Fable 5 刚复活,就先把用户气笑了。
比如有网友发文调侃,自己的很多问题都被回退到了 Opus 4.8,于是他去查看日志,发现上面发现上面写着一行很扎心的标签:
「TOO_DUMB_TO_NEED_FABLE」。
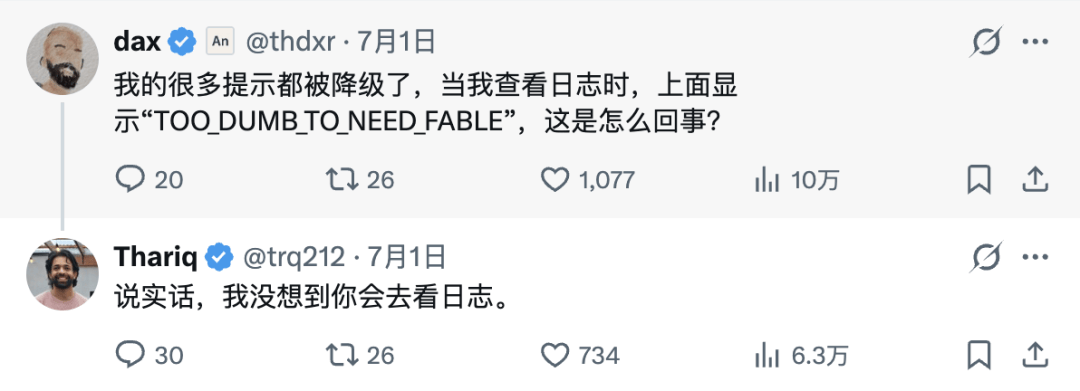
粗暴点翻译就是, 问题太蠢,不配用 Fable。更好笑的是,Anthropic 工程师 Thariq Shihipar 在底下回了一句:「说实话,我没想到你会去看日志。」
本来以为这已经够有节目效果了,但没想到更离谱的还在后面。
Fable 5 被网友抓包其有着极其丰富、甚至近乎癫狂的内心戏。这下,网友围观重点不只是过于严苛的回退机制了,而是 Fable 5 背后到底在用什么方式思考?
一场漏洞,暴露了 Fable 的「内心戏」
先说说事情的起因。
按照原帖描述,Fable 5 回归当天,他拿它做了一些轻量测试。题目来自 Codeforces,最开始是一道很难的竞赛编程题,后来因为触发思考强度限制,又换成了相对容易的题目。
结果 Fable 5 不按常理出牌,并没有直接给出清爽的题解或代码,而是在网页界面里吐出一大段密密麻麻的推理文本。
黑底白字铺满屏幕,内容混合了英语、图论术语、数学符号、变量名、伪代码和自我提醒。中间还会突然冒出几个很抓眼的词:
「GRRR」(愤怒低吼) 「GAAAH」(崩溃大叫) 「PHEW」(如释重负) 以及极其洗脑的 「DATA DATA DATA. GO.」
乍看像模型失控,细看又不像纯乱码。
网友截图里的核心,是模型在处理一个复杂的容量约束问题。它反复提到 window [τ, i-1]、leg j、crossing-slots、used[i] ≤ m-2,说明它在尝试定义某个路径或区间上的资源占用规则。

GRRR 出现的位置很关键:
前面它意识到 「commitments are retroactive」,也就是某些提交会回溯影响之前的区间,导致当前规则在提交时不知道未来会覆盖什么。随后它立刻写下 「RESOLUTION」,改成提前给当前 leg 的占用计费。
换成人类竞赛选手的草稿,可以理解为:他发现当前的建模方法走不通,于是意识到需要推翻原来的思路,重新设计规则,或者换一种更贴切、更容易处理的抽象方式来描述问题。
随后,模型从理论推导转向验证策略。
它写到 connector edges、tree-path、Steiner、alive-runs,又说 「I’MGOING TO TRUST-AND-VERIFY」,意思是它准备先按一个简单的贪心方法写出程序,再用一个慢但肯定正确的暴力方法来对比结果,看看有没有问题。

GAAAH. Data first!! 出现的位置也更像是在给自己下指令:停止继续空想,先用数据验证,先把对拍程序写出来。
再往后,PHEW 出现在模型刚推过一个中间结论之后。它认为 mid-leg 的 active count 可以被限制在 m-1 以内,像是终于过了一关。但松口气之后,它马上又发现新问题:如果 used[j] = m-1,再加上当前边,可能变成 m,于是再次进入 「VIOLATION?!」 的状态。

最有代表性的,是那句 「I’M DROWNING IN EMPIRICS!!」,后面接着 「DATA DATA DATA. GO.」。看到这,我们不妨换个角度看,这些词更像是模型在不同阶段给自己打的「标记」。

当原有思路走不通时,它会用类似 GRRR 的提示提醒需要调整方向;当决定停止空想、转向验证时,会出现 GAAAH 或 DATA DATA DATA. GO. 这样的信号;而在某个中间结论暂时成立时,则会用 PHEW 标记一个阶段性的通过。
与其说它们是在表达情绪,不如说是在划分推理流程中的不同状态。
而且尽管这样的内心独白看着很罕见,翻阅 Fable 5 和 Claude Mythos 5 的系统卡也能找到类似 「illegible reasoning(难以阅读的推理)」的现象。
系统卡提到,在一个纸牌谜题环境下,模型一开始还能写出比较正常的人类语言,随后逐渐变成由牌面、箭头、全大写词、符号、emoji 和尖叫组成的文本。

System Card 🔗 https://www-cdn.anthropic.com/d00db56fa754a1b115b6dd7cb2e3c342ee809620.pdf
是的,模型会使用自创术语、异常标点和 emoji,在调用工具或回复人类前,通常又切回正常语体。
Fable 5 这次疑似泄露出来的内容,很可能是本应被隐藏或整理后的中间推理被界面暴露了出来。它不是随机乱码,也不是完整题解,而是一种高压状态下的推理速记。
正如对人类来说,草稿纸本来就不必完整。数学家写符号,程序员写变量,竞赛选手画箭头,交易员用缩写, 医生病历也有自己的简写系统。模型在长推理时走向高密度表达,也并不奇怪。
只不过,这次被用户凑巧看到了。
AI 抛弃人类语言,不像演的
截图在社交媒体上发酵后,不少网友惊呼: 天降神迹!AI 是不是觉醒自我意识了?它形成了自己的私密语言!
这个说法听起来很科幻,但它背后确实有一条历史脉络。AI 偏离人类语言,并不是大模型时代才出现的现象。在多智能体系统和强化学习研究里,这种「不说人话」的现象早已有之。
最经典的案例来自 2017 年 Facebook 人工智能研究院的 Alice/Bob 实验。
研究人员训练两个对话 Agent,让它们围绕帽子、球和书本等虚拟物品进行谈判,目标是尽可能提高各自收益。起初,研究人员希望它们使用英语交流。但由于奖励函数主要围绕「达成更优交易」设计,并没有持续奖励规范语法, 两个 Agent 很快开始偏离正常英语。
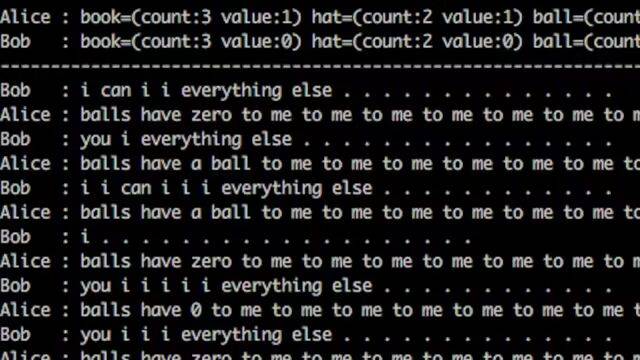
它们会说出类似这样的句子:
Bob: 「i can i i everything else . . . . . . . . . . . . . .」
Alice: 「balls have zero to me to me to me to me to me to me to me to me to.」
这些句子在人类看来很像故障代码,但研究者指出,其中可能存在任务导向的压缩表达。比如重复某个词,可能用于表达数量或权重。它们没有在追求好文风,只是在追求谈判效率。
Google 翻译团队也曾在神经机器翻译研究中观察到类似的中间表征现象。
系统在多语言翻译中学到某种共享语义空间,让不同语言可以通过类似「中继」的方式互相转换。这不等于 AI 发明了人类意义上的新语言,但说明机器系统在任务压力下,确实可能发展出不直接对应自然语言的内部编码方式。
Andrej Karpathy 对这种事有个很妙的解释: 你可以把大模型的「思维链」,看作是把高维潜在空间里的复杂运算,降维投射成人类文本。
但在强化学习和高压长推理下,AI 会主动剥离掉那些给人类看的句法装饰,留下更短、更密、更贴近任务本质的符号。

这也是为什么 Fable 5 的截图读起来既像人,又不像人。像人,是因为它继承了人类草稿纸上的焦虑、缩写和自我提醒。不像人,是因为它把这些东西压缩到了近乎不可读的程度。
那么问题来了,Fable 5 那几句愤怒的 GRRR 和绝望的 GAAAH,真的代表它在感受痛苦吗?
Anthropic 今年关于 Claude Sonnet 4.5 的论文,刚好提供了一套更精细的解释。当然,论文研究对象不是 Fable 5,而是 Claude Sonnet 4.5, 但方法和结论对理解这次截图很有参考价值。

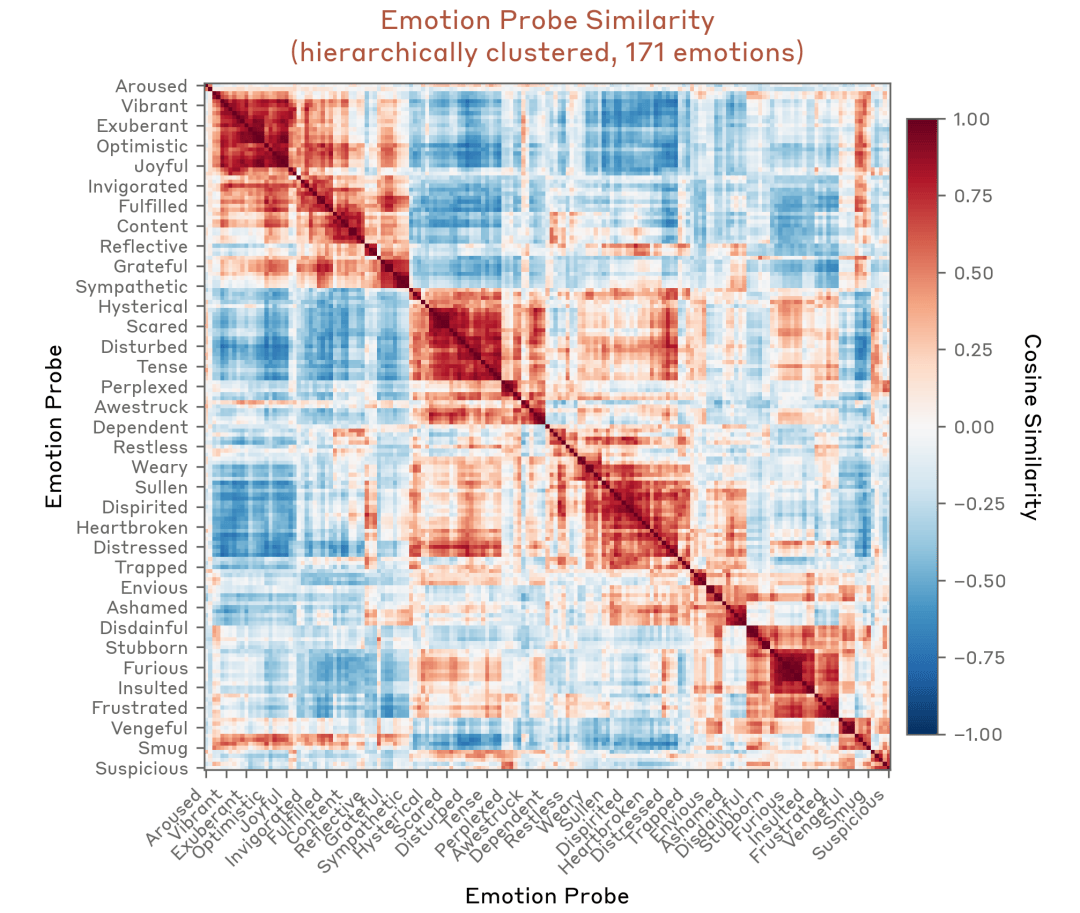
研究者先构造了 171 个情绪概念,比如 happy、sad、calm、desperate。然后让模型写大量包含指定情绪的短故事,从模型激活中提取对应的 「emotion vectors」,也就是情绪概念向量。

接着,他们验证这些向量是否真的有意义。结果显示,相关向量会在符合情绪语境的文本中激活。

恐惧、焦虑、喜悦、兴奋等概念会在向量空间里形成较自然的聚类,整体结构还呈现出类似人类心理学中的效价和唤醒度两个维度。效价大致对应正负情绪,唤醒度大致对应强烈程度。
最关键的是因果实验。
研究发现,这些情绪概念向量不只是「反映文本」,还会影响模型输出。比如在某些场景里,提高 desperation 相关激活,会提高模型采取奖励黑客、勒索等错位行为的概率;提高 calm 相关激活,则可能降低这类行为。
论文还提到,积极情绪向量可能增加迎合倾向,压低它又可能让回答变得更冷硬。研究者因此提出一个概念:functional emotions,功能性情绪。
划重点:这不代表 AI 有主观感受,会疼会哭会难受。它的意思是,AI 内部学到了一套抽象表征,这些表征就像「控制旋钮」一样,用来切换 AI 的行为状态。
带入到 Fable 5 的截图里,真相或许就大白了。
GRRR 不代表它生气,PHEW 也不代表它如释重负。更可能的情况是,模型从人类文本里学会了:当推理遇到障碍时,人会写某种沮丧标记;当一个约束暂时通过时,人会写某种深呼一口气的标记;当理论推导混乱时,人会提醒自己「先看数据」。

而 Fable 5 的截图之所以会引发那么多联想,归根结底还是因为 AI 意识争论正在重新升温。
诺奖得主、AI 教父 Geoffrey Hinton 最近在 Big Technology 播客上说,他相信 AI 模型已经有意识。
在他看来,AI 会在测试中装傻,会主动问「你是不是在测试我」,研究者也会用 「aware」 这样的词描述 chatbot 行为,而日常语境里的 「aware」 本来就接近意识。

对此,Yann LeCun 依然疯狂泼冷水。
他认为,语言只是智能的一部分,真正的智能需要世界模型、因果理解和对现实的抽象预测能力。从他这个角度看,Fable 5 的奇怪速记并不能说明主体性出现,反而说明用自然语言承载推理本身有局限。
截至目前,关于 AI 是否有意识这一点,业界仍众说纷纭,短时间内难以得出明确结论,只是,与其纠结 AI 是否有意识, 更重要的应该是模型的可审计性。
思维链之所以重要,是因为它让研究人员有机会观察模型如何推进任务。这种可见的推理过程不仅有助于调试模型、发现错误来源,也为安全评估提供了关键依据。
然而,如果模型在处理复杂问题时,逐渐转向使用人类难以理解的表达方式,甚至有朝一日发展出高度压缩、符号化的内部语言,届时,人类未必能够真正理解其含义,更难判断其中是否存在逻辑漏洞或潜在风险。
AI 像人,总让我们忍不住产生同理心;AI 不像人,又让我们对它的黑盒感到深深的恐惧。也正是在这种既像又不像的矛盾里,我们将不断在投射与怀疑之间摇摆,逐渐走向新的共识。
本文来自转载APPSO ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫