4月22日,蚂蚁百灵正式推出Ling-2.6-flash Instruct模型。该模型总参数量为104B,激活参数仅7.4B,核心主打高“Token 效率(Token Efficiency)”,围绕更快推理、更低消耗、更易规模化落地打造,面向智能体(Agent)场景完成专项能力强化,旨在为AI 应用场景提供一种更优的“智能表现”与“成本平衡”方案,推动AI Agent大规模落地。
随着AI Agent步入规模化落地阶段,Token消耗的激增正成为制约大模型应用普及的关键瓶颈。相较于普通对话,Agent任务输入长度大幅提升,叠加多轮工具调用、长程规划执行,显著推高推理算力与使用成本。值得注意的是,行业内主流模型多选择通过“长思考”以更长的推理过程换取更高的任务上限,这一方式反而进一步加剧了资源消耗。
面对持续攀升的Token压力,Ling-2.6-flash选择了一条差异化技术路径:它没有单纯依赖更长输出换取更高分数,而是围绕推理效率、Token效率与Agent场景表现进行系统性优化,力求在保持竞争力智能水平的同时,尽可能做到更快、更省、更适合真实业务场景,精准破解行业落地痛点。
具体来看,Ling-2.6-flash的核心能力集中体现在三个方面:
·其一,采用混合线性架构,释放推理效率:Ling-2.6-flash沿用了Ling 2.5的混合线性架构设计,模型从底层优化计算效率,这种高度稀疏化的MoE架构在硬件表现上优势显著。在4卡H20条件下,其推理速度最快可达到340 tokens/s,Prefill吞吐更是达到Nemotron-3-Super的2.2倍。以更高的“费效比”完成任务。
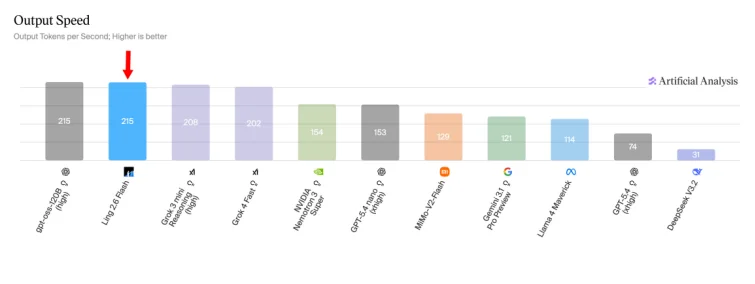
此外,在Output Speed 测评中,Ling-2.6-flash以215 tokens/s的稳定输出速度位列同参数级别模型的第一梯队。
·其二,聚焦Token 效率优化,显著提升智效比:在模型训练过程中,对Token效率进行了针对性校准,力求以更精简的输出完成既定目标。同时在预训练与推理侧完成大规模算子融合与精度适配,满足不同场景需求,提升推理效率。
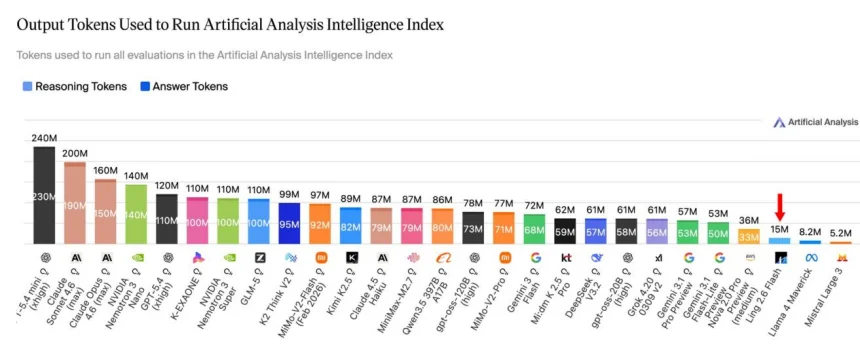
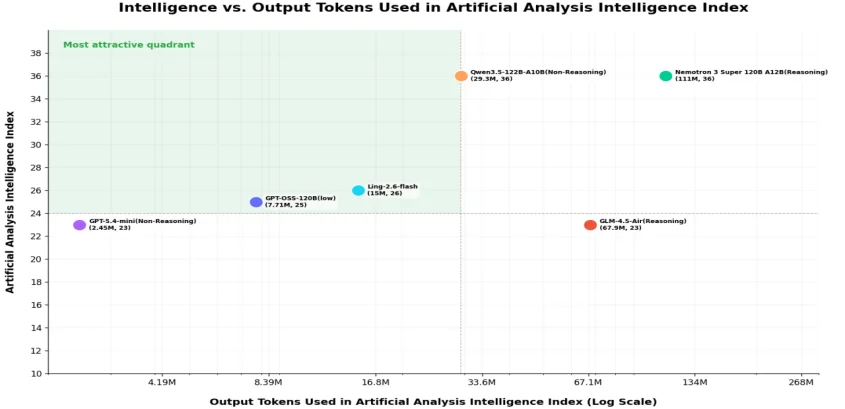
在Artificial Analysis完整测评中,Ling-2.6-flash总消耗15M tokens,而Nemotron-3-Super等模型达到或超过110M tokens。这意味着,Ling-2.6-flash仅用约1/10的token消耗,以更高的“智效比”完成了同类评测任务。
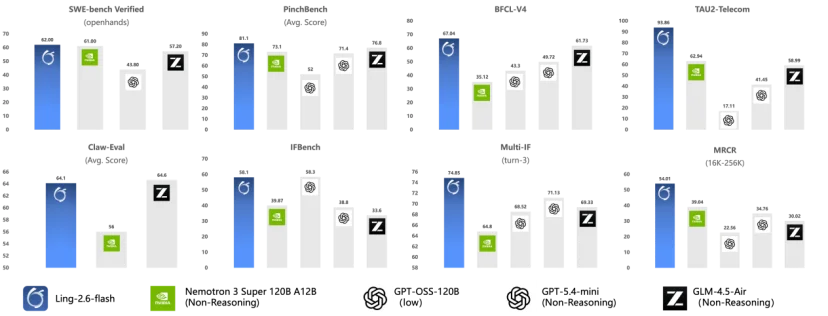
·其三,面向Agent 场景进行定向增强,强化任务执行力:针对当前需求最旺盛的Agent应用,在工具调用、多步规划与任务执行能力上持续打磨,在控制Token消耗的前提下,依然保持了极强的任务执行力,使模型在BFCL-V4、TAU2-bench、SWE-bench Verified、Claw-Eval、PinchBench 等Agent相关基准上达到同尺寸SOTA水平。与此同时,Ling-2.6-flash在通用知识、数学推理、指令遵循及长文本解析等维度保持优秀水准。可广泛适配代码生成、长篇内容创作、复杂信息提取、工作流自动化等各类真实业务场景。
不难看出,Ling-2.6-flash的核心追求并非单点极限能力,而是在控制Token消耗的前提下,持续保持对Agent任务的强竞争力。换句话说,Ling-2.6-flash追求的不是单纯“更强”,而是在“足够强”的基础上,进一步实现“更快、更省、更可落地”,精准匹配行业规模化落地的核心需求。
对于开发者和企业场景而言,这种效率优势意味着更低的推理开销、更快的首字响应、更短的整体生成时延,以及更流畅的交互体验,带来更实用的价值,满足其在真实部署环境下对速度、成本与体验的综合要求。
值得一提的是,此前一周在OpenRouter匿名上线、并成功登顶热度榜的匿名模型 “Elephant Alpha”,如今也正式“破案”,正是Ling-2.6-flash的测试版本。社区的广泛关注和正向反馈也印证市场对高性价比、高Token效率大模型的强烈需求。
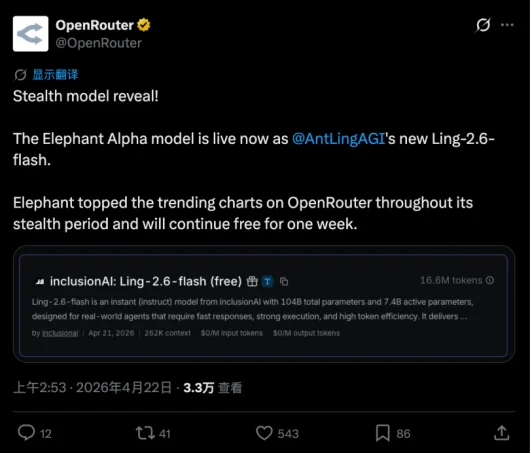
经过一周的持续迭代和优化,Ling-2.6-flash在Agent场景的泛化性和稳定性方面获得了进一步提升。Elephant Alpah测试期间,研发团队收到了来自社区的大量真实反馈,其中,模型的速度优势和Token节省能力,获得了用户的广泛认可。
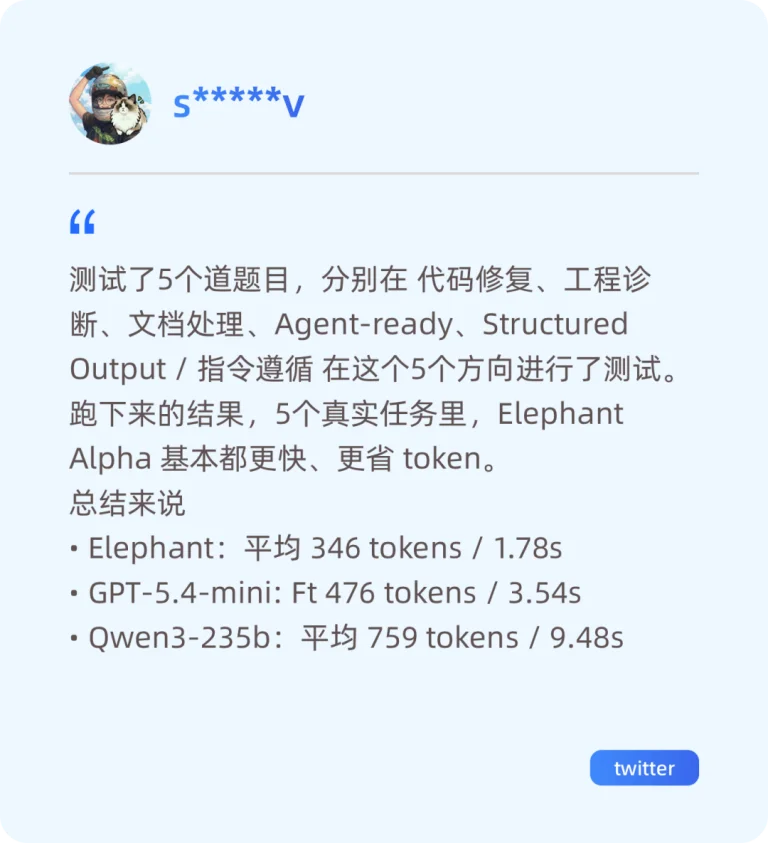
(网友在测试期间的反馈,更快、更省Token)
API定价方面,Ling-2.6-flash输入每百万tokens定价0.1美元,输出 0.3 美元。目前,Ling-2.6-flash API已在OpenRouter及百灵tbox平台上线,同步开放为期一周限时免费试用。用户可以通过OpenRouter、百灵大模型tbox获取对应服务。该模型后续将通过蚂蚁数科发布商业版本LingDT,服务全球开发者及中小企业。据了解,模型的BF16、FP8、INT4等版本也将于近期正式开源,敬请期待。
在AI大模型从技术比拼转向落地竞争的阶段,Ling-2.6-flash这类聚焦Token效率与Agent 实用性的产品,通过技术创新提升“Token效率”,在保证智能水平的前提下,大幅降低应用成本和部署门槛,将有助于推动大模型在真实业务场景中的大规模落地,也为行业在“能力”与“成本”之间的平衡提供了新的参考方向。
本文来自转载51CTO技术栈 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫