每次发本地部署相关的内容,评论区都会吵起来。
有人说 Mac Mini 好,有人说必须上塔式机。
吵来吵去,永远没有结论。
双方各执一词,谁都觉得自己对,谁都觉得对面在说外行话。
原因我大概知道。
多数人把「大模型」和「DeepSeek 聊天」画了等号。觉得本地部署就是在自己电脑上跑一个聊天机器人。
不是的。
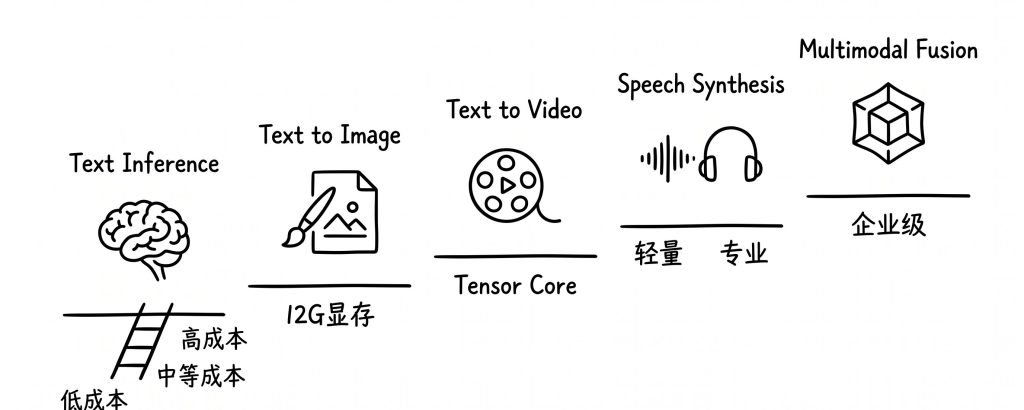
2026 年的大模型已经分化成五个完全不同的类型。每个类型对硬件的要求天差地别。拿同一套标准去争论谁的设备更好,这件事本身就不成立。
五类模型和硬件门槛,一次讲清
先说模型
第一类,文本推理模型。 大家最熟悉的那种。聊天、写代码、翻译、文档处理都靠它。国内有 DeepSeek、Qwen、GLM,国外有 Llama、Mistral、Gemma。这是本地部署里数量最多的一类。也是硬件跨度最大的一类。几千块的洋垃圾到几万块的专业设备都能跑,差别在参数量和上下文长度。评论区多数争论,说的就是这一类。
第二类,文生图模型。 Stable Diffusion、FLUX 这些。门槛比文本推理高一档,主要吃显存。一张 12G 显存的卡基本够用。
第三类,文生视频模型。 2026 年个人部署门槛最高的类型。逐帧生成加帧间连贯性优化,对显卡 Tensor Core 要求很高。老卡基本跑不动。
第四类,语音合成模型。 门槛分两档。轻量 TTS 个人电脑就能跑。专业级声音克隆对 CPU 和大内存有额外要求。
第五类,多模态融合模型。 同时处理文字、图片、音频。硬件门槛最高,目前多数要企业级配置才能流畅运行。
再说硬件
不同类型的模型,对硬件的需求逻辑完全不同。
硬件门槛取决于三个变量。参数规模,计算精度,任务类型。
文本推理是逐 token 生成的。单次计算量不大,核心瓶颈在显存容量,不在算力爆发。所以几年前的 Tesla V100 16G 都能跑。2026 年 MoE 架构和线性注意力优化又进一步降低了门槛。参数量决定内存需求,但只要内存撑得住,量化技术可以进一步压缩。
洋垃圾能跑得很顺,道理在这。
文生视频是逐帧生成的。单次计算量是文本推理的几十倍甚至上百倍。需要现代 GPU 的 Tensor Core 做帧间融合。V100 这类老卡 Tensor Core 性能不够,强行部署会出现帧断裂和色彩失真,没有实用价值。
所以有人说必须上 4090 或 5090。
两边都没说错。只是在讨论不同类型的模型。
我桌上放的是一台 MAX 395
说说我自己的情况。
我的主要用途是文本推理。跑 Qwen3.5 35B,接入自己的数据库做数据清洗,还用它翻了 1500 页的内容。
桌上放的是一台 MAX 395 mini PC。
因为它匹配我的需求。
文本推理吃的是内存,不是瞬时算力。MAX 395 跑 35B 参数的模型完全够用,正常来说跑gpt 120B都ok。体积小,功耗低,24 小时挂着跑任务不心疼电费。
数据清洗的流程也简单,模型接数据库,读原始数据,按规则清洗,写回。这种重复性高、数据敏感的任务,放本地比调 API 省钱,数据也不出本机。
不需要复杂配置,不需要多卡协同。一台 mini PC 放在桌角,安安静静把活干了。
如果哪天我的需求变成文生视频,MAX 395 肯定不够。会去配一台带 4090 或 5090 的塔式机。但目前不需要。
设备跟着需求走。不跟着参数走。
什么人不需要本地部署
没有明确的、持续的、高频的使用场景,就不需要。
在线 API 能解决的事,不用折腾。写文档、做计划、日常对话,云端版本完全够用。
只是好奇想试试的,更不需要。配完机器大概率用几次就闲置了。硬件投入是一次性的,但学习成本和维护成本是持续的。
本地部署真正有价值的场景在于数据敏感不能出本机,或者调用量大 API 费用扛不住。再就是需要 24 小时不间断跑任务的。
至少占一条,再考虑。
当然如果有闲钱,想玩一玩,也没有问题,
配置是手段,不是目的。能给你省时间或省钱,才值得投入。
你目前是哪种情况?
A. 已经在跑本地部署,想优化配置 B. 在考虑,还没想好部署什么 C. 纯好奇,先看看 D. 云端 API 够用,不打算折腾
评论区说。
本文来自转载 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫