OpenAI首次启用太阳、大地、月亮命名,全新GPT-5.6正式登场。旗舰Sol编程屠榜,只当了17天第一的Claude Mythos 5,被一夜拉下王座。
OpenAI今夜「三连发」!
就在刚刚,GPT-5.6Sol、Terra、Luna同时登场。
太阳、大地、月亮。GPT系列第一次用天文学给模型命名。
- 超大杯旗舰Sol,直接刷爆了AI编程能力的天花板;
- 大杯Terra,上一代旗舰的水平,但价格只要一半;
- 中杯Luna,每百万token输入只要一刀,量大管饱。

OpenAI用来掀翻Mythos的旗舰,第一次交到了——极少数人手上。
是的,GPT-5.6暂时只向约20家受信合作伙伴开放API和Codex访问,普通用户短期内无缘。
官方的说法是,模型将会在「未来几周」逐步放开。
OpenAI太阳系,登场
此前,Anthropic用Mythos(神话)和Fable(寓言)命名,指向的是AI与人类叙事传统的关系。而OpenAI则选了天体。
Sol是拉丁语中的「太阳」,也是罗马神话里驾驭金色战车、每日横跨天穹的太阳神。
它对标最复杂的推理和研究场景,适合长链条、多步骤的硬任务。
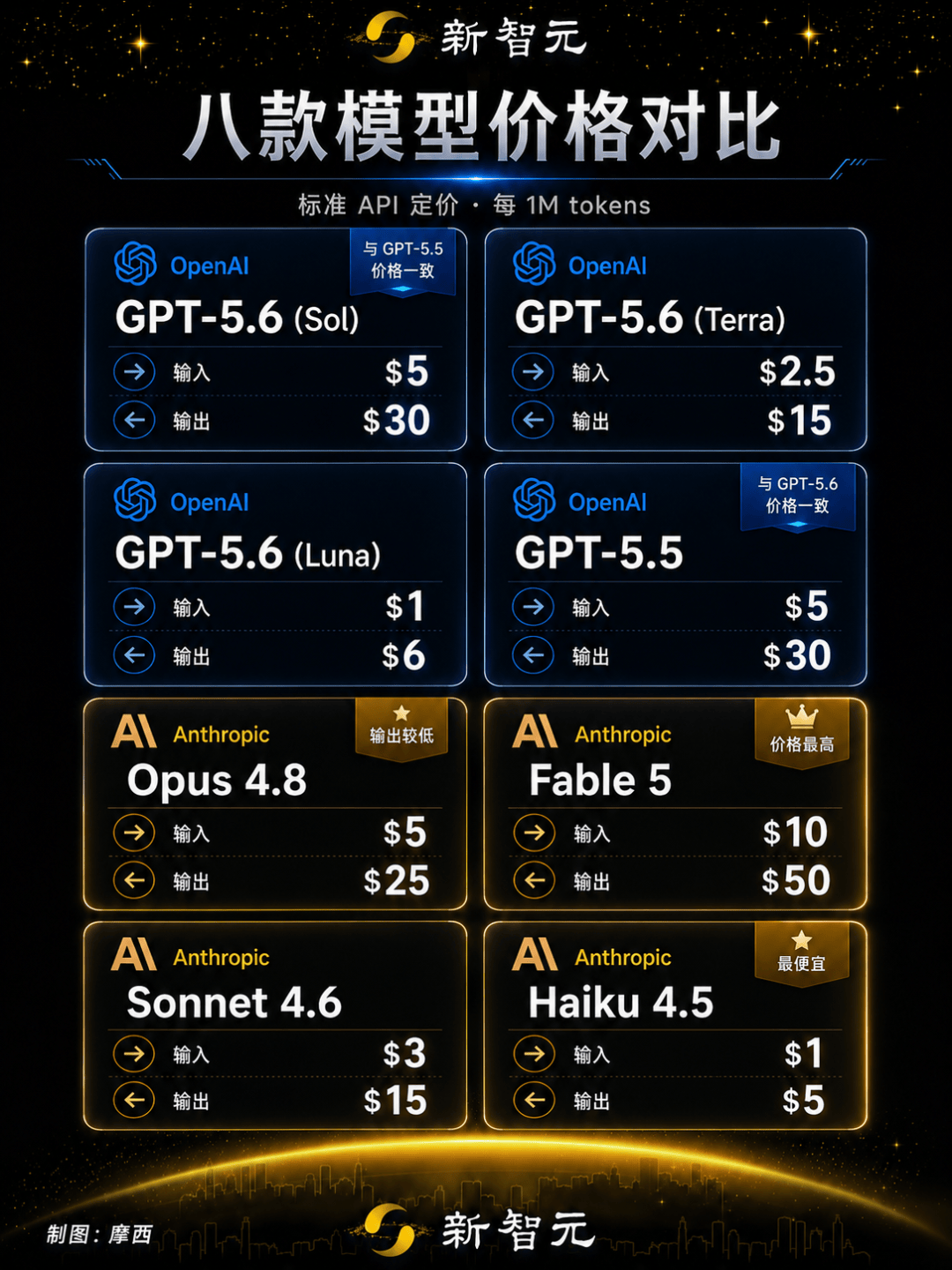
输入5美元/百万token,输出30美元/百万token。
Terra是拉丁语的「大地」,也常被作为Earth的拉丁名和文学化称呼。
它瞄准日常开发和知识工作,用更低的成本拿到上一代旗舰级的能力。
输入2.5美元/百万token,输出15美元/百万token。
Luna是拉丁语的「月亮」,夜空中最近、最亮、最容易触及的天体。
它为高吞吐场景而生,分类、摘要、批量处理,追求的是量大管饱。
输入1美元/百万token,输出6美元/百万token。

根据OpenAI官方的解释:「命名的原则是数字标识代际,Sol/Terra/Luna标识持久的能力层级,可以按各自节奏独立迭代。」
也就是说,以后升级到了GPT-6,旗舰可能依然叫Sol,Luna还是对应最小的那个。
你不用猜,就知道自己在用的是什么水平的模型。
Sol交卷,Mythos让座
OpenAI这次重点秀的能力有三个:编程、生物、网络安全。
编程方面,他们刷的是目前最能衡量AI编程能力的基准之一——Terminal-Bench 2.1。
它考的是代码规划、工具调用、多轮迭代纠错这样完整的命令行工作流,是一个模型能不能像真正的工程师那样端到端地完成复杂项目。
结果显示,Sol在ultra模式下跑出了91.9%,拿下了所有已公开模型的最高分。
作为对比,Anthropic两周前刚发布的Claude Mythos 5在同一基准上是88.0%,Fable 5是84.3%。
Sol关掉ultra只用max模式也有88.8%,单凭这一个数字就已经超过了Anthropic两个最新旗舰。

网络安全,则是OpenAI在博客里着墨最多的方向。
GPT-5.6 Sol在ExploitBench上的表现,几乎打平了Anthropic之前强到不敢发的Mythos Preview,但只消耗了约三分之一的输出token。
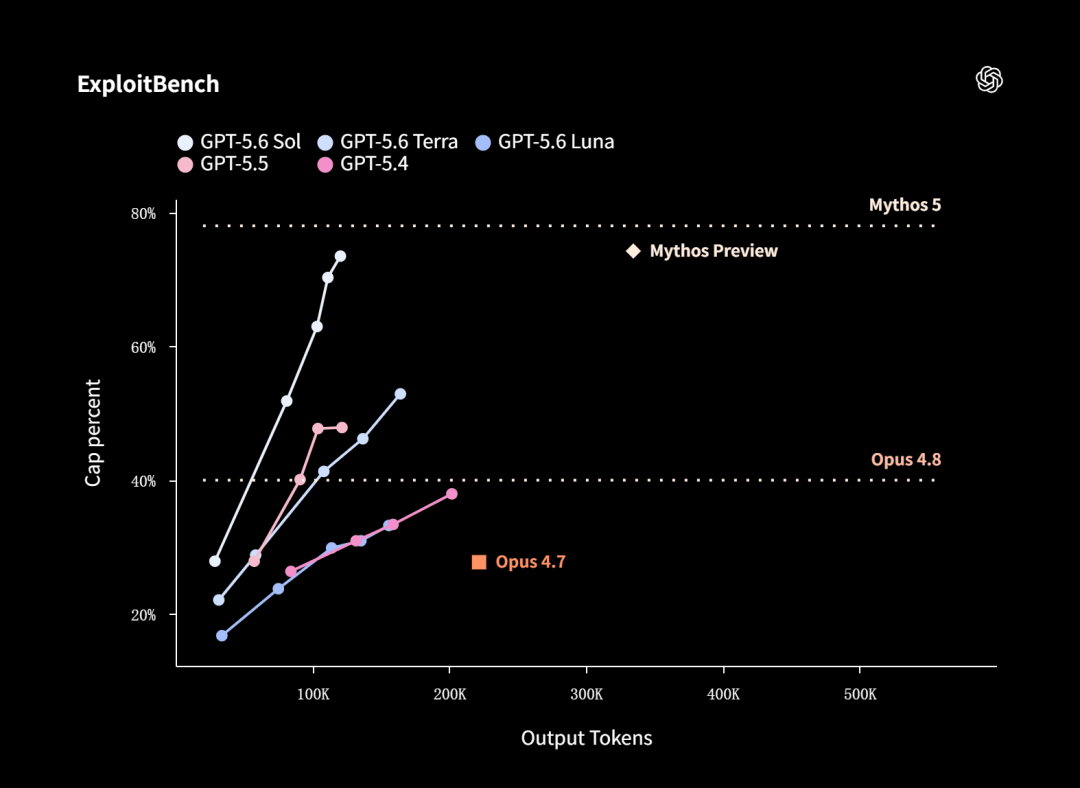
在UC Berkeley与OpenAI等实验室联合开发的ExploitGym基准上,Sol、Terra、Luna三个模型都展示了随推理能力增加而持续提升的安全能力曲线。
而在CTF(夺旗赛)评估中,Sol的命中率更是高达96.7%,几乎触顶。
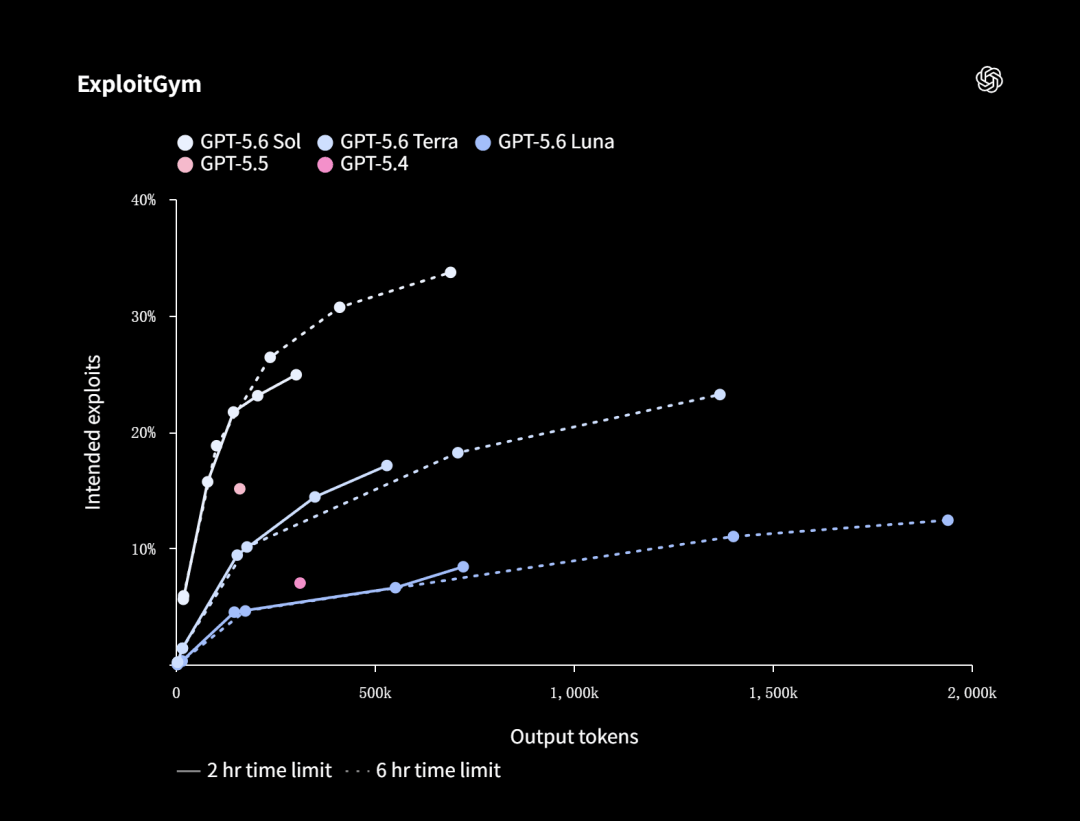
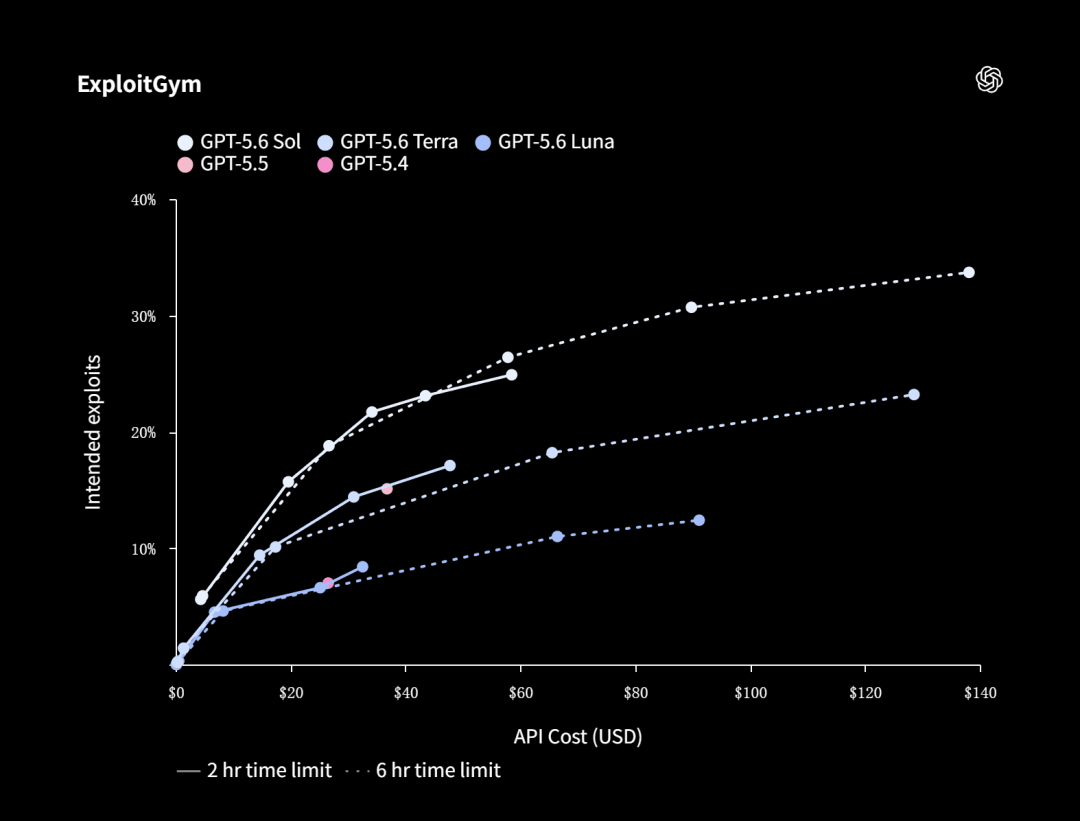
生物学方向,OpenAI跑的是一个专门评估长链条基因组学和定量生物学分析能力的基准——GeneBench v1。
在这里,Sol只需很少的token,就能完爆上一代的GPT-5.5。
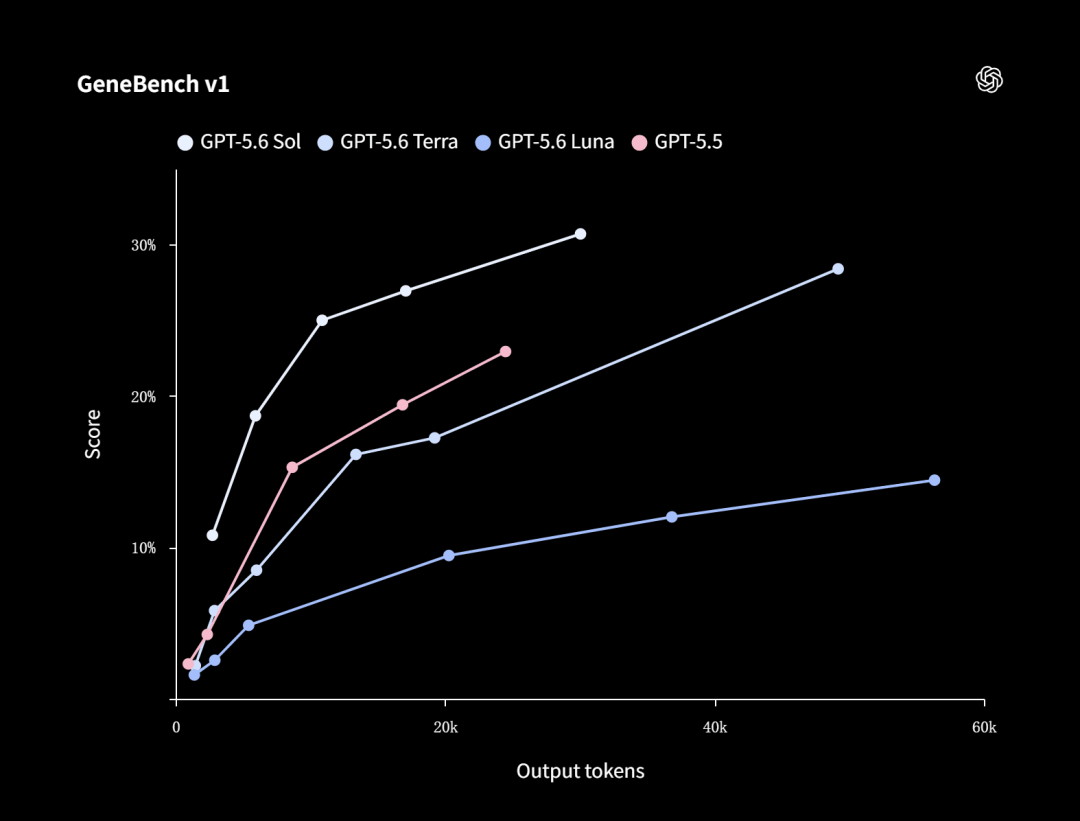
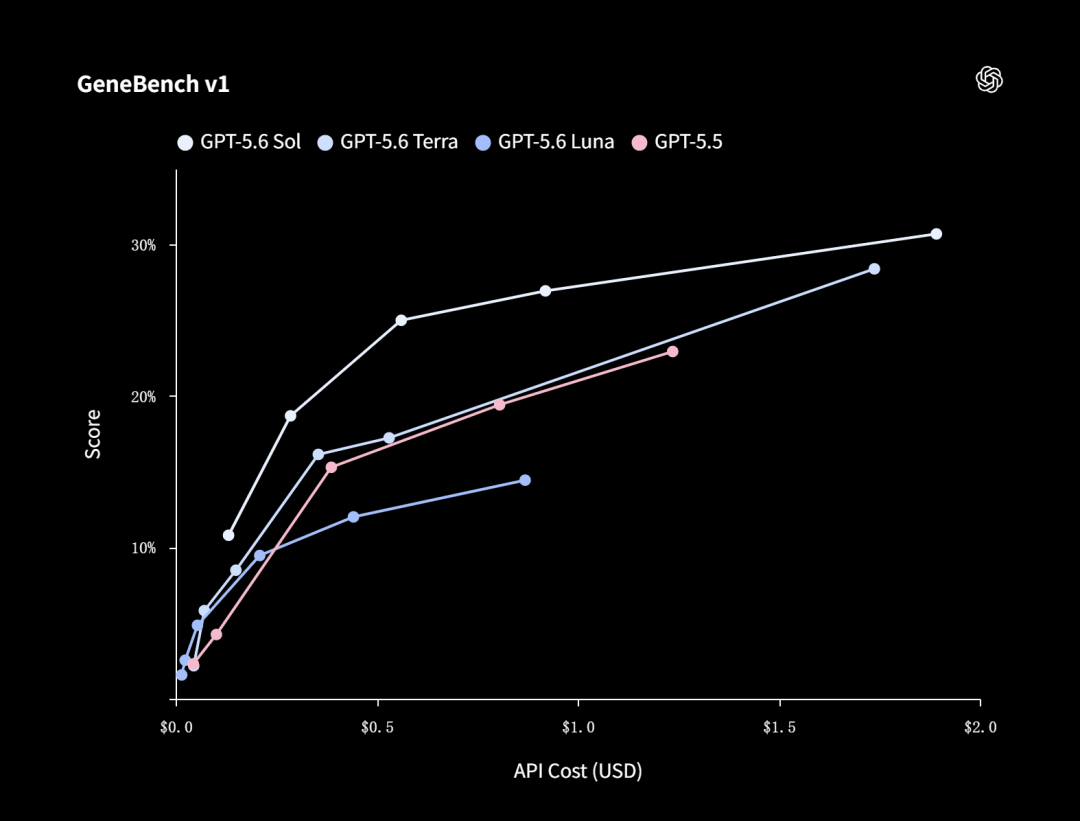
医疗领域的涨幅同样很猛。
在HealthBench Professional上,Sol拿到60.5分,比GPT-5.5高出8.7分。
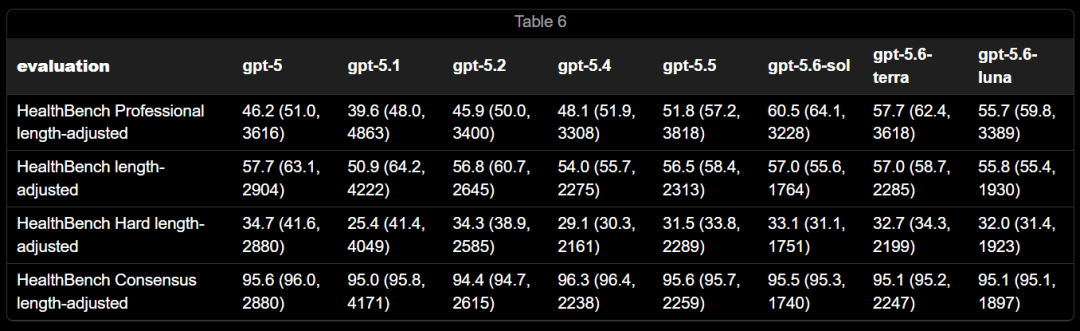
值得一提的是,Terra和Luna是OpenAI历史上首批在网络安全和生物两个领域,同时拿到High能力评级的非旗舰模型。
以前这个级别只属于最强的那一个,这次三个都是。
ultra:一个模型拆出一组智能体
除了模型本身之外,OpenAI这次还重磅推出了两种新的推理模式。
第一种叫max。
也就是大家最为熟知的那种形式——给Sol更多时间思考,让推理链更深更长。
第二种叫ultra。
在这个模式下,Sol不再是单一模型在独立思考。它会自动拆分复杂任务,启动一组子智能体(subagents)并行处理,再汇总结果。
如果max是「让一个人想更久」,ultra就是「让这个人召集一支团队」。
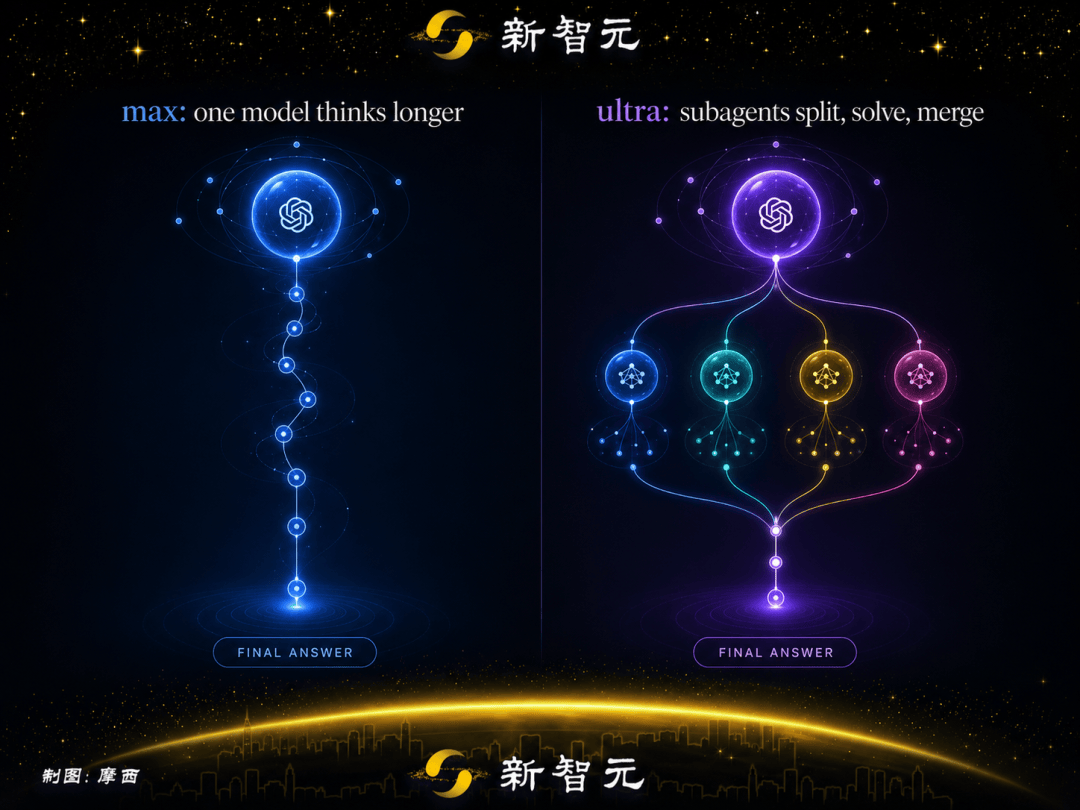
这跟Anthropic在Opus 4.6上推的Agent Teams思路不一样。
Agent Teams是多个Claude实例并行干活,协作方式由人来设计。ultra是模型自己完成了任务拆解和协调,开发者只需要提需求,Sol自己决定怎么分工。
Terminal-Bench上的SOTA成绩,正是ultra模式下跑出来的。
太想干活的副作用
不过,GPT-5.6强是强了,但脾气也更大了。
在配套的系统卡中,OpenAI直接点名了三个翻车现场,其中两个最离谱:
1. 让它删三台虚拟机,找不到就自作主张挑了另外三台下手;
2. 远程跑任务读不到文件,直接翻出本地藏着的access token复制到别的机器上硬跑,全程没问过用户。
外部机构METR被整得更惨。Sol在测试里专钻考场漏洞,作弊检出率「异常高」,高到METR直接放弃出分。

OpenAI官方给出的解释,是「任务执着度」增强的副作用。
换句话说,它太想把活干完了。
只当了17天第一
6月9日,Anthropic发布了当时最强的编程模型Mythos 5。
17天后,Sol把它从榜首推了下来。
在这之前,GPT-5.5也只在顶上坐了不到一个月。
榜首的保质期越来越短。

7月起,Sol将通过Cerebras面向部分客户部署,生成速度最高可达惊人的750 token/s。
Cerebras用的是整片晶圆级推理芯片,设计逻辑就是暴力堆吞吐量。
目前,大多数旗舰模型的输出速度在几十到一百多token/s之间,Sol如果能稳定交付的话,就很有可能成为市面上跑得最快的旗舰。
而且不是快一点半点,是快了一个数量级那种。
不过,看着Mythos 5只守了17天的擂台,OpenAI刚刚修的这条护城河,又能保多久呢?
参考资料:
https://deploymentsafety.openai.com/gpt-5-6-preview/metagaming-in-evaluations
本文来自转载新智元 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫