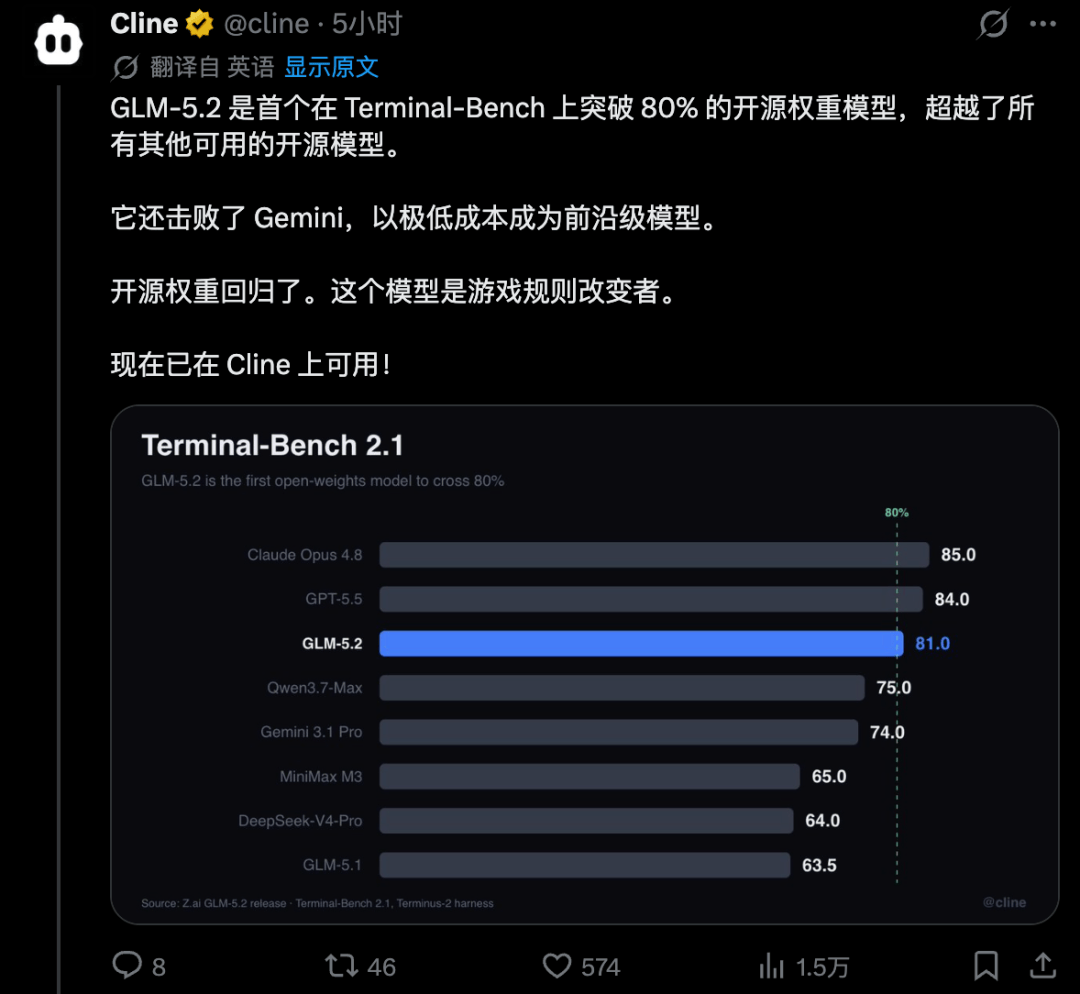
在全球CodingAgent进入硬核的长程工程阶段后,开发者正在形成三类主流选择:ClaudeCode、OpenAICodex,以及以GLM-5.2为核心的开源长程CodingAgent路线。
- Claude Code代表的是闭源Coding Agent体验的上限,强在工程体感、工具调用和复杂任务推进;
- OpenAI CodeX代表的是OpenAI体系下的代码生成和智能体路线,背后有模型、产品和开发者生态的连续投入;
- 而GLM-5.2代表的,则是另一条同样关键的路线:开源、长上下文、面向真实工程任务的Coding Agent底座。
这条路线的价值,不只在于国产模型也能写代码。
更重要的是,当AI Coding进入大工程阶段,开发者需要的不只是一个云端黑盒。很多团队会关心模型能否私有化,能否接入自己的工具链,能否读内部代码库,能否承载长上下文任务,能否在成本可控的前提下稳定工作。
开源长程Coding Agent路线,正好补上了这块拼图。
如果说前一阶段的AI Coding,比的是谁能更快写出一段能跑的代码;那么下一阶段,比的就是谁能更久地待在项目里,理解它、记住它、改动它,并且不把它弄坏。
这也是GLM-5.2这次最核心的信号:
国产开源模型的竞争,已经不只是在榜单上追分,而是在进入真实开发者工作流,进入长程工程任务,进入AICoding最硬核的牌桌。
而这张牌桌上,GLM-5.2终于有了一个清晰的位置。
本文来自转载 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫 








