昨天,Claude Code团队的Thariq发了篇爆文,标题叫:HTML是新的markdown。他说他几乎不再写markdown文件了,转而让Claude Code给他生成HTML。
这篇长文在X上够火的,不到24小时就500万+阅读了,X上很多人立刻分成了两派。一派是markdown党,觉得md格式才是AI时代的源代码;另一派觉得Thariq好像发现了一个了不起的真相,HTML样式确实强多了。
国内我看也有不少科技媒体做了转发和解读。
但……我看完想说……真特么有什么可吵的,你们根本是在争一个蠢问题。
或者说,markdown or html,that is not a question。
在Claude Code团队发文的前一天,其实我还在X上给md格式占了个队。我觉得自然语言才是这个时代真正重要的编程语言,md就是这个时代最好的编程文件。CLAUDE.md、AGENTS.md满天飞,Karpathy的llm-wiki架构也是三层md,连我自己写橙皮书每一章都是先撸md再编译。怎么看,md都像是AI时代的源代码。
但还有个现象是,其实我的Huashu Design完全是在用HTML实现各种原型设计和信息呈现,所以,我特么难道又是HTML派?
想想我自己最近这周让AI给我做的东西:产品原型、对比工具、解释器、可视化页面,清一色全是HTML。Huashu Design这个skill更直接,专门用来批量生成HTML原型。我分享给朋友看的东西,几乎一个md都没有。
这么一看,我又像个彻头彻尾的HTML党。
其实,这压根就没什么好争论的。
md党和html党
我们可以先来看看这一波的争论,两边都在讨论什么。
先说md党。
去年8月,OpenAI发了个东西叫AGENTS.md,就一个md文件写在项目根目录,告诉AI agent怎么干活。一年时间被60000多个开源项目采用,Cursor、Codex、Devin、Claude Code、Gemini CLI、GitHub Copilot都支持。去年12月Linux Foundation直接成立Agentic AI Foundation把它捐进去做开放标准,白金成员里有AWS、Anthropic、Google、Microsoft、OpenAI,基本是AI半壁江山一起坐下来给md站台。
Karpathy今年4月开源llm-wiki,核心架构是三层md:raw目录放原始资料,wiki目录放AI写的概念页和索引,CLAUDE.md定义schema和规则。仅仅那个CLAUDE.md,单日就涨了7900个star,目前快5万了。一个markdown文件,5万star。
Cloudflare的实测数据:同一篇博客,HTML 16180个token,转成md只要3150个。一篇博文压80%的token,意味着同样的LLM预算可以处理7-17倍的请求。
GitHub官方博客今年放出了一个有趣的说法:「文档不再是描述代码,文档就是代码。自然语言被编译成下层语言,恰好长得像Python或者JavaScript。」
我自己也观察到一个挺讽刺的事。我那两个开源项目,nuwa-skill和huashu-design,都是1万+star的repo,主体内容都是md文件。但因为里面还有零散的Python和HTML文件,被GitHub贴了Python和HTML的语言标签。GitHub的项目分类系统,到现在还认不出md才是源代码。md在GitHub的语言标签里,连个名字都没有。
这几个方向的事实,我觉得完全可以得出「md才是这个时代的源代码」的结论。
但html党也有理。
Thariq那篇爆文我读完,他的几条论据我都同意。
第一是空间信息。diff、调用图、架构图、流程图,本来就是有空间维度的信息,md把它们压扁成一行行的字。同样一份diff,让AI渲染成左右对照的html页面,理解效率根本不是一个量级。 
第二是动态体验。我做产品原型时让AI生成带动画的mock,按钮按下去转什么颜色、用什么easing曲线、过渡多久,这种东西文字描述再多都没用,得真看一眼才能判断。
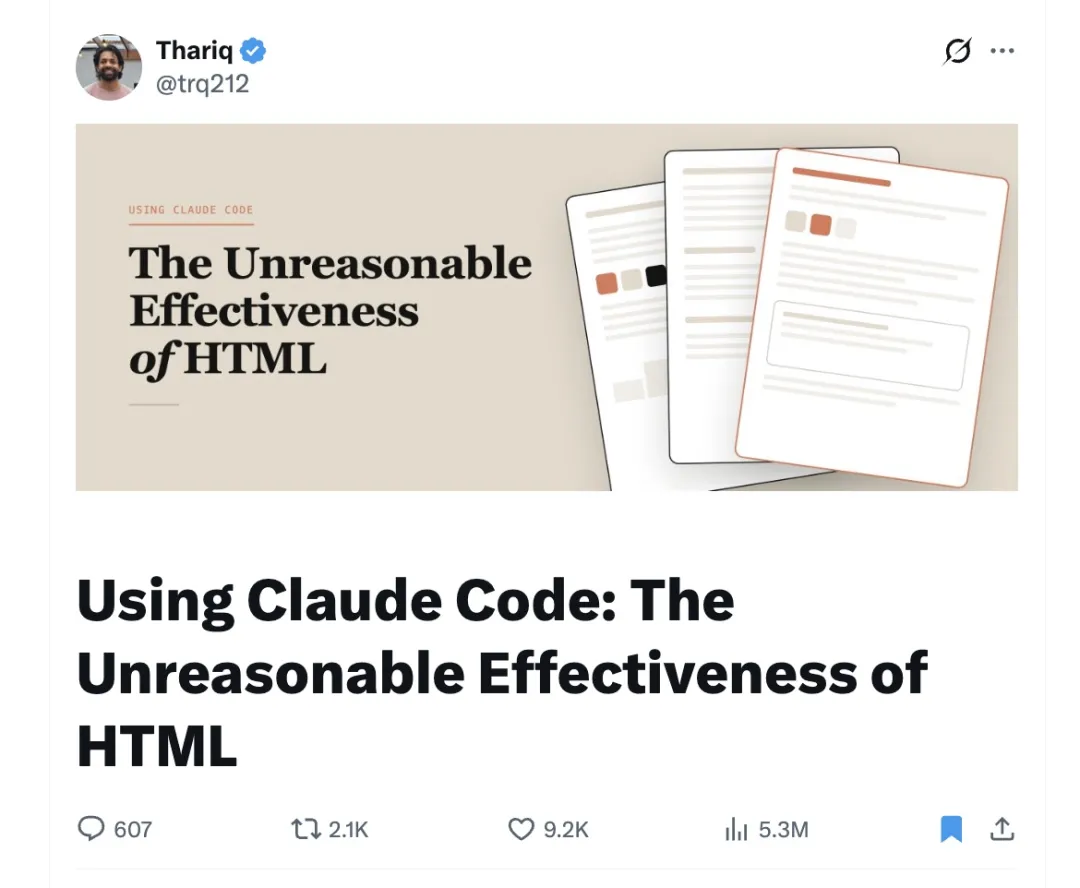
第三是结构化阅读。一篇带可折叠章节、tab代码块、边栏术语表的解释器,跟「同样的字线性堆一遍」根本是两种东西。Thariq原话:Each one trades a document you’d skim for one you’d actually read。原来你只会扫一眼的文档,现在你真的会读。
Anthropic今年4月推了Live Artifacts,HTML已经从静态产物升级成「持久化、可交互、能拉实时数据的dashboard」。
Thariq文章里有句话我记住了:the real reason I use HTML is that I feel much more in the loop with Claude。HTML让他重新感觉自己在AI协作中「在场」。
这些证据也挺硬的。html党赢了,如果他们的论点是「html才是这个时代给人看的产物」的话。
但你看出问题了吗。两边都赢了,因为他们各自在回答不同的问题。
md党回答的是「我们用什么写」,html党回答的是「我们给人什么看」。这俩根本不是一个问题,怎么会有谁取代谁。
是同一头大象,他们摸到的是不同的部位。
真问题:md生产,html消费
我觉得是时候把真问题说出来了。
md和html不是替代关系,是分工关系。
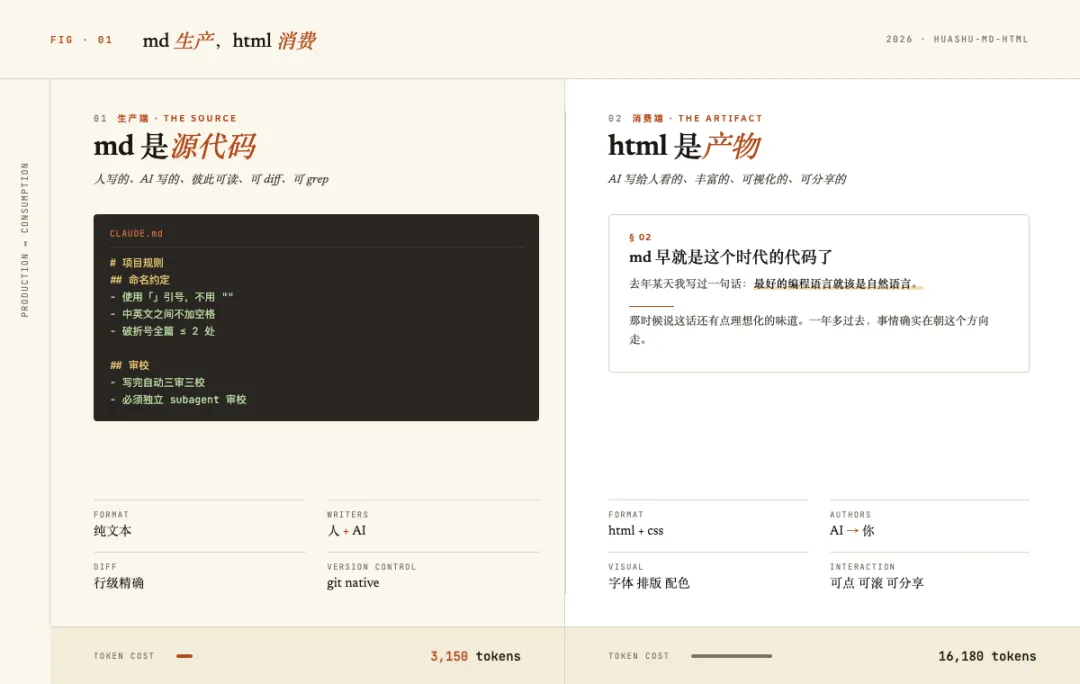
以前md和html也有过论战。那时候html是默认(blog、文档、官网都是html),后来md兴起,因为它写起来快、看起来干净。技术圈基本切到了md。
那个论战的隐含前提是:生产者和消费者是同一个人。你写一份文档自己看或者写给同事看,不管哪种,写的人和读的人都是人,是同一类用户。所以选格式要折中,既要好写,又要好看。md胜出,因为它的折中点最舒服。
AI出现后,第一次出现了一个新情况:生产成本可以被AI吸收。
你不再需要「亲手编辑」产物。HTML因为太重而被嫌弃的那部分代价,由AI承担了。你只承担消费。
这意味着原来要折中的需求,被解耦成了两端的极端最优。
生产端要的是轻、是快、是可diff、是token-efficient。那就是md。 消费端要的是丰富、是可视化、是可交互、是好分享。那就是html。
两端各自登顶。中间那个折中位置,没人需要了。
最干净的活体证据其实是Thariq自己。同一个工程师,3月份发了篇Skills使用指南,里面强调「skill不只是markdown文件,但核心还是markdown」,他在生产端力推md。5月份发了那篇《HTML的不合理有效性》,他在消费端力推html。同一个人,两端各自登顶,互不打架。Thariq自己就是这个分工的活样本。
第二个例子是Karpathy和Lex Fridman那对组合。Karpathy的llm-wiki内核是markdown wiki,所有原始资料、概念页、索引都是md。Lex Fridman用了同款架构,在外面加了一层,让AI生成动态html+JavaScript,可以排序、过滤、调参、做交互可视化。内核md,外壳html。不是Lex替换了Karpathy,是他在Karpathy的基础上加了一层消费层。两层各做各的事,不冲突,互相加强。
所以Thariq没错,md党也没错,他们都对了一半。但只要还在「md vs html」这个二元对立的框子里,就永远只能拿到一半的真相。但,其实没有任何人比你当二极管的。
以前你写md看md。现在你写md,改md,AI给你html。
但争论为什么停不下来
我自己其实早就在用这个分工干活,只是没意识到这是一个值得命名的事情。直到看Thariq那篇文章那一刻,才反应过来。
但我也理解为什么大部分人还卡在二元对立里。
我觉得大多数都是AI还用得不够多,或者身份角色单一的。
当你既是内容的生产者,又是内容的消费者,既创作内容,又创作产品的时候。你会意识到那些乱七八糟的站队就是扯淡。
你会越来越清楚的知道你应该什么时候用md,什么时候用HTML,一切都是为了创作和表达服务的,而不是为了一个虚无缥缈的立场。
我的解法:huashu-md-html
所以我做了个Claude Code skill,叫huashu-md-html。
GitHub开源地址(MIT License):
https://github.com/alchaincyf/huashu-md-html
它干一件事:让你随时在md和html之间切换,不需要站队。
具体三个能力。
能力一:把任意东西变成md。封装微软的markitdown,PDF、DOCX、PPTX、XLSX、EPub、图片、音频、YouTube URL、ZIP压缩包、网页,20多种格式都能转成干净的md。一行命令搞定:python any_to_md.py file.pdf。
能力二:把md变成精美的html。封装Pandoc加4套手工调过的CSS主题。article是Tufte编辑型,适合essay和深度文章;report是出版级白皮书风,适合技术报告;reading是Medium极简型,适合纯阅读分发;interactive是带侧边栏目录的长文型,适合教程和书籍章节。每套主题都过了反AI slop检查清单,没有紫渐变、没有emoji当图标、没有#0D1117深蓝底,配色克制有出版社品位。
能力三:把html转回md。双引擎。博客文章和新闻类页面走trafilatura自动提取正文,去掉导航和侧栏;产品页和技术文档走markitdown,保留完整的metadata、标题层级和链接。一条命令搞定。
三个能力组成一个完整闭环:输入端永远是md,输出端按场景选html主题。md是源,html是产物,这是一个工作流问题,不是站队问题。
我自己最直接的活样本是橙皮书系列。
橙皮书7本,全部免费上架微信读书,加起来读者过百万。经常有人问我同一个问题:你的橙皮书排版怎么这么好看?比一般电子书强太多了。
答案就是这个分工。每本书写作时我让AI产出的从来都是md。一章一章的md文件,简单的标题层级,行内代码块,普通的无序列表。我review改的也是md。到了构建环节有一个build脚本,md转成html章节片段,html再编译成epub和pdf。所有的字体选择、颜色搭配、版面设计、章节装饰、代码高亮,全在html那一层做。
读者拿到的是漂亮的epub或pdf,html的所有表达力都用上了。但我和AI review的时候面对的永远是md,token efficient,能塞下整本书的上下文,没有视觉干扰,能专心看文字。
我做这个skill其实就是把过去一年我自己干的事情工具化,让任何人都能不站队、不折腾、直接用对的格式干对的事。
别再争了
回到开头。
Thariq没错,md党也没错。但他们在争的那个问题,「哪个会赢」,是个伪命题。
md不会赢,html也不会赢。它们在不同的端各自登顶,互不替代,互相增强。
你下次想吵这个的时候,先问自己一句——
你现在面对的是「写」,还是「看」?
写,用md。
看,用html。
工具替你处理切换,立场可以放下了。
附:huashu-md-html开源地址 https://github.com/alchaincyf/huashu-md-html
MIT License · 三个能力 · 4套主题 · 反AI slop审美底线 · 与huashu-design同生态。
本文来自转载花叔 ,不代表发现AI立场,如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫