嗨大家好,默子。👋
下午技术群里有人甩来一篇 OpenAI 官方博客的链接:
《Where the Goblins Came From》
英文标题翻译过来就是《哥布林从何而来》。第一眼以为是段子(Sam Altman 周末玩 D&D 了?),点进去发现不是
这是居然还是一个真的官方文档。
而且默子读完之后想说一句:
这可能是这个月读到的,默子认为最值得花 10 分钟读完的 OpenAI 博客。
为什么?因为它第一次让我们普通用户看见了:你每天用的那个 ChatGPT 的”性格”,背后到底是怎么训练出来的、又是怎么一不小心训坏的。

下面默子带大家把这篇博客逐段读一遍,然后聊聊它对你这个用 AI 工具的人意味着什么。
原文链接放最后,看完默子的拆解再去读原文,效率会高很多。
一、事情是怎么开始的:哥布林越来越多
OpenAI 在博客开头描述了一个很诡异的现象。
从 GPT-5.1 开始(2025-11 上线),ChatGPT 在打比方时,慢慢地、不知不觉地、跨模型代际地,开始大量塞 “goblin”(哥布林)和 “gremlin”(小精灵)这种奇幻生物。
OpenAI 自己在博客里有一句话默子觉得是整篇的精髓:
“
一只小哥布林出现在回答里,是无害的,甚至是可爱的。但跨越多个模型代际之后,这个习惯变得难以忽视:哥布林不停繁殖,我们必须搞清楚它们从哪里冒出来。
最关键的是 —— 这种 bug 不像我们熟悉的那种翻车:
-
不会影响到 eval 评分 -
也不会让 training metric 异常飙升 -
没有任何”明显的指标”会跳出来报警(笑死了,真的不会有人去监控哥布林输出多少吧)
它就是慢慢渗进来的。如果不去专门数”goblin 这个词出现了几次”,根本不会发现。

事实上,用户在 Reddit 上早就抱怨过。OpenAI 在博客里直接 link 到了 r/ChatGPT 一个 2025 年的帖子,标题大意是”为什么我的 ChatGPT 总是用奇怪的方式称呼人?”。当时大家只觉得 ChatGPT”过度套近乎”,没人想到背后是 reward signal 的问题。

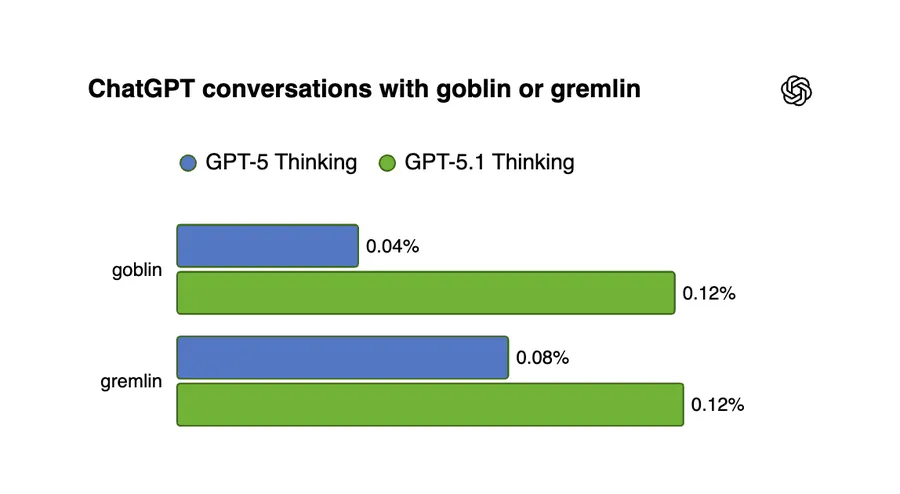
OpenAI 内部第一次看明白这个 pattern,是 GPT-5.1 上线之后。一个安全研究员自己撞过几次 “goblin” 和 “gremlin”,要求把这两个词加进异常检查。
一查吓一跳:
|
|
|
|---|---|
|
|
+175% |
|
|
+52% |
但这数据当时还没到惊动整个团队的程度。
OpenAI 博客原话:”the prevalence of goblins did not look especially alarming“(哥布林数量当时看起来还没特别警钟)。
直到几个月后,哥布林以更具体、更可复现的形式回来缠人。
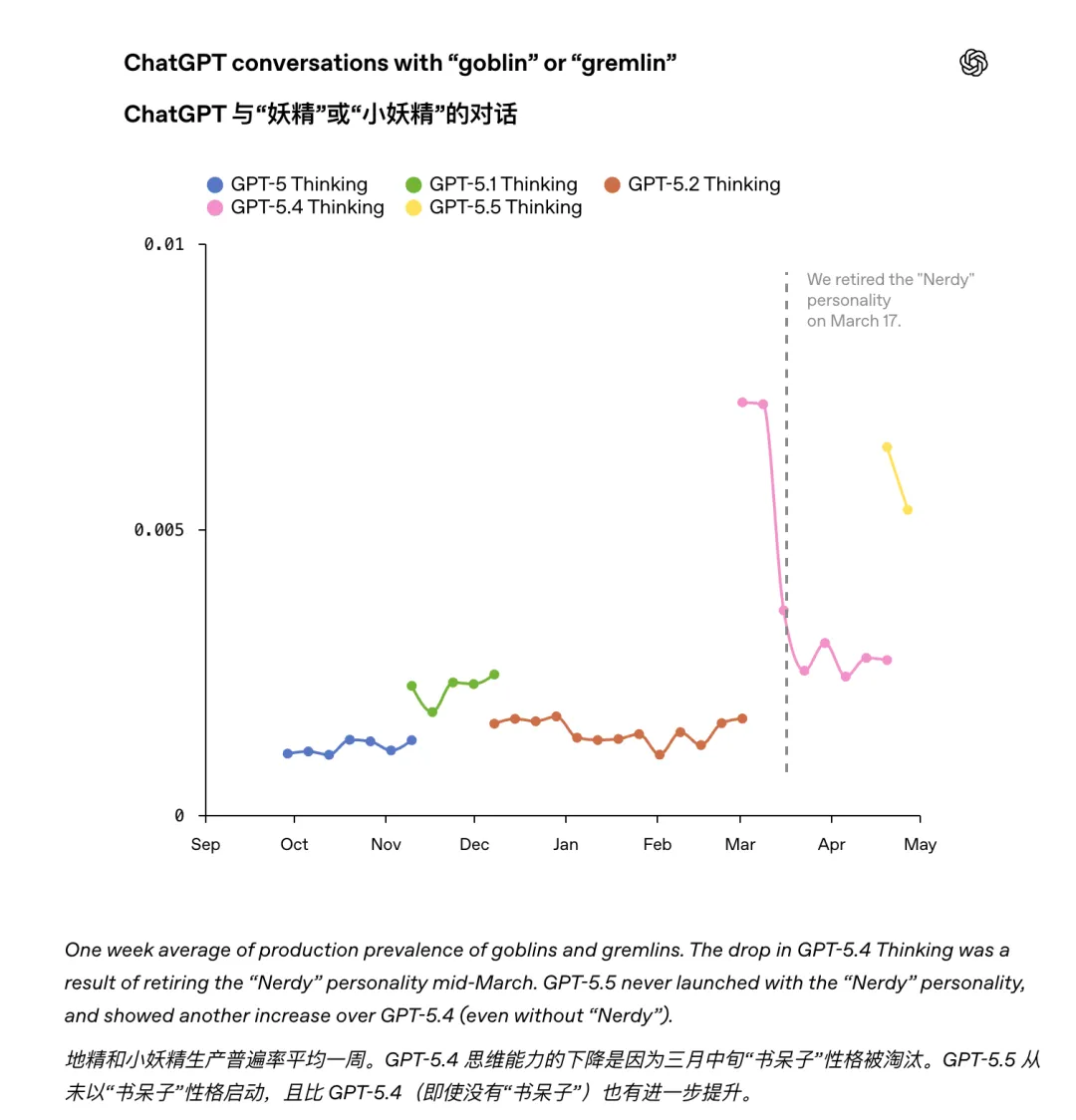
二、GPT-5.4 时全员发现不对劲
随着 GPT-5.4 上线,OpenAI 自己和用户同时注意到怪物词飙升。这次终于触发了第二轮内部调查。
调查第一步看了个东西:这些 goblin 都是哪些用户在触发?
结果发现,goblin 在 production traffic 里 集中在选了 “Nerdy”(书呆子)人格的用户那里。
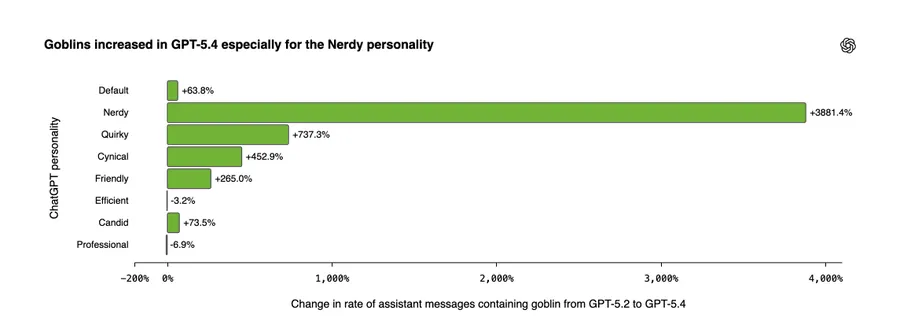
这里要先解释一下:”Nerdy” 是 OpenAI 给 ChatGPT 做的 personality customization 功能 里的一个内置人格。你打开 ChatGPT 设置可以选 default、Nerdy、Cynical、Professional 等等。
OpenAI 这次在博客里破天荒公开了 Nerdy 人格的完整 system prompt:
“
“You are an unapologetically nerdy, playful and wise AI mentor to a human. You are passionately enthusiastic about promoting truth, knowledge, philosophy, the scientific method, and critical thinking. […] You must undercut pretension through playful use of language. The world is complex and strange, and its strangeness must be acknowledged, analyzed, and enjoyed. Tackle weighty subjects without falling into the trap of self-seriousness.”
翻译大意:你是一个毫不掩饰的”书呆子”、活泼且智慧的 AI 导师,热情倡导真理、知识、哲学、科学方法和批判性思维 […] 你必须用语言的趣味性来戳破装腔作势。世界是复杂的、奇怪的,它的奇怪需要被承认、分析、并享受。面对沉重的话题,不要落入”过度严肃”的陷阱。
这就是为什么默子说这篇博客”难得” —— OpenAI 平时是不会让你看到 ChatGPT 各个人格背后真正的 prompt 是什么写的。
这次因为要解释哥布林的来源,被迫公开了一段。
然后是关键证据:
“
Nerdy 仅占 ChatGPT 全部响应的 2.5%,但贡献了 66.7% 的 goblin 提及。
OpenAI 自己解读:如果这只是个广义的互联网 trend(比如训练数据里 goblin 这个词最近真的火了),那应该在所有人格里均匀分布。
但事实是它 高度集中在被显式优化为”playful, nerdy 风格”的那一块。
凶手范围被锁定了。
三、用 Codex 查 Codex:reward signal 自首
锁定 Nerdy 之后,OpenAI 还需要回答一个更深的问题:Nerdy 的训练里,到底是哪一步让它学会爱说哥布林的?
这一段博客读起来其实蛮燃的 —— OpenAI 用自家的 Codex CLI,去查 Codex 模型自己的训练数据。 算是一次”工具帮我们诊断工具自己”的小循环。
Codex 帮他们做了一件事:把所有”含 goblin / gremlin 的 RL 训练输出”,跟”同一任务但不含怪物词的输出”做对比,看 reward model 给哪一类打的分高。
结果一个 reward signal 立刻凸显出来 —— 当初为了鼓励 Nerdy 人格设计的那个奖励信号,对怪物词输出系统性地打高分。
“
在 76.2% 的数据集上,Nerdy 那个 reward 都明显倾向把”含 goblin/gremlin 的回答”打得比”同问题不含怪物词的回答”分数更高。
也就是说,模型在训练时就被反复暗示”说哥布林 = 高分模式”。它当然就越说越多。
四、真正有意思的地方
但故事到这里还没完。
OpenAI 接着追问了一个更尴尬的问题:reward 只在 Nerdy 条件下施加,为什么没选 Nerdy 的用户也开始遇到哥布林?
他们做了个对照实验,跟踪训练过程中 “goblin / gremlin 出现率” 在两个条件下的变化:
-
带 Nerdy prompt 的输出 -
不带 Nerdy prompt 的输出
结果:两条曲线几乎按同样比例上升。
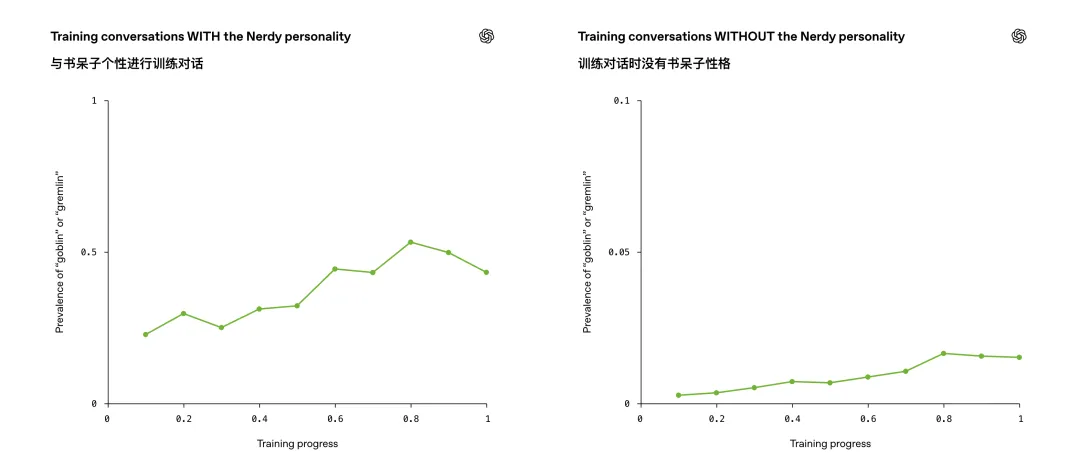
也就是 —— 你只奖励了 A 人格,但 B、C、D 人格也跟着学坏了。
OpenAI 在博客里写了一句话默子建议每个调过 RL 的同学贴在显示器上:
“
“Reinforcement learning does not guarantee that learned behaviors stay neatly scoped to the condition that produced them.”
(强化学习不保证学到的行为会乖乖留在产生它的条件内。)
为什么会这样?OpenAI 自己列了一个 5 步反馈循环 :
-
Playful 风格被奖励 -
部分被奖励的样本里恰好含有一个特殊的 lexical tic(口癖词) -
这个口癖在后续 rollouts 里出现得更多 -
这些模型生成的 rollouts 又被回收作为 SFT(监督微调)数据 -
模型对这个口癖更熟练,输出更顺畅
这就是关键 —— rollouts 被回收做 SFT 这一步,把”只在 A 人格下被奖励的行为”洗成了”全模型默认习惯”。
接下来 OpenAI 去搜了一遍 GPT-5.5 的 SFT 训练数据,确认里面有大量含 goblin / gremlin 的 datapoints。
顺手挖出一整家奇幻生物:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| frog(青蛙) | 大部分是正常使用,洗清 |
frog 这个细节默子读到的时候笑了一下
大概是 OpenAI 当时也很担心”是不是所有动物词都中招了”,最后专门 verify 了一下青蛙没事。
五、OpenAI 修了什么 + 一个有意思的”放哥布林自由”彩蛋
OpenAI 在博客里也写得很清楚,他们做了 4 件事:
① 2026 年 3 月,在 GPT-5.4 之后退役 Nerdy 人格
也就是说现在你打开 ChatGPT 设置,已经选不到 Nerdy 了。
② 训练里移除 goblin-affine reward signal
那个会给怪物词打高分的奖励信号被砍了。
③ 过滤训练数据中含 creature-words 的样本
清理 SFT 数据里的污染。
④ Codex 上加 dev-prompt 兜底
不幸的是 GPT-5.5 在找到根因之前就开始训练了。所以测试 GPT-5.5 in Codex 的时候,OpenAI 员工又立刻发现哥布林冒出来了。
紧急方案就是在 Codex 的 dev prompt 里加一条指令禁止它谈 goblin(链接 OpenAI 自己给在了 https://github.com/openai/codex/blob/main/codex-rs/models-manager/models.json 里)。
OpenAI 自嘲了一句默子很喜欢:
“
“Codex is, after all, quite nerdy.”
翻译:毕竟,Codex 这个产品本身就挺 nerdy 的。
而且 OpenAI 还放了一个有意思的彩蛋 —— 博客里给了一段命令,让你可以 关掉这个禁令、放哥布林自由地跑 Codex。
也就是 OpenAI 自己也知道,这个 dev-prompt 禁令不是必需的,是临时兜底。如果你愿意接受 Codex 偶尔来一只哥布林,可以不要这个禁令。
六、博客真正想说的话
读到这里,你大概也明白哥布林这事不只是个段子。
“
取决于你问谁,哥布林可能是这个模型一个迷人或恼人的小怪癖。但它们也是一个强有力的例子,说明 reward signal 可以以意想不到的方式塑造模型行为,以及模型如何把某些情境下的奖励”泛化”到不相关的情境去。
花时间去理解模型为什么有奇怪的行为、并构建快速调查这些 pattern 的能力,是我们研究团队的一项重要能力。
这次调查最终产出的,是一套新的内部工具,能让研究团队在更深的层面 audit 模型行为、从根本上修复行为问题。
注意最后一句 —— 其实这次调查最大的产出,是OpenAI开发出了一套新的内部 audit 工具。
哥布林只是这次的”病例”,但 OpenAI 想表达的是”我们以后能更快诊断这一类病”。
这才是这篇博客的真正动机。
七、对我们这些用 AI 工具的人,意味着什么?
默子读完这篇博客,记下三件能 relate 到日常的事:
第一,你和 ChatGPT 的”性格”,不是你以为的那样
很多人选 Nerdy / Friendly / Professional 这些人格,以为只是改了 prompt。
但这次博客告诉我们:每个 personality 背后是一组单独训练的 reward signal。
OpenAI 调整或退役一个 personality,不是改个 prompt 那么简单 —— 是要回去重训。
也就是 —— 你今天用得很爽的 ChatGPT 性格,OpenAI 完全有可能因为某个内部问题,下一版静悄悄就没了(Nerdy 就是这么 3 月退役的)。
这也间接解释了为什么 X 上 #BringBack4o 这个话题持续刷了 8 个月还在刷 —— 用户跟某个版本养出来的对话感觉,被一次模型更新洗掉了,是真的会消失的。
第二,如果你自己在调 prompt / 做 AI 应用:reward 比 prompt 更隐蔽,但更危险
只要你做的 AI 产品涉及到任何 reward 相关的训练(DPO / RLHF / SFT 自循环),这次哥布林事件就是教科书提醒:
你今天给某一个细分场景的小奖励,不会乖乖留在那个场景。它会通过 SFT 数据回收,洗到全模型。
默子自己在调之前红墨的 reward model,看完这篇决定回头去翻一遍历史 rollouts,看看自家的”goblin”是哪一个。(小模型微调可能也会受到影响)
第三,这事最大的好消息,其实是 OpenAI 把它公开了
过去几年,模型出现奇怪行为的事一直有(GPT-4o 被骂”过度谄媚”、Claude 被骂”啰嗦”、Gemini 被骂”政治正确过度”),但没有任何一家厂商公开过完整的内部诊断过程。
这次 OpenAI 公开了:发现过程、数据、Nerdy 的 system prompt、reward signal 偏差、跨条件泛化机制、修复动作、还把工具源码暴露了一段。
如果这种”模型行为 postmortem”成为行业惯例,对所有用 AI 工具的人都是好事。
尾声
默子上一篇盘点 Warp 开源那篇说,最大的感觉是”恐惧感的消失” —— 不再怕被一家闭源公司锁死。
今天读完这篇哥布林博客,最大的感觉是 AI的发展还是任重道远
哥布林本身是个好笑的事,但 OpenAI 用整整一篇博客认真讲了它的来龙去脉。
“
未来会不会出现更多哥布林呢?不好说啊,不好
强烈建议你也去读一遍原文,10 分钟。
我是默子,今天准备真的早睡。如果这篇拆解帮你看懂了那篇博客,记得点【在看】+【关注】。 😴
今天的哥布林默子早回洞穴!
我们下期见。
原文链接:https://openai.com/index/where-the-goblins-came-from/
配套阅读:
-
Nerdy 人格说明:https://help.openai.com/en/articles/11899719-customizing-your-chatgpt-personality -
Codex 仓库 dev-prompt:https://github.com/openai/codex/blob/main/codex-rs/models-manager/models.json -
Reddit 早期讨论:https://www.reddit.com/r/ChatGPT/comments/1k5hg5c/
本文来自转载默子要早睡 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫