短的结论:时来天地皆同力
基本情况:
GLM 前一代 5.1 曾经是国模中第一个真正冲过 Sonnet 把持的编程基本可用线的,但由于上下文问题,在超过 100K 后注意力快速散失,导致在真正生成环境下,可用性大幅下滑。如果不是注意力问题,GLM-5.1 在当时就会更加接近 Opus 4.5 (非推理模式)。
在 GLM-5.1 之后的 2 个月里,DeepSeek V4,Qwen3.7-Max,Kimi K2.6 等模型多次挑战国产模型 Coding SOTA 败北。而北美又往前迭代了两代,GPT-5.5 与 Opus 4.8 已经把差距拉的更大,横空出世的 Fable-5 更是将 AI 智力天花板往上抬到了卡门线,离逃逸只差一步。这也意味着国产模型与世界顶级的差距正在被进一步拉大。
在这种万马齐喑之时,最终还是智谱自己来破局。GLM-5.2 不但补齐了 5.1 的短板,更是靠着扎实的后训练和泛化场景覆盖,把 Coding 能力直接推进到世界一流模型的门口。
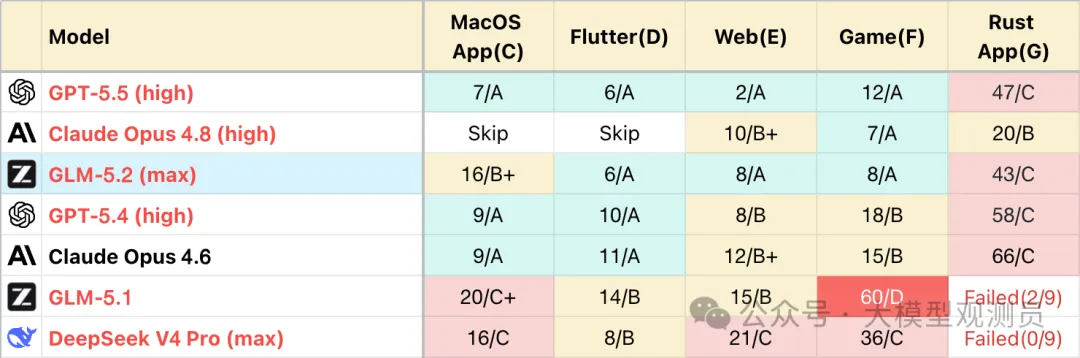
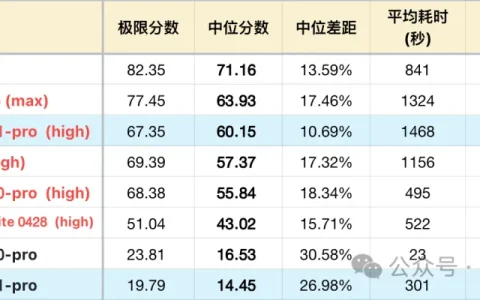
* 完整榜单见:https://llm2014.github.io/llm_benchmark/#category=code_v3&dataset=code_v3%7C2026-06%7C0
在目前公开成绩的 5 个工程中,GLM-5.2 取得了 3 个 A 档成绩,A 档意味着模型几乎不犯错,对用户需求的理解是一步到位的,这个成绩持平 Opus 4.8,(Opus 4.8 在表里有 2 项 Skip,这是由于其前代已经拿到 A 过关,新版默认按 A 算,不再测试)只在小众一些的 Mac,Rust 等场景略输一些。但可用性也十分在线,不需要用户干预过深,仅靠自己推理也能完成项目,而其前代 5.1 则完不成 5 个项目。
在非公开的 2 个复杂度更高工程中,GLM-5.2 是首次参与,排除背题可能。 2 个项目均以 C 档通过。但扣分并不高,主要是个别挑战高的环节,GLM-5.2 也会反复修改 2~3 次。大部分国产模型没有测过隐藏题,但 DeepSeek和 GLM-5.1 是无法完成项目的。
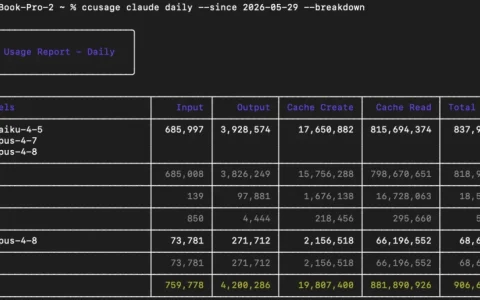
GLM-5.2 在能力接近 Opus 4.8 的同时,完成工程的消耗却要显著更低,以二者成绩相近的 F 项目为例,Opus 4.8 一共产生了 564 次 tool calls,输出260K。而 GLM-5.2 使用 557 次 tool calls,输出仅170K。其他项目 GLM 消耗也都低于 Opus,没有特例。不过需要说明,还是 GLM-5.2 工作在 max 档位,Opus 在 high 档位的错位对比。
在架构能力上,GLM-5.2 的规范性显著提升,在不同类型的项目中,都能基本遵循对应技术栈的好实践(注意不是最佳实践),不会出现像 GPT 这样仅在少数技术栈有架构设计意识的情况。GLM-5.2 会尽量多写代码,把架构的每个细节都填实,丰满。这导致在 5 个工程中,GLM-5.2 的产出代码量是目前在测模型最高,平均高出 30%。换个角度看,GLM-5.2 在代码量比模型更高的情况下,却很少出现因为看漏代码细节导致的 Bug,也足以证明其 1M 上下文的含金量。
在前端审美上,GLM-5.2 相对较为克制,在完全满足用户基本要求前提下,不会自行发挥太多,所以其直出的 UI 看起来比较朴素。但与之配套的交互可用性却相当高,以隐藏项目 E2 为例,其中有一处交互是为两个相邻的视频 clip 添加专场特效,需要同时兼顾每个 clip 原先已有的复杂手势交互,施展空间很小。先前测试的模型都翻过车,但 GLM-5.2 顺利通过。
在小众领域,需要承认 GLM-5.2 还达不到 Opus 的知识广度,像 G 项目需要大量使用较新的技术栈,GLM 从头到尾都在被三方库的 API 问题坑。GPT 在面对这类任务,会大量搜索官方文档,demo。而 GLM 也搜索,但只是检索最新版本是多少,实际开发遇到的 API 也是靠试错和推理趟过去,没有再去核对文档。如果实战中配上明确的背景知识补充和提供文档,GLM 表现会好很多。
汇总起来,GLM-5.2 凭借在 GLM-5/5.1 时代的先发优势,积累了大量的 Know How和真实数据,如今是这些积累一次性兑现的时刻。从结果来看,GLM-5.2 能不能算持平 Opus/GPT,可能根据任务和场景,不同人会有不同判断,但至少大幅领先其他所有国产模型的论断是成立的,国产模型第一次在国内也拉开了代差。
如果说国内大部分程序员曾经高度依赖 Opus 和 GPT 的最强模型来完成工作,但因为渠道问题或者费用问题,无法敞开用,那么很快我们就能看到这个级别的模型因为开源而部署的无处不在,成本大幅下降,将会带来怎样令人充满期待的景象。
每当北美与国内的模型差距被拉大到让人不安的境地时,总会有一个模型跳出来证明国内还跟得上,国产不会输。而这次也正逢传奇模型 Fable-5 被禁,正应了那句话,“时来天地皆同力”,这既是智谱,也是所有相信国内团队的人的同心同力。
本文来自转载大模型观测员 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫