今天,我们为
/usage命令推出了一项全新更新,旨在帮助你更清晰地了解自己在 Claude Code 中的使用情况。这个决定的背后,是我们近期与用户进行的多次深入交流。
在这些交流中,我们反复听到了一个现象:大家在管理会话时的习惯可谓是五花八门。尤其是最近 Claude Code 将上下文窗口(Context Window)升级到了 100 万大关,这种差异就更明显了。
你是习惯在终端里只保持一两个开着的会话?还是每次输入提示词都重新开个新会话?你通常在什么时候会用到压缩(Compact)、回溯(Rewind)或者子智能体(Subagents)?又是什么原因导致了一次糟糕的压缩呢?
这里头其实大有学问。这些看似不起眼的细节,极大地影响着你使用 Claude Code 的体验。而这一切的核心,都归结于一件事:如何管理你的上下文窗口。
快速科普:上下文、上下文压缩与上下文衰减
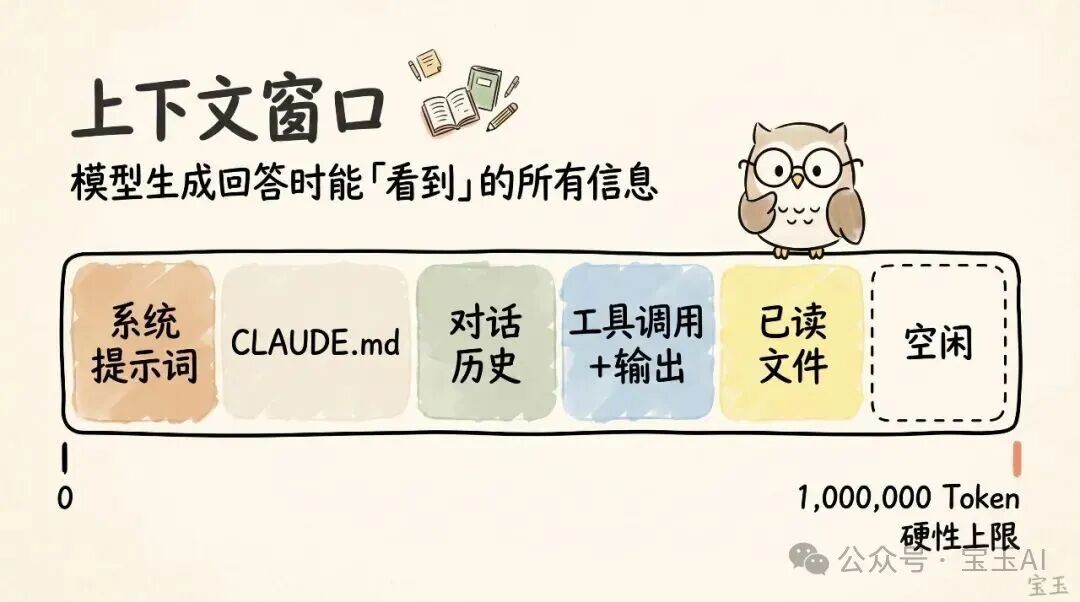
所谓「上下文窗口(Context Window)」,就好比模型在生成下一次回答时,眼前能同时「看到」的所有信息。它包括了你的系统提示词(System Prompt)、到目前为止的聊天记录、每一次的工具调用(Tool Call)及其输出结果,甚至还有它读过的每一个文件。现在,Claude Code 拥有高达 100 万个词元(Token) 的超大上下文窗口。
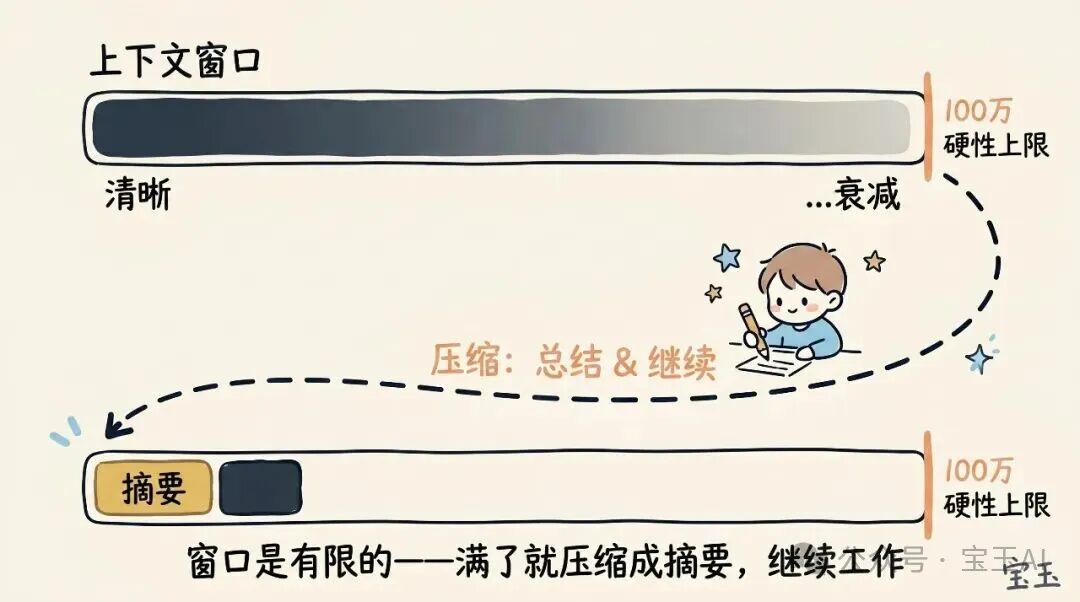
但遗憾的是,使用上下文是需要付出一点代价的,我们通常称之为上下文衰减(Context Rot)。随着上下文越来越长,模型的表现往往会变差,这是因为它的注意力被分散到了更多的 Token 上。那些早期遗留的、已经无关紧要的内容,会开始干扰模型当前正在执行的任务。
上下文窗口是有硬性容量上限的。所以,当你快要把窗口撑满时,你必须把你正在做的任务总结成一段简短的描述,然后带着这段描述在一个新的上下文窗口里继续工作。我们把这个过程称为上下文压缩(Compaction)。当然,你也可以随时手动触发这个压缩过程。
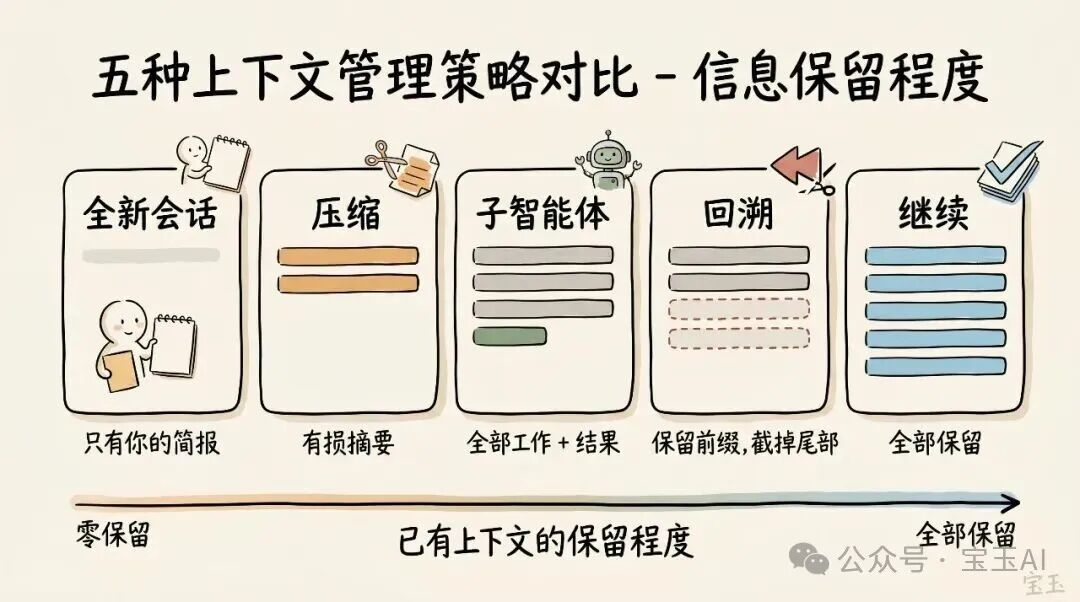
每一次回合,都是一个分叉路口
想象一下,你刚刚让 Claude 帮你做了一件事,并且它已经完成了。现在,你的上下文里已经塞进了一些信息(比如工具调用、工具的输出结果、你给的指令)。接下来该怎么做?你可能会惊讶地发现,自己竟然有这么多种选择:
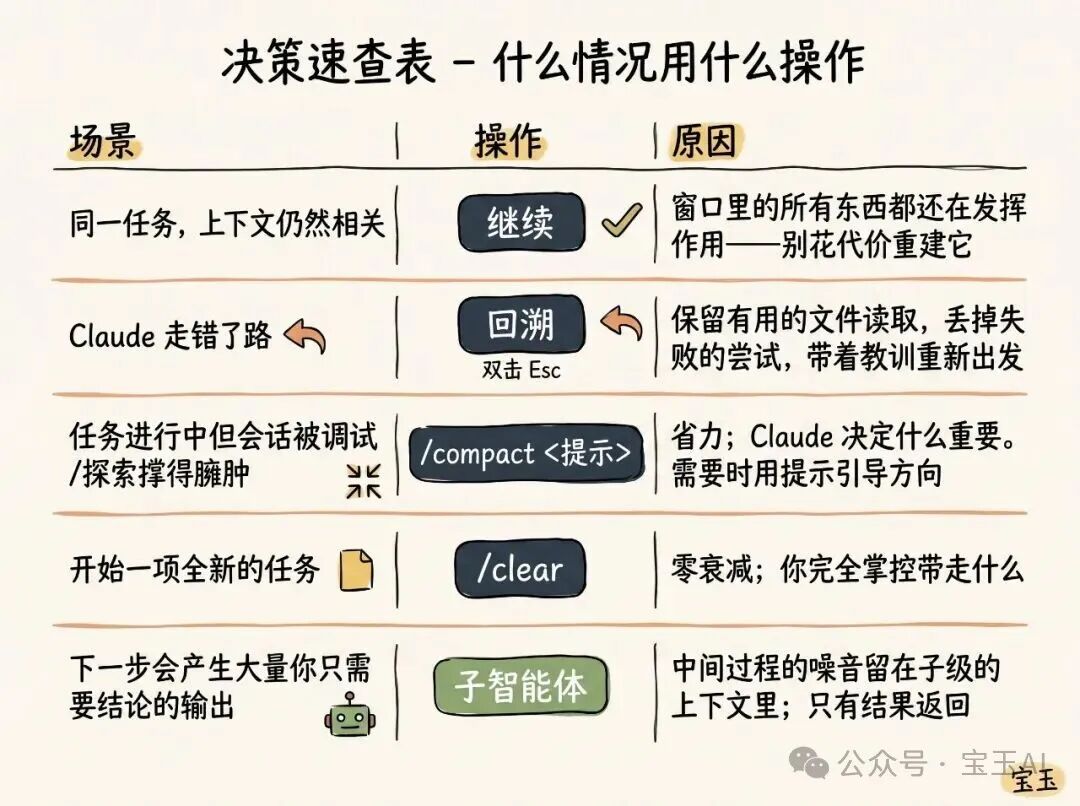
- 继续(Continue) — 在同一个会话里,直接发送下一条消息
- 回溯(/rewind 或连按两次 Esc 键) — 时光倒流,退回到之前的一条消息,从那里重新开始尝试
- 清空(/clear) — 开启一个全新的会话,通常带上你从刚才对话中提炼出的简短总结
- 压缩(Compact) — 把目前的对话做个总结,然后在这个总结的基础上继续干活
- 子智能体(Subagents) — 把下一阶段的工作委派给另一个拥有自己干净上下文的 AI 智能体(AI Agent),并且只把它最终的工作结果拉取回来
虽然直接「继续」是最顺理成章的反应,但其他四个选项的设定,正是为了帮你更好地管理你的上下文。
什么时候该开个新会话?
到底什么时候该维持一个漫长的老会话,什么时候又该另起炉灶呢?我们的经验法则是:当你开始一项新任务时,你也应该开启一个新会话。
100 万的上下文窗口,意味着你现在可以非常靠谱地完成更长、更复杂的任务。比如,让 Claude 从零开始为你搭建一个全栈应用。
但有时候,你可能在做一些前后关联的任务。这时候,你需要保留一部分之前的上下文,但不是全部。举个例子,你刚写完一个新功能,现在要为它写一份使用文档。你当然可以开个新会话,但这意味着 Claude 必须把你刚才写过的所有代码文件重新读一遍——这不仅速度更慢,而且花费也更高。

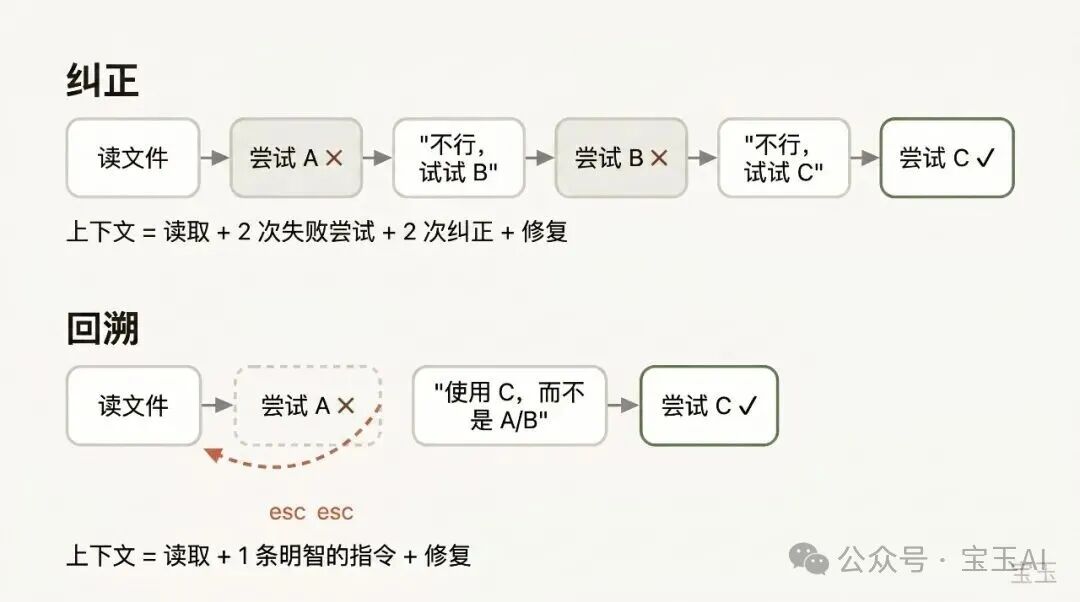
用「回溯」代替「纠正」
如果非要我挑出一个能代表「优秀上下文管理能力」的好习惯,那一定是用好「回溯(Rewind)」。
在 Claude Code 里,双击 Esc 键(或者运行 /rewind 命令)能让你穿越回之前的任意一条消息,然后从那里重新下发提示词。至于那个节点之后发生的所有对话,都会被从上下文中彻底抛弃。
在纠正 AI 的错误时,「回溯」往往是更高明的做法。举个例子:Claude 读了五个文件,尝试了一种方法,结果失败了。你的本能反应可能是在对话框里敲下:「这招不管用,换 X 方法试试。」但更聪明的做法是,回溯到它刚读完那五个文件的时刻,然后带着你刚学到的教训重新对它说:「别用 A 方法了,foo 模块根本不支持那个——直接去试 B 方法。」
你甚至可以使用「从这里开始总结(summarize from here)」的功能,让 Claude 自己把它学到的教训总结成一段「交接信息」。这感觉就像是那个刚刚踩了坑的「未来版 Claude」,给过去那个还没开始行动的自己留下了一张字条。
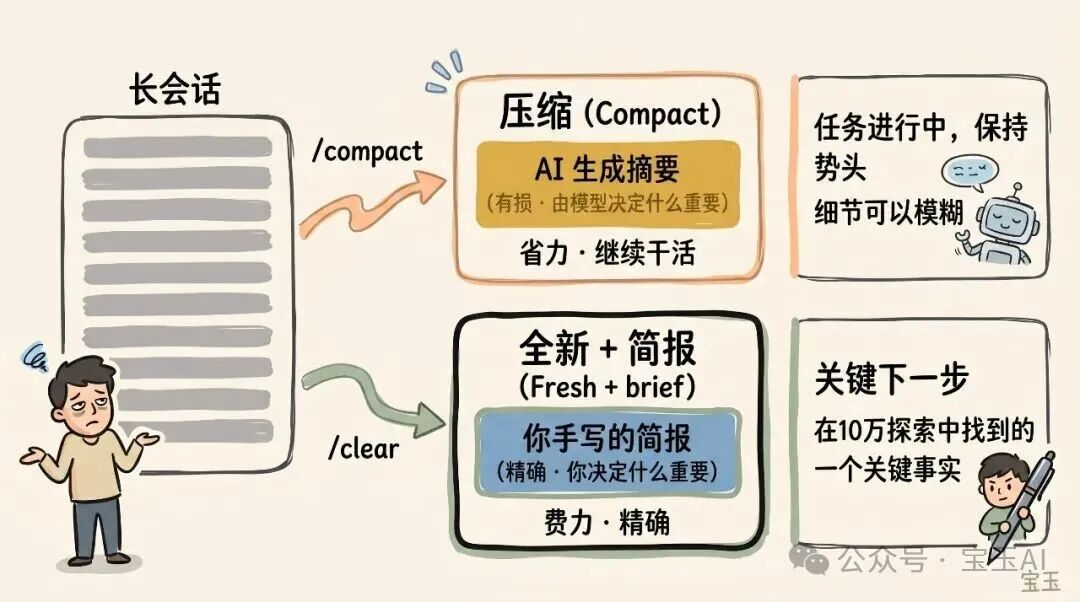
上下文压缩 VS 全新会话
当一个会话变得越来越长时,你有两种方法可以给它「减负」:使用 /compact(压缩)或者 /clear(清空并从头开始)。这两个操作听起来挺像,但实际表现大相径庭。
压缩(Compact) 是让模型把到目前为止的对话总结一下,然后用这份摘要替换掉冗长的历史记录。这个过程是「有损」的,意味着你把决定「什么内容重要」的权力交给了 Claude。好处是你什么都不用写,而且 Claude 在保留重要的经验教训或文件记录时,可能比你想得更周到。你也可以通过给它下达指令来掌控压缩的方向(比如:/compact 将重点放在身份验证模块的重构上,丢掉那些关于测试调试的内容)。
而使用 /clear,则需要你自己写下核心要点(例如:「我们正在重构身份验证的中间件,目前的限制条件是 X,相关的重要文件是 A 和 B,而且我们已经排除了方法 Y」),然后以一个无比干净的状态重新开始。虽然这要费点劲,但由此产生的新上下文,百分百都是你认为真正相关的精华。
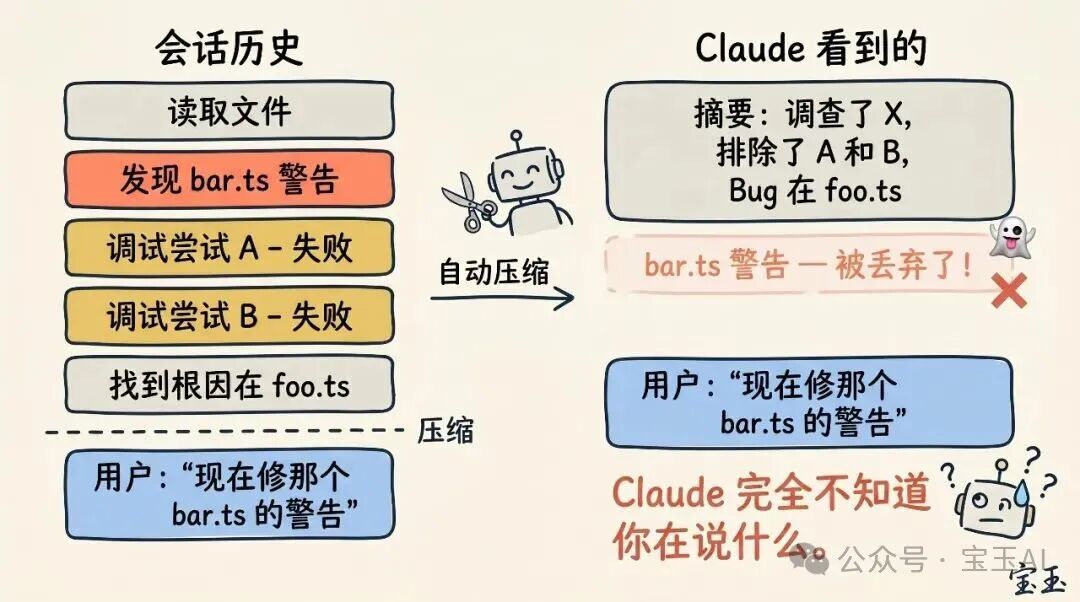
什么样的「压缩」会翻车?
如果你经常挂着超长的会话,你大概率遇到过「压缩」效果极其糟糕的情况。我们发现,这种「翻车」通常发生在一个特定的时刻:那就是大语言模型(LLM)无法预测你下一步工作方向的时候。
举个例子,在一段漫长的代码调试之后,系统触发了自动压缩,把之前的排查过程总结了一番。结果你紧接着发了一句:「现在,把我们之前在 bar.ts 里看到的另一个警告也修了吧。」
可是,由于刚才的会话重点全在调试前一个 Bug 上,那个没来得及修的警告很可能早就被当成无关紧要的信息,在总结时被直接丢弃了。
这是一个相当棘手的问题。因为受限于上下文衰减,模型在进行压缩的那一刻,往往是它「智商」最不在线的时候。好在有了 100 万的上下文容量,你现在有了更充裕的空间,可以主动带上「我接下来想做什么」的描述,去提前执行 /compact。
子智能体与全新的上下文窗口
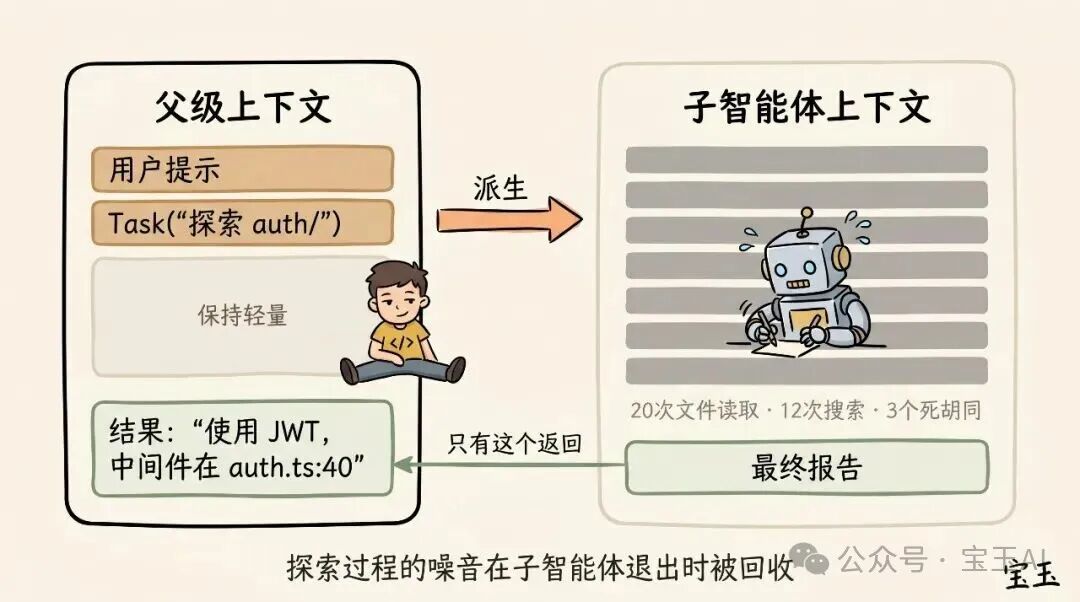
子智能体也是一种管理上下文的绝佳手段。当你提前预知某一项工作会产生大量「阅后即焚」(以后再也用不上)的中间结果时,这招特别管用。
当 Claude 通过智能体工具(Agent tool)衍生出一个子智能体时,这个小家伙会获得一个完全崭新的上下文窗口。它可以在里面肆意折腾,做多少工作都行。等到大功告成,它会把结果提炼出来,只把最终的报告交还给「父级」Claude。
我们判断是否该用子智能体的「灵魂拷问」是:以后我还需要看这些工具运行的详细输出吗,还是我只想要一个最终结论?
虽然 Claude Code 会在背后自动调用子智能体,但有时候你也可以非常明确地指挥它。比如,你可以对它说:
- 「派个子智能体去,根据下面这份规范文件,验证一下我们刚才做的工作对不对」
- 「派个子智能体去通读一下另一个代码库,总结出它是怎么实现身份验证流程的,然后你自己照猫画虎,在这边也实现一遍」
- 「派个子智能体去,根据我的 Git 修改记录,给这个新功能写份说明文档」
总结
总而言之,当 Claude 完成了一轮回答,而你正准备发送一条新消息时,你就站在了一个决策的路口。
我们期望在未来,Claude 能足够聪明,自己帮你打理好这一切。但就目前而言,熟练掌握这些决策,正是你引导 Claude 产出高质量结果的必经之路。
本文来自转载微信公众号“宝玉AI” ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫