昨夜,全球最大的AI开源社区抱抱脸突然给一个中国模型开了“专属VIP通道”。
它 自掏腰包,为智谱刚刚开源的旗舰模型GLM-5.2,提供连续6小时的全球免费算力。
不用申请,不限地区,谁都能用,抱抱脸替你买单。
这是抱抱脸第一次真金白银地为一款中国模型做这种事。
大家第一反应都是一愣,还有这种倒贴算力的好事???然后谁不是急头白脸畅享6小时GLM最新模型呢 (美滋滋.gif)
要说抱抱脸为何这样,还得从昨天更早些时候说起。
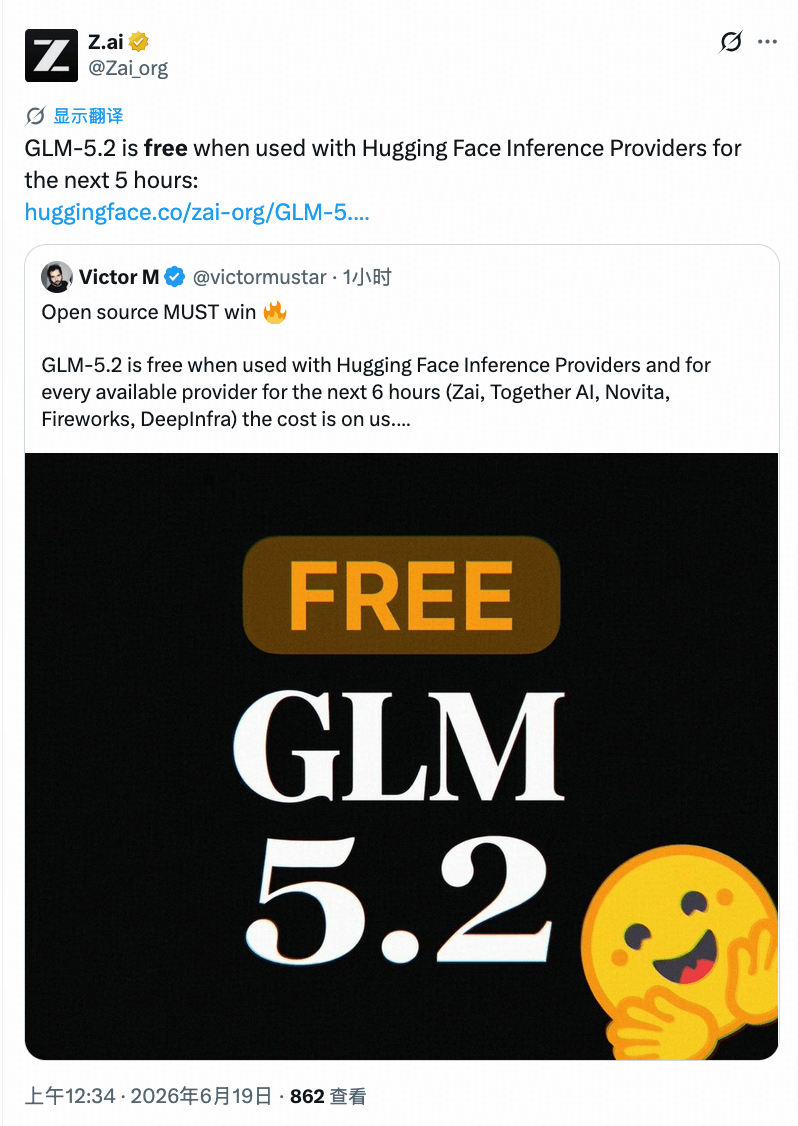
有网友在𝕏上文马斯克:“你目前对中国达到Fable级别的预计时间表是什么?GLM-5.2 无疑缩短了差距。”
马斯克很快切换预言家模式:
或许(2027年)一季度。
一些网友觉得马斯克太保守了,可能压根不用等那么久。
没想到大家冲的是同一片网, 智谱创始人兼首席科学家唐杰很快又回复了马斯克:
用不了那么久。
坦率说,这比任何一张跑分表都更能说明 GLM-5.2 此刻的位置。
那边Fable 5下线,这边GLM-5.2上桌
马斯克的这番判断恰好发生在一个很微妙的时间点。
6月9日,Anthropic发布了当时最强的两款模型,Claude Fable 5和Claude Mythos 5。
后来的离谱操作我们都知道了,总之这两款最强模型昙花一现,在四天后被下线。
一个刚刚抵达能力顶峰的前沿模型,转眼便从一部分人的屏幕里消失了。
巧不巧,智谱刚好在这个档口预告了GLM-5.2,还留下了一段意有所指的话:
在一些前沿模型突然变得不可用的时刻,我们选择相信另一条路:前沿智能不应只属于少数人,也不应被少数规则随时收回。
它应该开放、可用、可构建,并服务于每一位开发者。

6月17日,GLM-5.2正式上线。
MIT协议。
开源。
允许免费商用。
一边是刚刚下线,让全球不解的Fable 5。
另一边,是把权重、代码和商业使用权一起交到全球开发者手里的GLM-5.2……
双方格局如何,就不用我展开多说了吧。
这次拼的已经不只是跑分
GLM-5.2专为长程任务能力而生。
它支持可用的1M稳定上下文长程编程,并提出了IndexShare机制:每四层稀疏注意力共享同一个indexer,让模型在百万token上下文中,每个token的计算量降低约2.9倍。
这让模型能读下更大的工程,记住更多上下文,也更有机会把一件复杂任务从头做到尾。
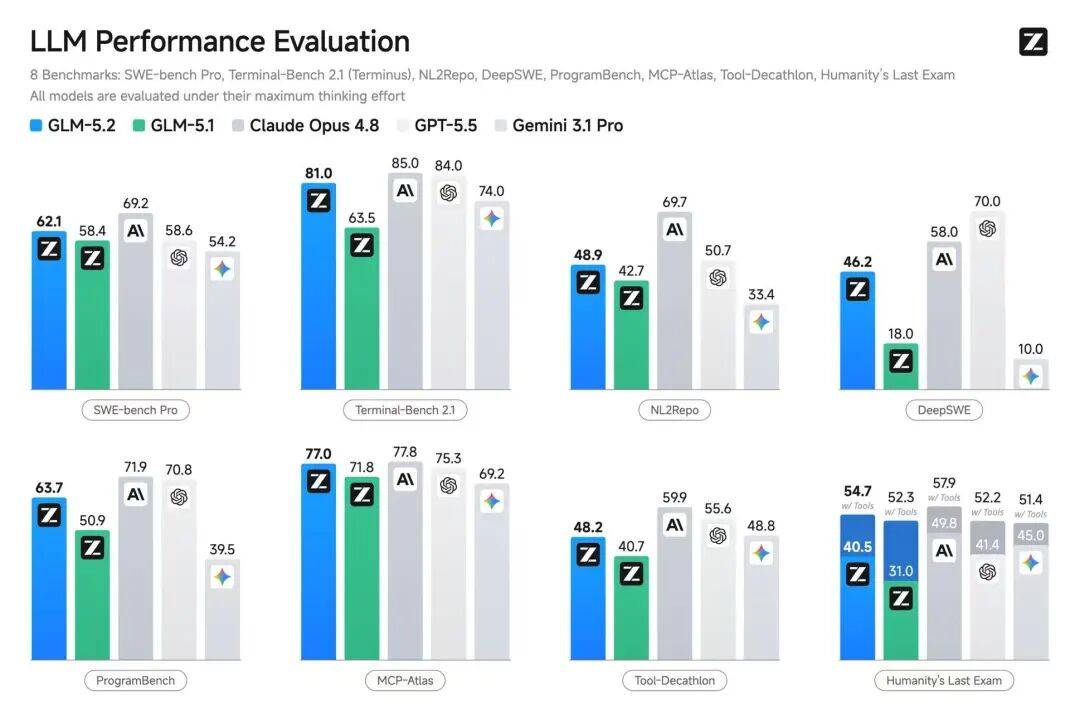
在全球百万用户参与盲测的前端开发评估系统Code Arena上,GLM-5.2取得全球可用模型第一的表现。

在Artificial Analysis综合榜单上,GLM-5.2取得51分,跻身全球模型前三,并位列开源模型 SOTA。
在FrontierSWE、Terminal-Bench等代码和长程任务权威基准上,GLM-5.2与国际顶尖模型Claude Opus 4.8的差距收窄至1%–4%。
这也代表 开源模型的代码能力第一次达到了行业认可的顶尖闭源模型水平。
另外,在主流编程基准上,GLM-5.2保持开源SOTA,与Claude Opus 4.8处于可比区间。
中国模型不再只做“便宜替代”
智谱GLM-5.2的发布是中国AI大模型阶段性发展成果的一个缩影。
中国开源模型的崛起,其实已经持续了一段时间。
DeepSeek-R1发布后的一年里,更多的中国大模型公司纷纷转向开源。
模型越来越多,价格越来越低,调用量越来越高——在OpenRouter上,中国模型的调用量已经从2024年底的1.2%,上升到超过50%。
但调用量反超,和前沿能力领先,终究是两件事。
很长一段时间里,中国模型更像高性价比平替、开源补充,或者某个单项能力很强的追赶者。
此次GLM-5.2一系列事件其实是一种趋势的缩影,它冲进了智能体编程和长程复杂任务——这些过去长期由 Claude、GPT 等闭源模型占据的核心地带。
马斯克关于中国大模型可能在“一季度”达到Fable 5水平的判断,真正值得关注是它反映出全球市场对中国前沿模型追赶速度的重新估值。
“这些中国开源模型的能力也越来越好。”
而且在美国顶尖模型在闭源基础上更加收紧开放规则的时候,GLM-5.2用行动证明,前沿能力不一定只能封闭在少数平台里,也可以被开源出来,交给全球开发者重新构建。
全球大模型竞争的格局里, 第一次出现了一个既接近顶级闭源体验、又选择开放路线的中国变量。
同样值得关注的是,上线首日,GLM-5.2即完成与华为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞等国产算力平台的全适配;此前发布的国产大模型DeepSeek V4也已完成该类国产算力生态的全栈适配。
来自中国的全栈开放生态,正在赋能全球 AI 产业实现开放包容、互利共赢的生态繁荣。
本文来自转载量子位 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫