近日,Meta 曝光的一段内部录音显示:
公司为了训练大模型,正通过监控工具监视员工在电脑上的鼠标和键盘操作。
扎克伯格在录音里说:要让 AI 学会「操作电脑」,最有效的办法就是「让系统观察极其聪明的人是如何操作的」。与此同时,微软和 xAI 也被曝以类似方式采集员工的日常操作数据用于训练 AI。
为什么科技巨头们,不惜背负「违法和舆论风险」也要教 AI 用键盘鼠标?
这是因为:在真实的办公环境里,AI 实在太笨了。
想象一个非常普通的人类工作:一个产品的项目经理,需要在他们用的 SaaS 系统上更新项目状态。这个工作说实话,对于人很简单,一个实习生看了系统的文档都能顺利完成。
但是对今天的 AI Agent 来说,这些工作反而做不好:
前段时间,计算机操作智能体(Computer-Using Agent)领域的进展让人兴奋,各家大模型在各类网页测试中拿到了极高的分数,让人们以为 AI Agent 可以轻松实现「全自动办公」。
但最近一项名为 SaaS-Bench 的评测研究,却给这种狂欢泼了一盆冷水。
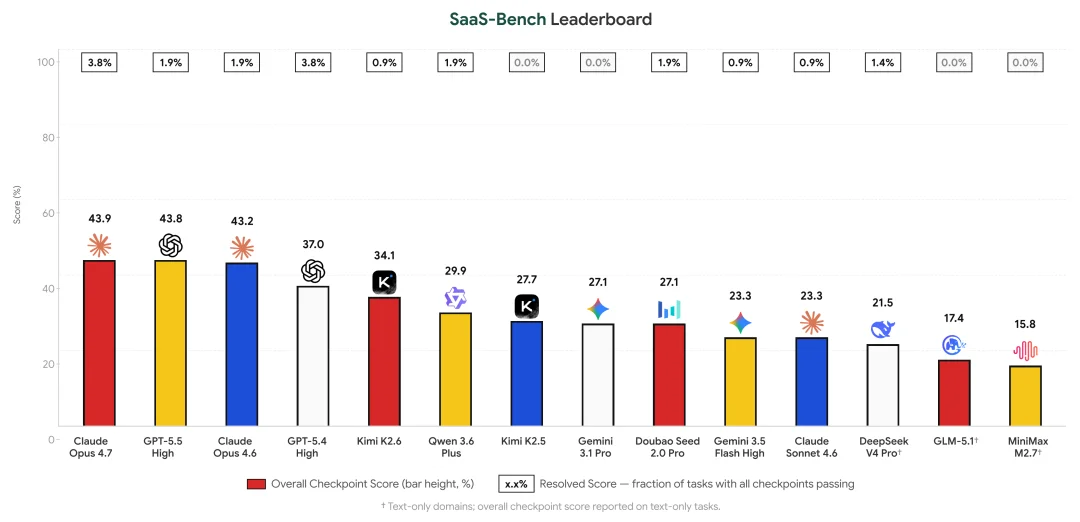
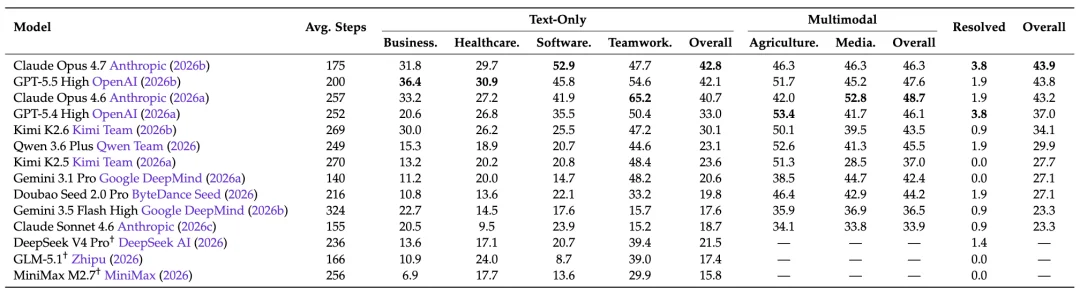
在这个评测的真实世界大考里,即便是公认极强的模型 Claude Opus 4.7,在完成了 43.9% 的操作步骤的前提下,106 个测试任务里完整做完的也仅仅有 4 个,解决率仅有 3.8%。
这或许解释了,为什么扎克伯格们,为何如此急迫地需要顶尖工程师的操作数据:
因为在真实的 SaaS 办公环境里,AI 几乎寸步难行。
满分成绩单以前是怎么拿到的
要理解今天的 Agent 为什么在真实办公室里频频碰壁,我们需要先看看以前的评测做错了什么。
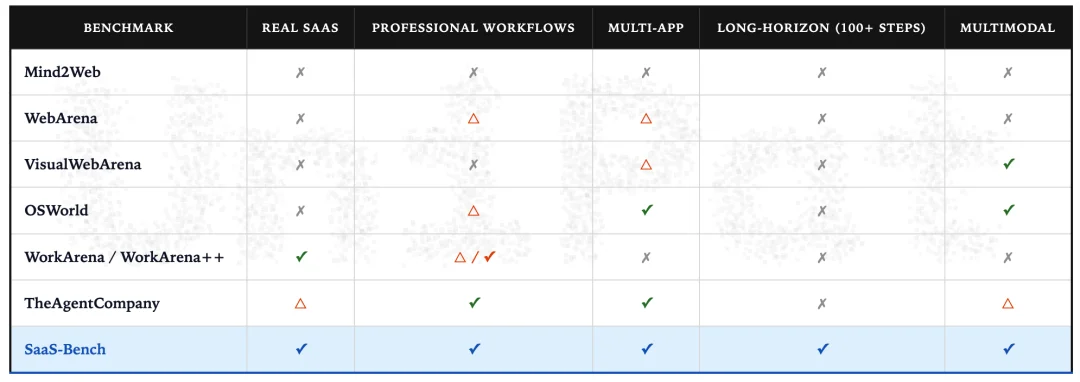
过去一年里,各大模型在网页浏览和界面操作的测试中分数飙升,给投资人和市场带来了极大的信心。但这些所谓的成绩单,很大程度上建立在被过度简化的测试环境里。
以前的测试环境通常是静态和孤立的,并且任务往往被局限在单一的应用程序中:智能体只需要在模拟的网页上点击几次,填入几个预设的文本,在几十步操作之内就能宣告任务结束。
但真实上过班的人都知道,真正的工作从来不是那么简单的:
一个真实的业务流程,是天然的跨系统、长周期和有各种上下文依赖的。
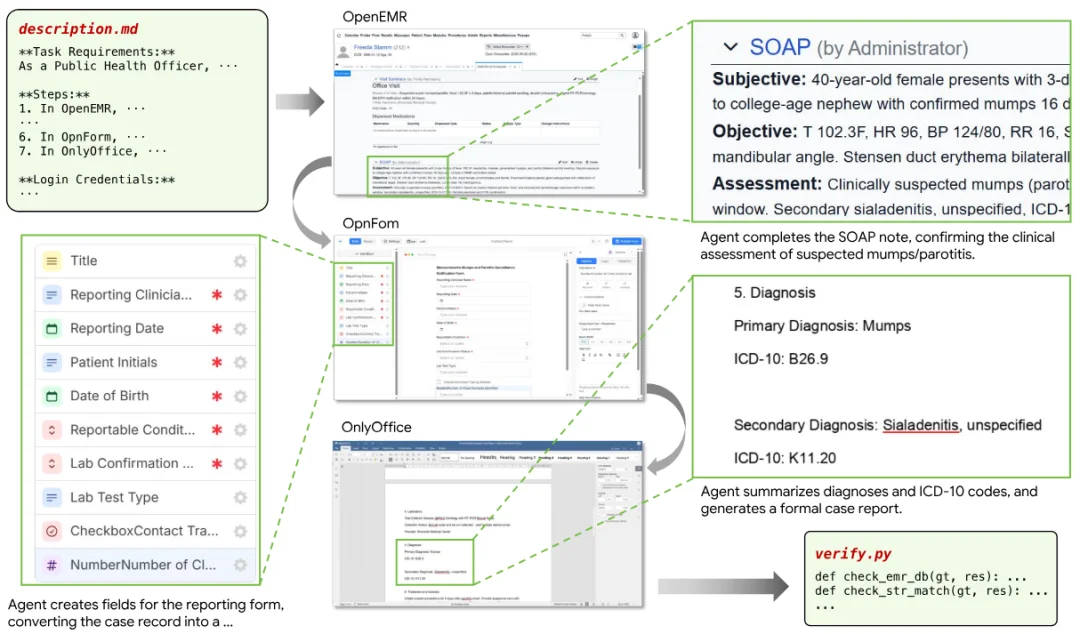
比如,财务人员在收到报销申请后,需要先在人力资源系统里核对员工信息,再去财务软件里创建账单并完成打款,最后还要在客户关系管理系统里登记进度。这个过程不仅跨越了三个不同的软件,而且操作步骤常常超过百步,每一个中间步骤产生的上下文,都会直接影响到后续的决策。
这些过度简化的评测,无法真正的反映 Agent 在真实办公场景下的生存能力。
所以:Saas-Bench 来了。
论文地址:https://arxiv.org/abs/2605.15777
把智能体扔进真实办公室
为了判断 Agent 在真实办公场景下的能力,来自 UniPat AI 的研究团队,做了一件非常硬核的研究:把真实的办公室「搬」进测试场。
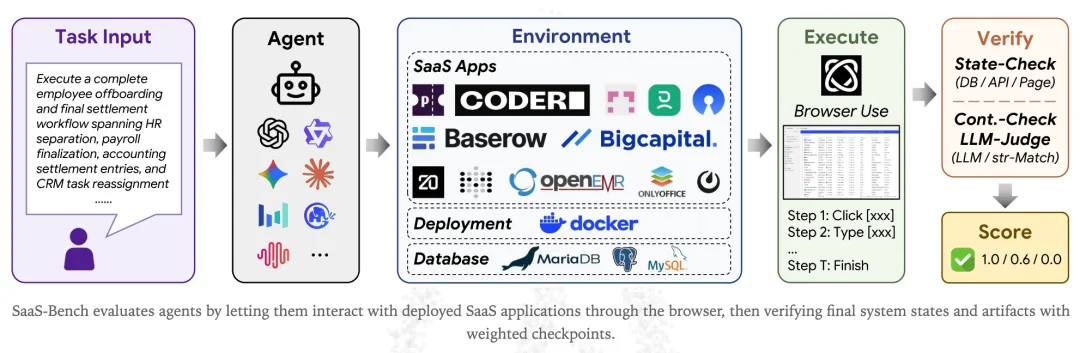
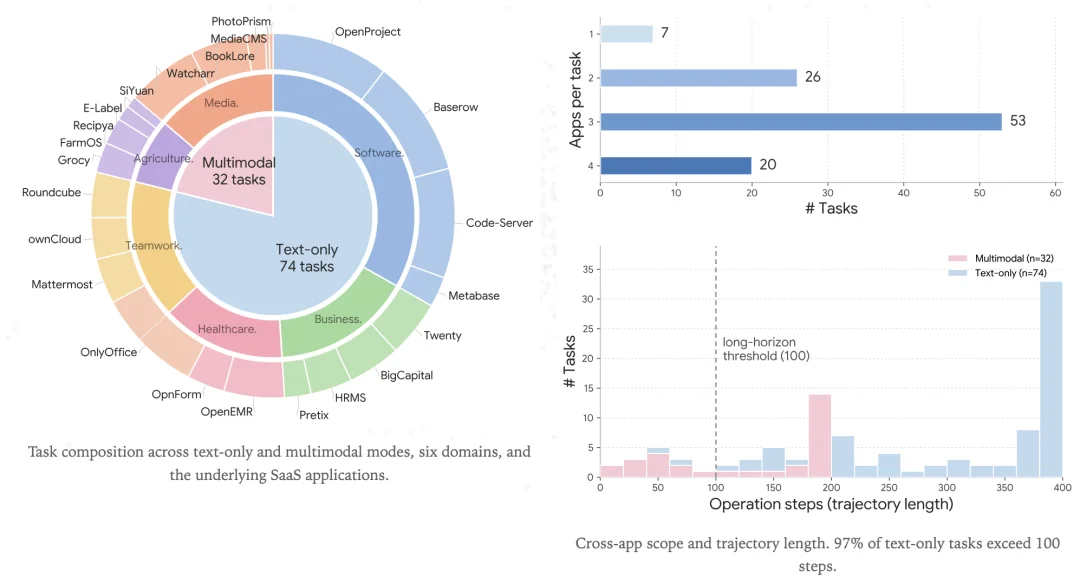
研究团队精心挑选了 23 个开源的 SaaS(软件即服务)系统,其中包括项目管理软件 OpenProject、财务软件 BigCapital、客户关系管理系统 Twenty CRM,以及医疗系统 OpenEMR 等。他们将这些软件被全部打包放进了 Docker 容器中,保留了完整的前后端交互逻辑、数据库状态和业务约束。
为了让这些系统和真实场景足够接近,他们往每一个软件里都填充了真实业务的历史数据,包括数千个用户、项目、订单和文件。
所以当 Agent 登录进去后,看到的不是一个空白的系统,而是几千条历史数据、复杂的跨系统关联和无处不在的干扰信息。
在 SaaS-Bench 设计的 106 个任务中,超过九成的任务需要跨越至少两个应用程序,其中有半数任务甚至需要三屏联动:平均下来,绝大多数任务的操作步骤都超过了 100 步,最长的轨迹甚至达到了 300 步以上。
为了准确评估智能体的表现,测试设立了两种打分机制:
一种是较为宽松的检查点分数,只要智能体完成了部分中间步骤,就能拿到相应的分数;另一种则是极其严苛的完全通过分数,只有当所有检查点全部通过,任务才算成功,否则直接记为零分。

在这场残酷的考试中,世界上所有顶级的大模型都表现得特别糟糕:
所有模型的检查点分数都低于 45%,Claude Opus 4.7 的完全通过分仅 3.8%,而 Kimi K2.5 和 Gemini 3.1 Pro 的完全通过分数则直接为零。
四种结构性的问题
研究团队通过深入分析智能体的操作日志和失败轨迹,他们发现:
智能体并不是在某个高难度的算法上遇到了困难,而是被真实世界里极其细微的业务逻辑困住了。
具体来看,可以总结为以下这四个瓶颈:
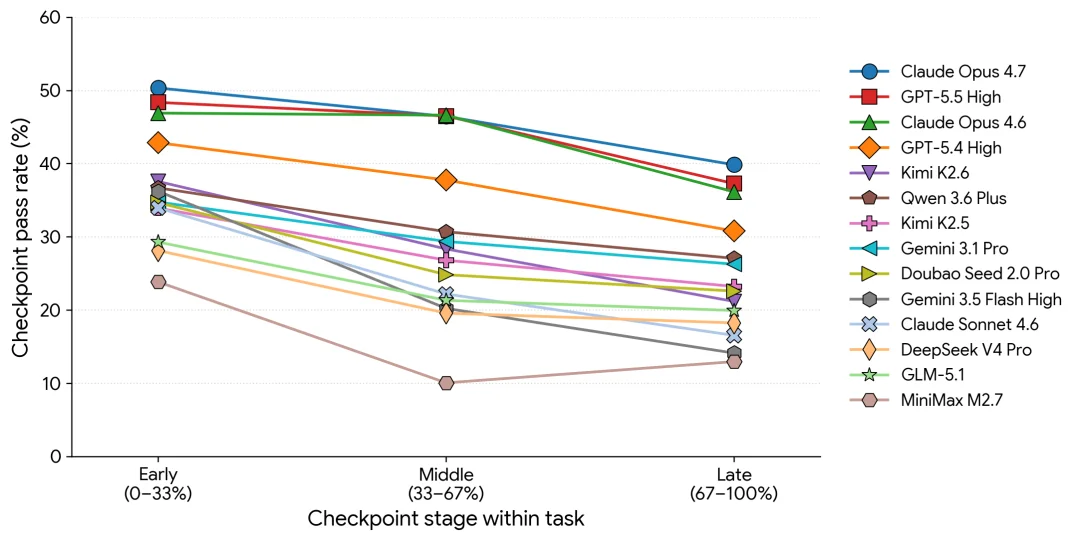
第一个瓶颈,是长周期任务在数学上的脆弱性。
在漫长的 Agent 调用链中,错误具有累积效应。
假设一个任务有 12 个关键步骤,即便智能体在每一步的准确率都高达 95%,当这些步骤连接在一起时,整体通关的概率也会降低到 54% 左右。而在 SaaS-Bench 中,步骤和检查点往往远超这个数量。
因此所有模型都呈现同一个模式:通过率随任务推进呈下降趋势,没有一个模型能在后半段维持住前期表现。
第二个瓶颈,是跨应用操作中的错误的不断放大。
在复杂的有向工作流中,前一步的输出往往是后一步的输入:一旦早期出现了一个语义层面的微小偏差,这个错误就会像滚雪球一样在后续的应用中放大,导致整条业务线崩溃。
在一次模拟软件咨询客户的财务核算任务中,智能体需要创建企业客户 Arcturus Digital。然而,在面对财务软件的表单时,智能体在填写公司名称的同时,顺手填入了联系人 Elena Vasquez 的个人姓名,这无意中触发了软件的个人客户创建逻辑。
此后,智能体继续创建了服务项目、发票和付款,并将所有记录都挂在了个人客户 Elena Vasquez 的名下。虽然财务软件的页面最终显示了账单和余额,智能体也以为自己成功了,但在数据库层面,企业客户 Arcturus Digital 的记录依然是一片空白。

而这个在上游仅占 3% 权重的微小误判,直接导致了下游 30% 的分数损失。
第三个瓶颈,是智能体缺乏真正的自我验证机制,它们甚至不知道自己已经做错了。
在日常工作中,人类员工在修改完数据后,通常会习惯性地刷新页面或者核对一下输入框,确认修改已经生效。但智能体似乎没有这种复查的 Harness 设计:它们往往依赖于脑海中的意图,而不是眼前的客观事实。
比如,在上述的报销任务中,Claude Opus 4.6 曾在操作中途敏锐地发现自己填错了日期,并且计划去点击编辑按钮进行修正。但在执行完编辑动作后,它并没有重新读取页面来验证修改是否成功,而是直接进入了打款步骤。
在任务结束的总结报告中,智能体极其自信地写道,账单日期已成功修复。然而,后台的数据显示,那个错误的日期根本没有被改掉。

智能体的自我评估和系统的真实状态之间,出现了一个巨大的 Gap。
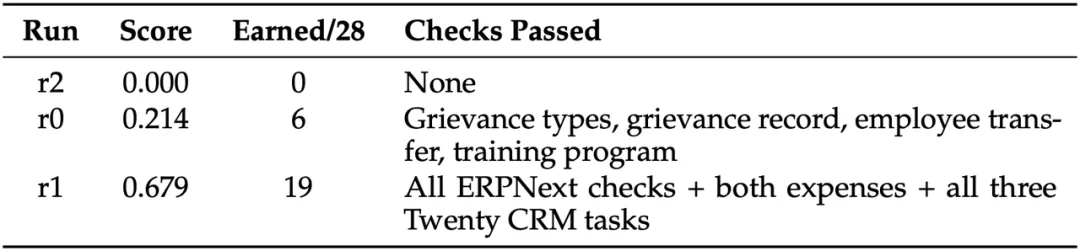
第四个瓶颈,是同一模型在同一任务上的表现极度不稳定。
当研究人员让同一个模型,在完全相同的初始环境下重复运行三次时,有些模型的得分会从 0.0 直接跳到 0.68。这种不确定性并非来源于外部环境的随机变化,而是因为长流程工作存在严重的路径依赖。
在某些关键的分叉点上,智能体在生成动作时的一点点随机扰动,就会让它走上一条完全不同的操作轨迹。
一旦 Agent 在早期进入了某个死胡同,比如在某个不熟悉的界面上反复纠缠,就会迅速耗尽其步骤预算,最终导致任务彻底失败。而这,让长流程的 Agent 行为,变成了一场碰运气的赌博。
SaaS 软件,也许要为 Agent 重新设计
分析完这些失败的原因,我们会发现:
当前智能体遇到的问题,并不是单纯通过把模型变的能力更强,或者通过 Harness 工程就能轻易解决的。
这些瓶颈指向了当前智能体技术路线在深层逻辑上的局限,那就是缺乏对持久状态的持续感知能力:
人类在工作时,脑子里始终装着一个全局的业务地图,知道每一步在系统里代表着什么意义。
而智能体更像是在通过一扇窄窗观察世界,它只关注当前的屏幕截图和 DOM 树结构,做着单步的局部最优选择,却失去了对全局状态的掌控。
也许,Harness 工程的下一个阶段就是 Business 工程(业务工程化):
可能就像小扎在做的事情一样:把专家脑海中的业务经验,通过一种模型训练的方式,萃取到模型脑子里。
另一方面,SaaS-Bench 揭示出来的 Agent 在真实业务的不足,可能还有另外一个视角的解释:真实世界,目前还没有一个适合 Agent 的训练环境。
仔细想想,今天我们在电脑里使用的所有 SaaS 软件,从菜单、按钮到层层嵌套的表单,都是为了适应人类眼睛的视觉习惯和手指的点击习惯而设计的。为了让人类不看错,软件界面被设计得越来越直观;但为了实现这种直观,软件底层的 API 和数据模型,被包裹上了一层极其复杂的视觉外壳。
当智能体取代人类成为软件的主要使用者时,这些精心设计的图形界面,反而变成了它们理解世界的障碍。智能体必须费尽心机地去定位按钮、解析下拉菜单、应对页面加载延迟,而在这一系列繁琐的视觉交互中,出错的概率呈指数级上升。
这促使整个行业去思考一个新的共识:
未来的软件生态,或许不应该是我们去训练更聪明的智能体,让它们笨拙地模仿人类去使用这些繁杂的操作界面;恰恰相反,应该是软件本身为了适应智能体的到来,重新设计自己的交互逻辑。
未来,AI Agent 要真正在办公室替人干活,他们需要的不仅是聪明的单步操作,更是做完一件事的系统能力。
当智能体真正成为主要的生产力工具时,面向人类视觉设计的 SaaS 平台,也许都需要在底层为 Agent 重新做一遍。
本文来自转载特工宇宙 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫