火山引擎今天上线了全新的语音模型——
豆包音频生成模型 1.0(Seed-Audio 1.0)。
名字变了。
我上次测还是“豆包语音合成模型 2.0”,是去年10月发布的版本,隔了9个月。这次火山没有继续叫“语音合成3.0”,而是叫“音频生成1.0”。
从 语音合成 升级到 音频生成,是一次完爆以往语音体验的升级。
我第一反应是想起上一版2.0里的那个打工人。
那篇里最出圈的就是它,一段十几秒的设计师独白,一开口就让人幻视工位、设计图、未读消息、领导方便说两句的声音。
先放回去16秒。

这次我用新模型Seed-Audio 1.0,给上个版本续上了完整剧情。
整条音频时长是1分10秒,前16秒是原来的那段,你可以直接拉到16秒听后续剧情。

还是那个音色,还是那个状态,只是这次不是他一个人讲,是他和甲方的对话。
这场景有点缺德,甲方老板被吵醒的睡意都能听得出来。还有电话挂断以后「嘟——嘟——嘟——」的忙音,三秒死寂,太真实了。
这一整段,我没有拆开做任何后期,用Seed-Audio 1.0一次生成的。
上一版我觉得最离谱的是:AI 声音终于不像 AI 了。到了今天的Seed-Audio 1.0,我开始觉得,它不只是能「像一个人说话」,还能用声音导演一段情景、一段戏。
我在上一篇推文的评论区见过一个预言,有条留言我一直记着,有人问:什么时候套到番茄小说去?

当时我没法接。
因为语音合成 2.0 时代已经很像真人了,但你要真拿去做有声小说、漫剧、短剧配音,后面还有一堆活儿:分角色、控情绪、配 BGM、加音效、对环境声、剪辑合成。
这次我拿了一段三人漫剧的本子,扔给音频生成 1.0 配音。

一名旁白(青年男性),一名长老(老年男性),一名少年,音色特征明显,台词极具情绪张力。
旁白是低沉醇厚的国风漫剧腔,长老声音苍老沙哑带有居高临下的轻蔑,少年音清亮带有怒气。
人声之外,还有古筝、大鼓、弦乐、脚步摩擦、灵剑出鞘、金属打击、人群哄笑、钟鸣,爽文该有的都有了。
不用先生成角色 A,再生成角色 B,再找 BGM,再叠脚步声、掌风声、火盆声,最后拖进剪辑软件里一层一层对齐。
一段提示词,直接把一段漫剧该有的声音氛围,整包吐出来。
也就是这次Seed-Audio 1.0 最大的升级:
影视级全要素直出。
这几天世界杯正热,佛得角突然火了。
如果你不怎么看球,可能对这个名字很陌生。佛得角是大西洋上的一个岛国,人口 50 多万,这届是他们第一次踢世界杯。
结果第一场就 0:0 逼平西班牙。最出圈的是他们 40 岁的门将 Vozinha,整场做出 7 次扑救,零封西班牙一战成名。

所以我拿这个背景,让音频生成 1.0 做了一段佛得角门将的世界杯解说。

和影视漫剧不一样的,活动赛事要的就是现场感。
不是围着剧情排好的声音设计,是真实的现场反应,现场是混乱的,观众在吼,球场有回声,解说员要跟着赛事节奏和观众情绪讲解。
这段听下来,是乱出了层次,人声要在前面,现场声音在后面,背景人群声没有盖过人声,解说员的情绪是跟着比赛走的,压住、加速、爆发、回落,听起来就像真的在转播席。
到这里我觉得,Seed-Audio 1.0这个「全要素直出」不是只能做影视漫剧。
不知道你还记不记得,豆包语音合成 2.0时期,我们恶搞了一下《冰雪奇缘》经典名场面,还让安娜说了一段绕口令。但最后,视频在艾莎放大招的时候戛然而止,结束了。这还真不是我们在故意卖关子,是语音合成 2.0当时还扛不起这种“大场面”。

这次Seed-Audio 1.0版本,直接补上了上次没完成的大招——人声、背景音、特效声,一把梭哈。特效部分只靠几行提示词:
伴随着一声能量骤然爆发的“轰”的闷响,和大片冰晶瞬间炸开、四散坠地的清脆碎裂声。
出来的成片和原片放在一起,我不说,你自己对比(课代表:特效画面在成片的17s)

我截了原片这段冰晶的音效,AI直出的效果和原片几乎听不出高下。

去年的版本当时已经很惊艳了,情绪是有的,但现在回头听,还是能听出一点 AI 腔,割裂感也是能听出来的,两个人好像不在同一个空间对话。
再听音频生成 1.0,差别就很明显。Seed-Audio 1.0不只是更像真人,所有人说话像是放进了同一个场景里,这场戏是发生在同一个空间里。
这个升级很关键,也很细节。因为影视剧、短剧、漫剧里,观众听的不是一句一句台词和音效,而是一整个场面。
到音频生成 1.0,这条成片级的音频,已经几乎能直接交付了。
做完这些大场面,我又反过来测了一个很安静的 case——诗句。
诗句其实很适合测语音模型,没有剧情、没有什么复杂的音效可以转移注意力,声音好不好,很容易就露馅。同时,能考验一个AI语音模型对文本的语义理解能力。
我给了一段《将进酒》的诗句,你听完大概会和我一个反应,这和微信公众号里的听全文的机器音,根本不是一个东西。

年长男性,声音要浑厚,有岁月感。不是那种播音腔的标准正确,虽是同一个人,但有情绪起伏变化。
很多 AI 读短句没问题,一拉长时间就开始漂,声音前后不一样。这其实对应到音频生成 1.0 另一个很实用的能力:长程延长一致。
单次可以生成 2 分钟,如果你觉得这一版人物状态对了,还能拿这 2 分钟当参考继续往后延。后面再生成几十分钟,音色、语气、环境保持一致性。
这个对有声书、长篇诗文、播客、课程太关键了。
最后我又测了一个轻松点的——四川方言。
这个case纯属想看看之前的方言能力有没有变形。

成都的一条老街,傍晚饭点,人挤人。守着钵钵鸡摊子的老婆婆,一边看着满街乱跑的孙娃儿,一边热络地招呼客人。此起彼伏的叫卖,和着油锅那一声接一声的“滋啦”,织成最滚烫的人间。
◈如何用上Seed-Audio 1.0
测完这一圈,我最大的感受是,豆包音频生成模型 1.0 已经不是单纯的AI 配音工具,是声音导演。语音合成 2.0 那次是解决AI声音像不像人,音频生成 1.0就是解决一段戏的声音如何设计。
任务配音、配乐、音效、剪辑,最后拼到一起是一个人坐在电脑跟前,把谁在说、什么情绪、什么场景、该有什么动静写清楚,交给音频生成 1.0去做。
比如艾莎公主那一段我的提示词是:

提示词不用写得多玄,把四样东西说清楚就行:谁在说(年龄性别+音色)、什么情绪、什么场景、前后中间该有什么声响。
火山方舟上已经上线音频生成 1.0模型,可以直接体验。
传送门:
https://ark.volcengine.com/region:cn-beijing/experience/voice?model=doubao-seed-audio-1-0
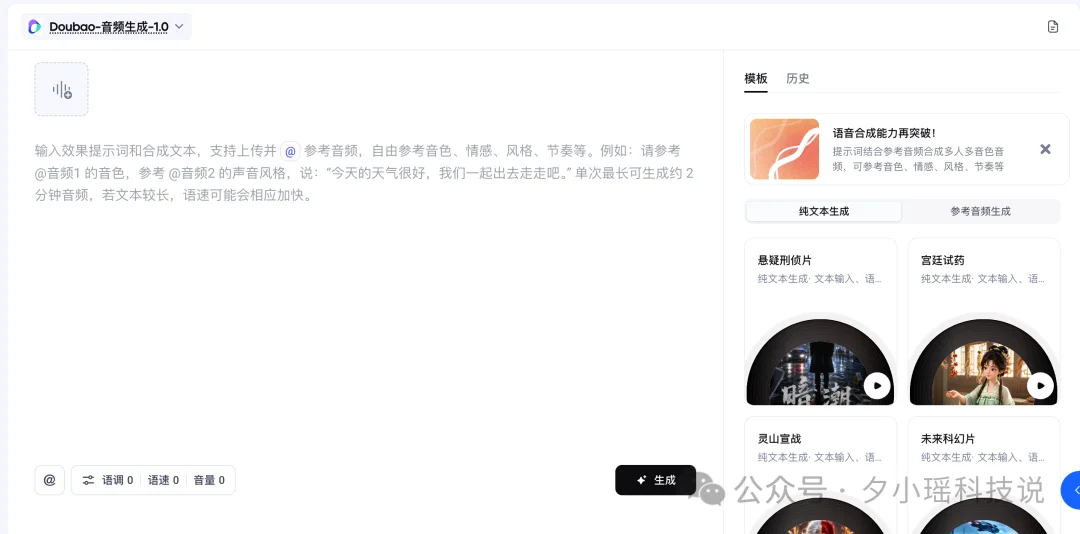
其中这次一个新的能力是参考音频生成音频。
上传一段参考音频,就可以生成与参考音色相似的音频。我第一个打工人的case就是把语音合成 2.0的音频上传上去,让音频生成 1.0继续生成的。
具体用法就是在文本输入框中,使用 @就能引用指定音频。同时可以@多个音频,实现多人多音色。
去年_Seedance 2.0_视频生成模型火出圈,让一个人可以做出接近影视成片的视频。豆包音频生成 1.0 给我的感觉很像,一个人可以做出接近成片级的声音。
Seedance 2.0 是视频生成走向成片化的那个时刻,那豆包音频生成 1.0,很像是语音模型走到同一个位置。
声音这件事,从此一个人,就是一支配音团队。
本文来自转载夕小瑶科技说 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫