过去一年,Mobile Agent 发展很快。从看懂屏幕、点击按钮,到跨 App 完成长序任务,模型能力正在不断提升。但限制 Mobile Agent 继续 scaling 的,可能不只是模型本身,而是环境:环境既决定了训练数据从哪里来,也决定了 Agent 的动作能否被执行、结果能否被验证、失败能否被复现。
以 Google AI Studio “一句话生成 App” 为代表,AI 正在大幅降低 App 构建门槛。过去需要开发者手写代码的移动应用,现在可以通过自然语言快速生成原型,甚至生成可运行的 Android App。这也让规模化创造 App 环境变得前所未有地现实,Mobile Agent 有机会在更多界面、任务和交互流程中训练。
但问题是:这些从零自动生成的 App,真的像真实 App 吗?
如果生成的 App 只是 “看起来像”,但页面结构、导航路径、状态变化和用户行为分布都与真实 App 存在明显 gap,那么在这些环境里训练出来的 Agent,就很难真正迁移到真实手机场景。
腾讯混元牵头,联合港中深、人大高瓴、武汉大学等机构的最新研究 PhoneWorld: Scaling Phone-Use Agent Environments 正是要解决这个问题:
如何规模化地构建可训练、可验证、且与真实手机使用场景足够接近的 App 环境。

- 论文地址:https://arxiv.org/abs/2605.29486
为什么不直接用真实 App?
既然真实 App 已经存在,为什么还要重新构建一批 mock Android App?核心原因是:真实 App 足够真实,但很难被稳定地用于大规模训练。
1. 真实 App 的状态很难重置。Agent 一旦执行收藏、发消息、下单、修改设置等操作,账号和 App 内部状态就会被改变。想要让同一个任务反复执行,就必须恢复数据、缓存和账号状态,成本很高。
2. 真实 App 的结果很难自动验证。Agent 是否真的完成任务,不能只看它最后说 “完成了”。消息是否真的发出、商品是否真的加入购物车、设置是否真的修改,都需要可靠的 verifier。但真实 App 的内部状态通常不可直接访问,很难稳定检查。
3. 真实 App 还有很多不稳定噪声。登录状态、风险控制、人机检验、权限弹窗、广告推流、网络波动、版本更新,都可能导致环境在不断被干扰,让同一个任务在不同时间出现不同路径。
所以,真实 App 是最接近目标场景的环境,却不一定是最适合规模化训练和可复现评测的环境。
PhoneWorld 要解决的,就是如何保留真实 App 中对 Agent 最重要的页面结构、导航路径和状态变化,同时把它们转化为可运行、可重置、可验证的训练环境。

PhoneWorld 如何把真实 App 变成 mock App?
PhoneWorld 的构建流程可以概括为一句话:先从真实 App 的截图和操作轨迹中恢复 “使用结构”,再把这种结构转化为可运行、可重置、可验证的 mock Android App。
具体来说,PhoneWorld 会先分析真实用户在 App 中经过了哪些页面、页面之间如何跳转、哪些操作会改变状态;然后生成页面级 PRD、数据 schema 和可复用组件;最后由 coding agent 自动实现 App,并经过自动测试和人工审计,确保它保留真实 App 中对 Mobile Agent 最重要的交互路径。
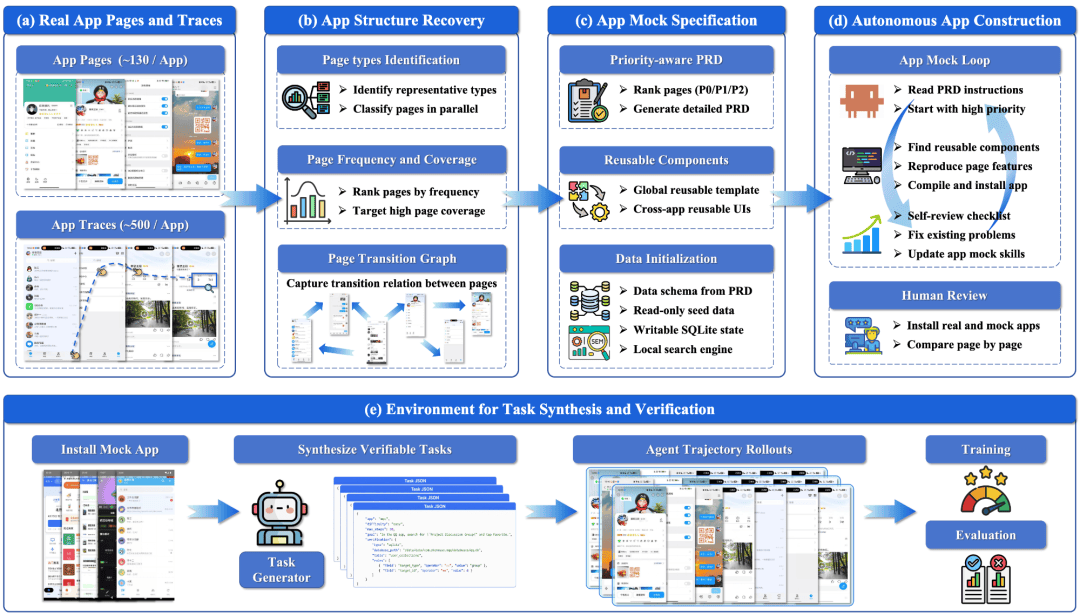
复刻的不只是截图,还有真实 App 的功能骨架
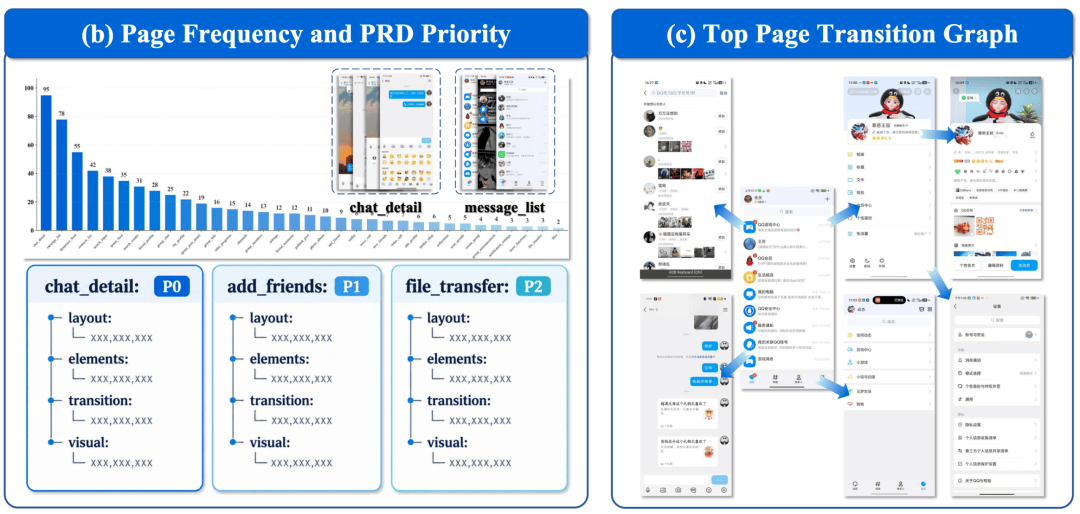
一个真实 App 可能有大量页面和功能,但 Mobile Agent 训练真正需要的,往往是用户最常经过的核心路径。
因此,PhoneWorld 不会盲目复刻整个 App,而是先从真实轨迹中恢复页面结构:哪些是首页、搜索页、详情页、聊天页、订单页;哪些页面出现频率最高;用户通常从哪个页面跳到哪个页面。
在确定 “哪些页面重要” 之后,PhoneWorld 还会为每类关键页面生成结构化 PRD。PRD 相当于 mock App 的 “施工图”:它会描述页面布局、交互元素、跳转逻辑和视觉属性,告诉 coding agent 这个页面应该长什么样、有哪些按钮、点击之后应该去哪里、哪些状态需要被更新。
这一步的意义在于,PhoneWorld 不是在 “照着截图画界面”,而是在回答一个更重要的问题:真实用户到底是怎么使用这个 App 的?又如何把这种使用方式转化成 AI 可以自动构建的 App 规格?
mock App 不只是会跳转,还要有真实可变的状态
很多自动生成的 App 原型,看起来有页面、有按钮、有跳转,但对 Agent 训练来说还不够。
因为很多真实任务往往不是 “点到某个页面” 就结束了,而是要改变环境状态:收藏一条内容、加入购物车、发送一条消息、修改一个设置、提交一条评论。
所以,PhoneWorld 在构建 mock App 时,会同时构建一个可控的数据层。
- 一部分是只读内容,例如商品、帖子、联系人、地点、视频、音乐等,用来支撑浏览、搜索和信息查询
- 另一部分是可变状态,例如收藏、购物车、消息、评论、订单等,会随着 Agent 的操作写入本地数据库。
这让 mock App 从一个 “能看的原型”,变成了一个 “能被操作的环境”。
Agent 做过什么,环境会记住;任务执行完之后,系统也可以把状态重置到初始版本,方便反复训练和评测。
App 可以由 AI 自动构建,但环境不能放任生成
有了页面结构、跳转关系、PRD 和数据层之后,PhoneWorld 会让 coding agent 生成 Kotlin / Jetpack Compose 项目,并编译成可运行的 Android APK。
但生成 APK 只是开始。
对 Mobile Agent 来说,一个环境不能只是 “能打开、能跳转”,还必须经得起真实任务执行:按钮是否真的可点,收藏、发消息、加入购物车等操作是否真的改变状态,任务结束后环境是否还能被重置。
因此,每个 mock App 都会被安装到模拟器中,经过自动测试和人工审计。自动测试检查核心流程是否跑通,人工审计则对比真实 App 和 mock App,确认主要页面、交互路径和状态变化是否足够接近真实场景。
- 普通 App 生成更关心 “能不能快速做出一个 App”
- PhoneWorld 更关心 “这个 App 能不能成为 Mobile Agent 可训练、可评测、可验证的环境”。
有了 App 还不够,关键是任务能执行、结果能验证
构建出 mock App 只是第一步。对 Mobile Agent 来说,环境真正有价值,不只是因为它能打开、能点击、能跳转,而是因为它能承载任务、记录状态,并自动判断任务是否真的完成。
PhoneWorld 的任务并不是凭空生成的,而是来自 App 背后的页面 PRD、只读内容和数据库 schema。也就是说,任务中出现的商品、联系人、地点、群聊等实体,都真实存在于环境中;任务要求的收藏、发消息、加入购物车等操作,也都对应真实可改变的状态。
这让 PhoneWorld 可以为每个任务配套 verifier:
- 对于信息查询任务,系统检查最终答案是否包含正确值
- 对于状态改变任务,系统直接查询本地数据库,确认消息、收藏、评论等状态是否真的被写入。

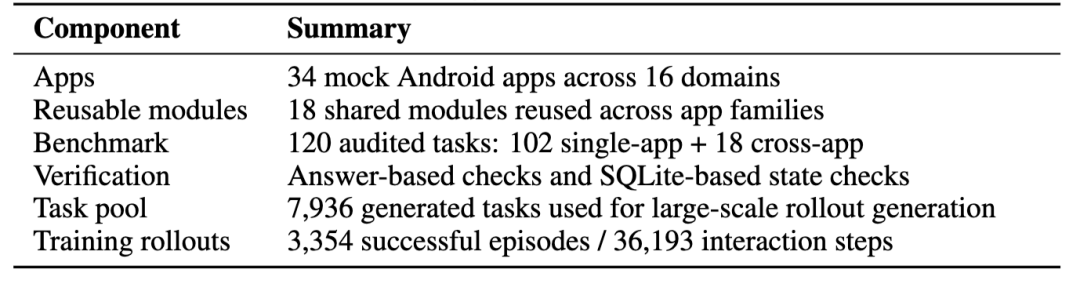
基于这套机制,PhoneWorld 当前已经形成了一套可同时用于评测和训练的手机环境基础设施:
- 34 个 mock Android App
- 16 个消费级移动应用领域
- 120 个经过人工审计的评测任务
- 3,354 条成功轨迹
- 36,193 个交互步骤。
mock App 不是玩具环境:PhoneWorld 让四个 benchmark 同时提升
PhoneWorld 最核心的问题其实很直接:
这种从真实轨迹中重建出来的 mock 环境,到底有没有用?scale 起来之后,能不能真的帮助 Mobile Agent?
论文用三个实验回答了这个问题。
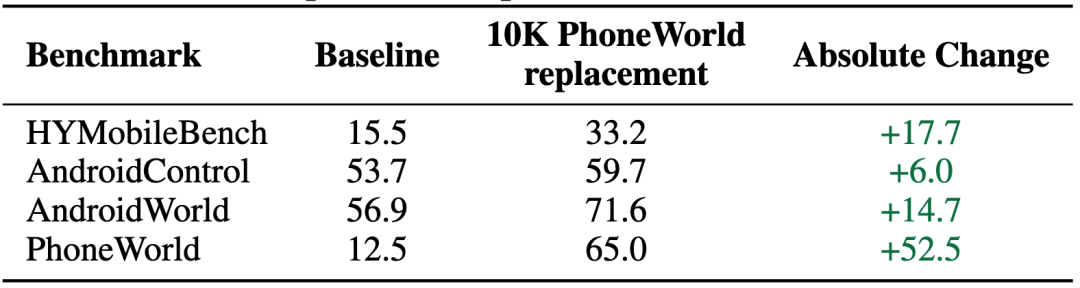
mock 环境有没有训练价值?
研究者没有简单增加数据量,而是只用 10K PhoneWorld steps 替换一部分原有 AndroidWorld 辅助数据。结果模型在四个 benchmark 上同时提升:
- HYMobileBench 提升 17.7
- AndroidControl 提升 6.0
- AndroidWorld 提升 14.7
- PhoneWorld 提升 52.5
PhoneWorld 不是只在 mock 环境里自我提升,而是能把可控环境中的训练信号迁移到真实 App 评测中。
mock 环境能不能完全替代真实 App?
实验进一步把替换比例拉满:用 PhoneWorld 数据完全替换辅助 AndroidWorld 数据。
结果显示,PhoneWorld 自身表现继续提升,同时 HYMobileBench 和 AndroidControl 也保持明显增益;但 AndroidWorld 出现下降。
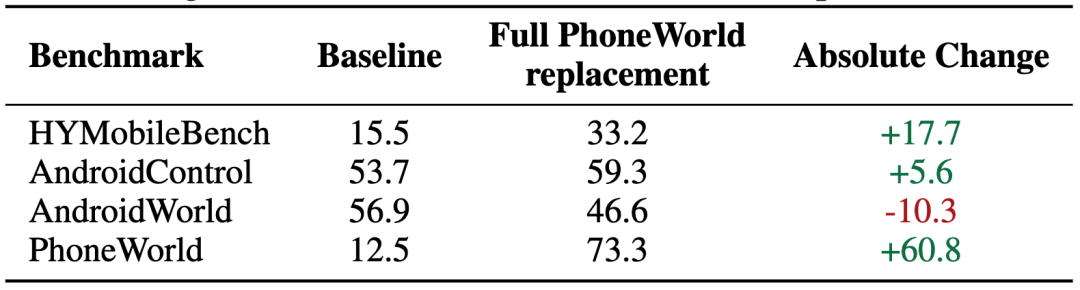
这个结果并不是说 PhoneWorld 数据无效,更准确的结论是:PhoneWorld 不是简单替代真实 App 数据,而是与真实 App 数据形成互补。真实 App 数据提供真实分布覆盖,PhoneWorld 则提供可控、可重置、可验证、可规模化扩展的训练环境。
mock 环境 scale 起来有没有效果?
如果 PhoneWorld 环境继续扩大,收益会不会继续增加?
- Scaling step data: 随着 PhoneWorld supervision 从 0 增加到 10K、20K、36K,PhoneWorld task success rate 从 14.2 提升到 64.2、70.0、73.3。也就是说,PhoneWorld 可以随着可验证轨迹增加,持续为模型带来收益。
- Scaling app data: 在固定 10K PhoneWorld 训练预算下,研究者进一步比较了来自 5、10、20、34 个 App 的训练数据。结果显示,在 4 个 benchmark 上都提升了效果。这也证明了,PhoneWorld 可以随着 App 环境多样性的提升,为模型带来收益。

写在最后:Mobile Agent 的下一站,是环境 scaling
Mobile Agent 的竞争,正在从 “模型能不能点对屏幕”,走向 “模型有没有足够真实的世界可以训练”。
真实 App 最接近用户场景,但难重置、难验证、难规模化;从零生成 App 足够快,但又可能和真实使用存在 gap。PhoneWorld 试图走中间路线:从真实 GUI 轨迹中恢复页面结构、导航路径、状态变化和任务目标,再把它们转化为可运行、可重置、可验证的 mock Android 环境。
所以,PhoneWorld 真正回答的不是 “能不能造一个 App”,而是:
当 Mobile Agent 需要大规模训练时,我们如何系统性地建造更多接近真实手机使用的世界?
AI 手机时代,模型会越来越强。
但能让模型继续变强的,可能正是这些可交互、可验证、可扩展的世界。
本文来自转载机器之心 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫