整理丨付自文、李清旸
两位播客嘉宾,一位是 UCLA 在读博士刘益枫,他是模型架构背景,曾在 Kimi(月之暗面)和字节 Seed 实习,参与 K1.5 研发,也自己做过优化器。
一位是开源推理框架 SGLang 核心开发者赵晨阳,他是 Infra 背景,目前已加入 SGLang 背后的商用创业公司 RadixArk AI。他此前也曾在字节 Seed 实习。
这期我们从 V4 切入,自然而然聊地到了 Kimi、Seed、MiniMax、Qwen、智谱等中国其他大模型团队的努力和进展。
关于从字节 Seed 提出的 HC 到 DeepSeek 的 mHC,再到 Kimi 的 Attention Residuals 的讨论,还有 Kimi 和 DeepSeek 围绕 Muon 优化器的改进,又或者是 DeepSeek 对北大团队开源的 TileLang 的深度使用……这些成果相互联系、彼此激发,鲜活地刻画了,一定的人才密度和竞争烈度后,开源模型社区在正迸发怎样的进步与质变。
而一批中国公司,是开源大模型生态最活跃和坚定的投入者。
从 R1 的一鸣惊人到如今的百花齐放,这一年多发生了太多迭代和变化。V4 的技术报告是了解这些细致且艰辛努力的一个切片。
刘益枫:数学推理、代码能力和 Agent 指令执行都比 V3 好不少,尤其是幻觉少得多。
代码能力还是比 Opus 4.6 等闭源模型弱,和智谱 GLM-5.1、Kimi K2.6 等开源模型体验相近。
同时 V4 比 V3 大很多(V3 参数为 670 B ,V4 为 1.6T),价格贵了不少。但最近 V4-Pro 输入缓存命中的价格从最初 25% 优惠上又打了 1 折,降价很猛,这让很多用户愿意尝试。
晚点:正好这几天正在开 ICLR (国际学习表征会议,International Conference on Learning Representations,AI 顶会之一), 大家在会场是如何讨论 V4 和同期进展的?
刘益枫:有意思的是,V4 放弃了从 V2 到 V3 使用的 MLA(注:多头潜在注意力,由 DeepSeek 提出),而目前 K 2.6、GLM-5.1 等模型依然采用 MLA。
其实几个月前,大家都认为先进的开源模型架构已收敛到 MLA 了,接下来是一些小改进。而 V4 放弃 MLA、重回 MQA(注:多查询注意力 Multi-Query Attention,是相比原始注意力更低显存占用和更低推理带宽的一种改进),这说明模型架构还有很大改进空间。
晚点:MLA 和 MQA 的区别是什么?
刘益枫:简单来说,MQA 更接近原始多头注意力(Multi-Head Attention) 。相比 V3 的 MLA,它是一种 token-wise(词元级)的压缩机制,通过混合使用 CSA 和 HCA 实现 4:1 甚至 128:1 的大尺度压缩。这时如果继续保留 MLA,再叠加这些压缩,实现起来会相当复杂。这可能是 V4 没有继续用 MLA 的原因之一。
(注:CSA 是 “压缩稀疏注意力”,HCA 是 “重度压缩注意力”。在 DeepSeek-V4 中,CSA 是先压缩序列、再做关键选择,能从长上下文中定位关键信息; HCA 是高度压缩大量 token 信息,保留压缩后的全局感知。二者交替使用,能在大幅减少计算和显存开销时,既了解全局脉络(HCA)又能抓到关键细节(CSA))
晚点:RadixArk.AI 这次同时完成了 SGLang 压缩 token 信息对 V4 的推理 Day-0 适配和全参数 RL Day-0 适配。适配过程中,有哪些对 V4 变化的观察?
赵晨阳:DeepSeek 仍是 Infra 的巨鲸,每年他们发布都会为 infra 优化 “续命一年”。比如说去年的 MLA、DeepSeekMoE(DeepSeek 提出的一种 MoE 混合专家模型架构,最早用在 V2 中) 等,我们扎扎实实做了一年,才能在开源框架上跑得比较好。
而 V4 换了一套全新的混合注意力方案。推理侧,V4 的混合注意力、双压缩和 HashTop-K MoE,意味着前缀缓存、FlashMLA、投机解码这些链路都要重建。我们团队为接入前缀缓存和投机解码做了大量优化,拿出了 ShadowRadix、HiSparse CPU 扩展 KV,并完成了英伟达 Hopper、Blackwell、Grace Blackwell、AMD、NPU 的全平台适配。
(注:HashTop-K MoE:哈希路由混合专家模型。DeepSeek-V4 在前几层 MoE 模型中引入的新型路由策略。不再依赖模型计算亲和度,而是直接通过输入 Token 的 ID 计算哈希值来固定分配专家。
FlashMLA:DeepSeek 开源的针对 MLA 的高效推理算子库,专为英伟达 Hopper 架构 GPU 优化。
Blackwell:英伟达最新一代的 GPU 微架构。
Grace Blackwell:英伟达推出的一种新型 “AI 超级芯片” 组合形态。将 Grace CPU 与 Blackwell GPU 物理封装在了一起。)
RL 侧,1.6T MoE 全参数训练对系统要求很高。六种并行策略(DP、TP、SP、EP、PP、CP)的正确性、训练与推理的一致性、indexer replay、FP8/BF16 混合采样——任何一环出错,奖励曲线就起不来。
(注:indexer replay:在任务被中断后,通过直接回放历史执行轨迹或复用已有的 KV 缓存来恢复状态,避免冗余计算。
奖励曲线:大语言模型在强化学习阶段的核心监控指标,反映模型在特定任务上的表现提升过程。)
晚点:总结来说,你们觉得 V4 是一个怎样的成果?
赵晨阳:作为工程师,我惊叹于 DeepSeek 极强的工程能力。训练时把优化器换成 Muon(矩阵级别优化器 ,能对整个参数矩阵进行正交化处理),训练精度推进到 FP4,进一步压缩显存和带宽;推理时引入 DSA(DeepSeek 稀疏注意力)、DeepEP(DeepSeek 通信效率的底层基础设施库)、Mega MoE 这一整套 Infra。这里面的每一个名词,在工程上都是巨大挑战。这种系统级的耦合优化比单点创新更难,更体现一个团队的工程深度。
刘益枫:作为算法研究人员,我更佩服 DeepSeek 的艺高人胆大。不仅引进了 mHC(流行约束超连接)、起始层哈希路由等技术,还大胆使用了 CSA 和 HCA 等 token-wise 的压缩技术,创新性使用了不同于一般实践的 Muon 超参数,甚至放弃了既有的 MLA 架构。同时一如既往地在并行训练、训练精度调节等方面给业界带来新东西。
赵晨阳:OpenAI 或 Anthropic 的版本号更像 “产品语言”:频繁更新是因为庞大的用户群需要持续感知模型进步。DeepSeek 版本号更像 “研究语言”,每次主版本更新都对应一次重大架构变化。
这种差异由组织结构和商业模式决定。前者要求研究与产品节奏高度咬合,后者则拥有更大的自由度集中力量办大事,但也要求每次出手都足够有分量。
刘益枫:模型版本命名有两种派别。DeepSeek、Kimi 的大版本号代表模型结构的重大改变;而 Claude、GPT 等模型的大版本号更多代表功能、能力改变,比如 GPT-4 融入了多模态能力、GPT-5 提高深度推理能力。
这背后也反映做模型的两种不同倾向:中国的开源模型更追求工程优化;美国的闭源模型更追求提出和开辟新的能力方向。
晚点:为什么 V4 的训练时间比预期更长?据我们了解,DeepSeek 原本希望春节前后发 V4。
赵晨阳:具体发布计划外界无从知晓,但从技术上可以推测,V4 一次性引入了至少四个互相耦合的新东西:混合注意力、mHC、Muon 优化器和 FP4 训练。任何一个单独上线都需要大规模 debug,四个一起上的复杂度更是组合式爆炸。
特别是在如此大规模的 MoE 上稳定地跑 Muon,以及真正跑通 FP4 训练,这都是非常前沿的尝试。
这次 V4 博客里的一句话很好:“率道而行,端然正己。” 我还想加上《道德经》里我很喜欢的一句话:为而不恃,功成弗居。创造万物却不占为己有,功业成就却不自我夸耀。
刘益枫:这次的一个亮点是 DeepSeek 原生支持国产芯片。从零开始为国产算法编写优化算子的工程量比较大,这可能是他们开发时间偏长的原因。不过在 V4 训练阶段,外界普遍推测他们用的仍是英伟达芯片。
(注:V4 技术报告第三节 “Infra” 一章中提到,DeepSeek 在华为昇腾芯片上验证了细粒度并行 EP 方案的技术可行性,这说明 DeepSeek 做了国产芯片的推理适配。原文为:We validated the fine-grained EP scheme on both NVIDIA GPUs and HUAWEI Ascend NPUs platforms.)
晚点:晨阳提到 “率道而行,端然正己”。他们引用的是荀子《非十二子》,前面还有两句——“不诱于誉,不恐于诽”,不被赞誉裹挟,也不惧质疑和批评。
刘益枫:从 DeepSeek 的致谢名单来看,离职人员比例大概在 5% 左右。相比其他公司,这个流动率挺低。所以我觉得 “不诱于誉” 不仅是公司理念,也是 DeepSeek 研发人员的心境。
赵晨阳:“举世誉之而不加劝,举世非之而不加沮”,是一种很高的境界。
晚点:这次技术报告和发布推文中都没再公布训练成本,为什么?V3 和 R1 引爆市场的关键之一就是 557 万美元的最后一次训练成本。(注:按参数量和训练数据量粗略估算,V4 的训练计算量可能接近 V3 的 3 倍)
赵晨阳:这是一个信号,DeepSeek 不再靠 “成本叙事” 定义自己,而是用模型能力说话。
刘益枫:最后一次训练成本往往是总成本的几十分之一。前沿探索和对比验证的实验成本,人力和数据成本才是主要开支。所以公布这个成本本身没太大意义。
晚点:R1 当时爆火的另一个原因是,它以开源方式验证了测试时扩展(test-time scaling)的新范式。而这一次,V4 是不是并没有带来这个级别的范式变化?
赵晨阳:R1 是开源世界里第一个走通 Long Reasoning 这条路的模型。V4 也是 follow 了 R1 的范式,定位是 “在这个范式下解决计算瓶颈”。
我觉得 “范式变化” 在 AI 圈被说得太多了,它本来是十年一遇、甚至更稀少的事。Transformer、scaling law、RLHF(基于人类反馈的强化学习,一种对齐方式)、测试时扩展,这些是范式。但每隔半年就要找一个 “新范式” 的行业恐怕有些问题。
更值得问的问题是:沿着现在的 LLM 范式继续优化,还有多少空间?上限在哪儿?
我判断还有相当大的空间,但每一步都更难。V4 这种系统级耦合的工程优化,会成为接下来一两年的主旋律——大家会竞争谁能把许多分散的优化做成一个能跑起来的整体系统。这很工程,但商业价值很大。
刘益枫:与其从方法论的角度解释范式变化,不如把它理解为一个新的模型能力领域,比如之前的长文本能力、agent 能力、幻觉控制能力等。
提出新的能力领域,这才是目前大语言模型需要重点做、不断做的事情。现在的问题不是 “能不能做到”,而是 “我们还不知道有哪些需要做的”。
从这一点来说,V4 带给我的震撼远不如 R1,甚至不如 Kimi 最早提出长文本能力时带来的感受。
晚点:那你看到了什么现在还在萌芽、未来可能重要的能力方向?
刘益枫:比如 AI 的 “自我意识”。目前 AI 还是人类的工具,它是否能拥有自己的意识,更自主地行动?
赵晨阳:我认为有个重要的能力是 “减少推理量”。很多事情并不需要那么多推理,token 应该用在更重要的事情上。现在的模型有点儿被 infra 优化惯坏了,在上下文长度上太铺张浪费。
赵晨阳:V4 明显测了更多和 agentic 相关的 Benchmark,尤其强调工具使用、多步规划等。整个行业从去年年中开始就有这个转向:做事和完成任务比 “答得对” 更重要。
这里也正好解释一下,Benchmark 大概有几种逻辑:一是离线 Benchmark,测一个问题模型怎么回答,给答案打分;二是在线 Benchmark,把同一个问题或任务发给两个匿名模型,让用户判断哪个模型更好,这通常被叫做 Arena(竞技场)。
DeepSeek-V4 的技术报告里就提到,他们做了一个内部在线评测:公司里的工程师可以自行选择模型完成任务、给模型反馈。他们比较了很多模型——Claude Opus 4.5、4.6,OpenAI GPT-5.5 等。V4 的分数大概在 Opus 4.5 左右,和 Opus 4.6、GPT-5.5 还是有差距。有 9% 的 DeepSeek 工程师表示,不会将 V4-Pro 作为首选模型。这很坦诚,公司内部的采用意愿非常重要。
这也引出另一个问题,可能是所有优化编程能力的模型团队都要思考的——这世界上只有极少数的公司在编程上有数据飞轮,而获取数据的最佳方式是 “被使用”。
刘益枫:关于数据飞轮,我有个问题想问晨阳。美国以闭源模型为主,中国以开源模型为主,这是否意味着,很多用户可能会自己部署开源模型在本地使用,中国团队更难获取实际使用数据?
赵晨阳:其实不是的。开源模型上了万亿参数规模后,部署成本很高,个人无法负担,个人不可能有 H200、B200 或 910B 这种 GPU。大多数模型哪怕开源,也是 host 在第三方云上,本质还是走 API,在第三方会留下痕迹。不过据我所知,国内还是大量在用美国的闭源模型(来编程)。
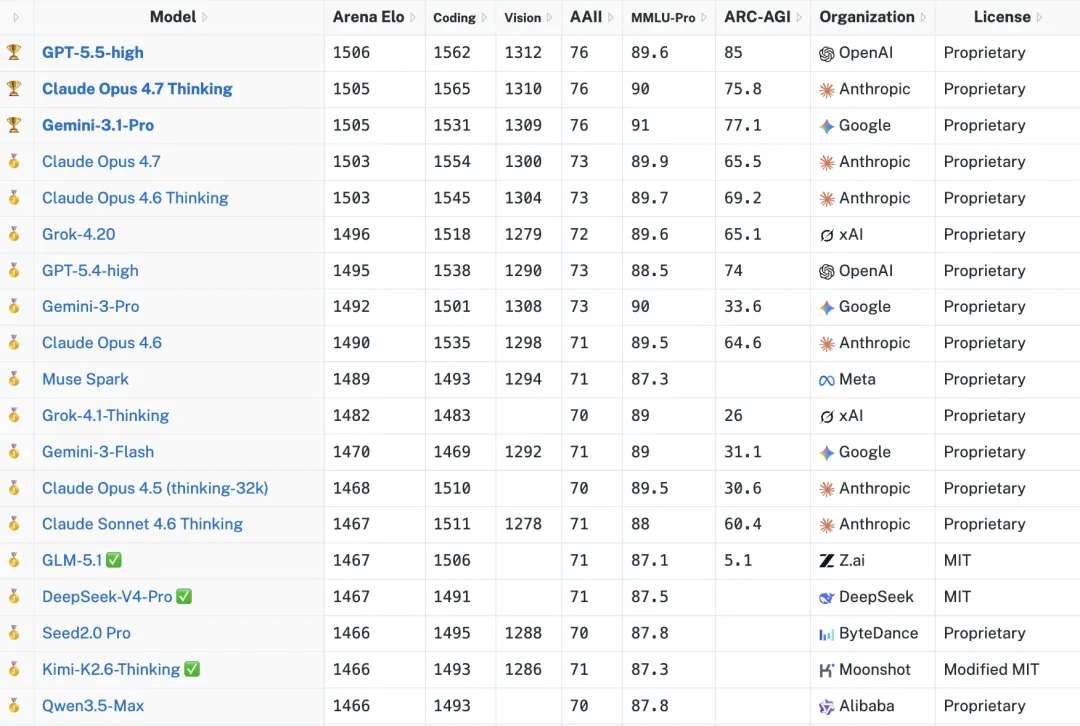
刘益枫:目前 Chatbot Arena 上 DeepSeek-V4-Pro 排名大概在 23 ,比 GLM-5.1 和 K2.6 等都低;在 Artificial Analysis 的 Intelligence Index 的分数为 52 ,也比 Kimi、Mimo 低。晨阳怎么看这个表现?
(注:访谈发生于 4 月 28 日,到 5 月 1 日,V4-Pro 在 Chatbot Arena 上的排名为超越了 K2.6,仍低于 GLM-5.1。)
刘益枫:确实,刷榜不是目的。
赵晨阳:体感上,一流模型的能力已经很难区分。在非常微小的差距里排先后意义不大。
我一直用 Claude Code,有一天我们公司的 Claude 因账单原因被下线,我就去用了 Codex。我发现,离开了 Claude,外面的世界完全没有下雨。
晚点:前面我们讨论了性能,效率上,V4 技术报告里提到:在百万级上下文中,DeepSeek-V4-Pro 的单 token 推理 FLOPs(衡量计算量,对应计算资源) 是 V3.2 的 27%,KV 缓存占用(对应存储资源)是 V3.2 的 10%。这个效率提升程度属于行业正常水平还是比较惊人?
赵晨阳:V3.2 发布时,DeepSeek 提到,即便大幅降价,他们自己的推理服务仍有利可图。
不过需要注意的是,这种提升有一个重要前提:上下文越长、优势越明显。如果只是几千 Token 的输入输出,效率提升并不显著。当然,现在的实际使用中,几千 Token 可能连 system prompt 都打不住,所以日常使用的感受应该挺明显的。
晚点:这是不是也意味着,V4 的效率优化对 Agent 场景很有用?因为处理多步复杂任务的 Agent 框架是需要很长上下文的。
赵晨阳:是的,Agent 会很有收益。
刘益枫:不过,也有用户反映,V4 在解决同一个问题时,token 消耗比之前要大了。这部分抵消了效率优化的体感。
晚点:这就是晨阳刚才说的他认为需要提升的能力 “减少过度推理”。为什么模型更新后,解决同一问题的推理 token 消耗反而变多了?
赵晨阳:我之前在小红书发过一篇文章,说现在的 token 浪费有种 “拿高压水枪浇花” 的美感。
模型会诚实地反映训练数据,token 消耗变多,说明在训练中确实存在用更长上下文解决相同问题的情况,这些吐出来的回答可能又成为训练的材料,这就形成坏循环,解决同一个问题需要的 token 越来越多。
刘益枫:其实这个问题一直存在,之前大家就在想解法,比如 K1.5 的报告里的 “长度惩罚”,当回答同一问题时,会惩罚更长的回答。但即便如此,这个趋势仍不可逆地发展,因为对各个团队来说,优化模型解决问题的能力还是会优先于优化推理的简洁。
晚点:DeepSeek-V4 仍然是一个 MoE 模型,但前面也提到,这次模型架构和 Infra 都有较多变化。你们怎么理解 V4 的整体架构思路?
赵晨阳:V4 整体保留了 DeepSeekMoE 框架和 MTP (Multi-Token Prediction,即 “多 token 预测”,允许模型一次性预测多个 Token)策略,但在四个层面做了改造:注意力,用了混合稀疏注意力;残差,使用了 mHC;优化器,在这么大的模型规模上使用了 Muon;以及 infra 的变化,其中两个关键词是 TileLang 和 FP4。
这四件事的共同主题是:让 1M 上下文从 “理论可行” 变成 “成本可接受”。
刘益枫:V4 进一步提高了稀疏比,这对算法和底层算子开发,尤其是训练阶段的算法和算子提出了相当高的要求。它需要保证 MoE 的各专家之间训练程度的平衡及 token 路由的平衡。
另外一个创新是在前几层 MoE 中用了哈希路由,来分配 token 到各专家,从算法上避免前几层专家路由高度集中的问题。
此外,DeepSeek 这次没有在 V4 上应用 Engram(DeepSeek 2026 年 1 月提出的条件记忆技术)。一方面可能是因为 Engram 对性能的提升有限,但对部署又有较大挑战。另一方面,基础模型在训练过程中也会自动学习 N-gram(连续 N 个 token 组成的局部片段,可以理解成一些常见表达、固定搭配,模型训练中会自然学到这些短程上下文) 能力,Engram encoder 更多起到辅助和信号加强作用。
赵晨阳:这次 V4 的激活比(激活参数比模型总参数)确实是这一波模型里最低的。V4-Pro 是 1.6T 总参数下,激活参数 49B,也就是约 3%,比先前已经很低的 Kimi K 2.6 更低。
总参数越大、模型容量越高;激活参数越小、推理成本越低。MoE 的核心价值就是把这两个量解耦,而 V4 把这种解耦推到了目前业界最激进的位置。
晚点:正好这里补充一组数据,在激活参数比总参数的比例上,DeepSeek-V4-Pro 刚超过 3%,而 V3 时是 5.5%。其他近期模型中,K 2.6 是 3.2%,MiMo-2.5-pro 是约 4.1%,MiniMax M2.7 是 4.35%,GLM 5.1 是 5.3%。
当然,激活比也不是越低越好。比例太低会带来负载不均、专家训练不充分、路由抖动等问题。DeepSeek V3 就讨论过,路由负载均衡是否应该纳入 loss(损失函数)。能把 3% 的激活比例稳定训下来,本身是工程能力的证明。
注意力机制:CSA 和 HCA 如何组合工作
晚点:2025 年年初 DeepSeek 提过 NSA(原生稀疏注意力),同年 9 月又在 V3.2 上用了 DSA,这次则是使用了组合 CSA 和 HCA 的新的混合注意力机制。这次的核心改进是什么?主要解决什么问题?
刘益枫:V4 的每一层都同时跑滑动窗口注意力(SWA)和一种长距注意力(CSA 或 HCA)。CSA 是稀疏路线,在序列维度做 4:1 压缩后再做 top-k 选取;HCA 更激进,做 128:1 的压缩,但保持稠密注意力。(4:1、128:1 是指把 4 个 token 聚合成一个表示和把 128 个 token 聚合成一个表示,所以说 HCA 的压缩更激进)
每层用 CSA 还是 HCA 是预定义的,因此面对同一个长上下文,不同层会从不同视角去看——稀疏层(CSA)精确锁定关键 token,稠密层(HCA)提供整体语义概览。
晚点:这套新的注意力机制对 Infra 的影响是?
赵晨阳:改动还是挺大的。对 RadixArk 和 SGLang 来说,适配这个混合方案的复杂度主要是前缀缓存的一致性。所以我们设计了 ShadowRadix 来应对——三个异构 KV 池(SWA / C4 / C128)加两个压缩状态池,要在预填充、解码、投机解码三个阶段保持同步。这是 V3 时代不需要解决的问题。
(注:预填充,Prefill,指在推理的初始阶段,模型一次性并行处理用户输入的整段 prompt,计算并生成已知文本的 KV 缓存,快速吃透内容。
解码,Decode,是常规生成阶段。模型用预填充阶段产生的缓存,开始自回归地生成回答,一般解码是逐个 token 吐出的,这是推理的速度瓶颈。
投机解码,Speculative Decoding,是加速解码的技术。它不再逐个 token 生成,而是一次性 “猜” 出多个未来的 token 并交由主模型批量验证,可大幅提升速度。)
此外,我们最近发的 HiSparse 把稀疏注意力的 KV 卸载到主机内存,在长上下文场景能拿到 5 倍吞吐。V4 这种把计算 / 显存成本压到 27% / 10% 的模型,要在生产环境跑出商业价值,就需要 ShadowRadix、HiSparse 这类底层能力的同步推进。
优化器:Muon 已成检验大模型团队工程能力的试金石
晚点:V4 里还有两个很重要的变化,一是残差上,使用了 DeepSeek 去年底提出的 mHC,一是业内现在已用得比较多的 Muon。
先说优化器。过去大模型训练的主流优化器是 AdamW,但从去年到今年,Muon 开始被越来越多的前沿模型采用——OpenAI 在 2024 年底招募了 Muon 的开发者 Keller Jordan;Kimi 2025 年年初开始发布 Muon 的改进版。能否先简单解释一下,优化器在大模型训练里起什么作用?Muon 相比 AdamW 的核心优势是什么?
刘益枫:一般深度学习网络的训练过程,就是让模型通过损失函数的梯度下降信号不断更新权重,当权重更新到一个状态,模型能稳定达成设计目标了(比如预测),就是训完了,得到了稳定的权重。
但由于模型结构、数据分布等差异,普通梯度下降不太适合大语言模型这类深度神经网络,所以后来出现了 Adam、AdamW 等带动量和预条件机制的优化器来帮助训练。
AdamW 本质上结合了动量和更新量归一化两类技术。动量可以让更新更平滑,归一化可以让每一步更新的 scale 更统一,从而稳定训练。但 AdamW 是元素级别的优化,也就是对每一个参数单独更新。
Muon 的核心区别在于,它是矩阵级别的优化。对于线性层这类二维参数,它本质上是矩阵乘法,Muon 会把整个矩阵作为整体进行归一化和优化,这能更好地利用矩阵中不同元素之间的联系,让矩阵内不同元素的优化步调更一致,进一步提升训练效率和推理能力。
晚点:从 Keller Jordan 在 2024 年 10 月提出 Muon 到它后来变得更主流,这个过程是怎样的?
刘益枫:2024 年底 Muon 刚被提出时,对使用者并不友好。它需要针对不同模块,如线性层、输入嵌入层分别调学习率(learning rate,控制模型每次更新参数幅度的核心超参数,太大容易不收敛,太小则训练极慢),我们当时也第一时间跟进了。
到 2025 年初,Kimi 提出 Moonlight 的改进。因为 Muon 是基于矩阵更新的(矩阵是二维的)所以训练时涉及一维参数的部分仍会用 AdamW,这就有一个二者之间的学习率的比例问题。
最初 Jordan 没有确定 Muon 和 AdamW 的学习率比例。Moonlight 的重要贡献是把这个比例基本确定为 0.2,这样使用者只需设置一个学习率超参数就能适配整个模型。这让 Muon 从理论创新走向了大规模应用。
晚点:可以说,是 Kimi 的 Moonlight 和 MuonClip(在 2025 年年中的 K2 中,Kimi 进一步改进 Muon 的版本)改进让业界开始更广泛使用 Muon 了?
刘益枫:对。DeepSeek V4 的进一步改进是,它没有用 Kimi 找的超参数 0.2,而是自己算了一个更精确的 0.18。
Muon 最开始用的是牛顿-舒尔茨五次迭代(一种用于矩阵归一化或求逆的数值迭代方法),这是一个近似过程。而 V4 采用了十次迭代近似。每多一次迭代会提高计算消耗,但精度会更高,整体速度可能反而更快。
晚点:优化器的变化需要 infra 上做什么调整和配合?
赵晨阳:推理侧不需要关心,因为不涉及参数更新;训练侧一定要做适配,而且是大工程,整个开源链条要从英伟达的 Megatron 或 Megatron-Bridge(英伟达发布的工具库,主要用于在 Hugging Face 和 Megatron Core 格式之间无缝转换大模型权重,并提供高性能分布式训练框架)这一层开始改,再一层层往下传。闭源训练引擎怎么实现 Muon 我就不清楚了。
刘益枫:Muon 是矩阵层面的优化,会涉及大量矩阵乘法。如果某个矩阵很大,就需要大量拆分,甚至分布式训练。AdamW 不一样,它是每个元素单独更新,元素本身可以无限拆分。所以这是 Muon 特有的 infra 问题。
另外,预训练和后训练的优化器基本要保持一致。而后训练的 infra 结构更复杂,可能单机装不下,所以后训练适配 Muon 会带来更多结构修改。
晚点:现在还没有用 Muon 的大模型,是认为 AdamW 仍有优势,还是没来得及改?
刘益枫:大部分模型都改用 Muon 了,但也有一部分不太清楚。比如千问就没有特别提及用的什么优化器。
我个人认为,没改的是没来得及改。尤其是后训练要如果要用 Muon,infra 会很难改。后训练没改成,又会导致预训练就也只能用 AdamW。
晚点:是否使用 Muon,是现阶段判断一个模型团队 infra 能力的指标之一吗?
刘益枫:可以这么说。但即便是用 Muon 的模型,在输入和输出这种模块还是得用 AdamW。
赵晨阳:我非常认可益枫说的,优化器是检验一个团队工程能力的试金石。
但关于 AdamW 需不需要拆分倒不一定,这取决于模型体量。模型大到一定程度,不可能完整部署在任何一个节点上,所以 Muon 和 AdamW 都需要复杂的并行策略,Muon 只会更复杂。
AdamW 会同时维护动量和速度两个 state,很多操作是元素级别(element-wise)的,切分相对简单。比如 ZeRO stage(显存优化技术)、FSDP(将模型参数、梯度和优化器状态完全打散分配到整个 GPU 集群中的训练技术)、TP 对齐(确保被切分的矩阵维度大小能够被参与并行的显卡数量整除的技术) 的逻辑都更简单。
Muon 的优势是砍掉了二阶动量,optimizer state (优化器在更新权重时需要持续记录的内部历史数据)从两倍降到一倍,能节省相当多显存。但它在动量上跑完牛顿-舒尔茨迭代后,还要做正交化。这就不是逐元素过程了,而是更复杂的矩阵计算,必须拿到完整的二维权重。如果参数已经被 TP 或 FSDP 切碎,就要先聚合回来再计算,涉及很多分布式原理。所以可以看到,Kimi 的 K2 只在数据并行(data parallelism)层面做切分,没有在张量并行上做切分。
现在优化器层已经进入一个非常混杂、复杂的状态,有 Muon 也有 AdamW。Muon 不是简单替换 AdamW,而是用大量人力和工程复杂度换取大量显存和收敛效率。这笔账值不值得,取决于团队的工程水平、显卡数量和模型规模。
刘益枫:而这里每个专有名词背后都可以对应一篇文章。
残差连接方式:Seed、DeepSeek、Kimi 的激发与碰撞
晚点:聊完优化器,来聊聊 V4 的残差连接方式。这次 DeepSeek 引入了 mHC,这是一个怎样的改进?
刘益枫:mHC 之前,字节 Seed 先提出了 HC(Hyper-connection,超连接),思路是扩展层与层之间的信息流宽度。以前的 Transformer,层之间只有 d 维的信息流宽度;但现在是 d 维上加了 channel 维,信息流宽度变成 d x c,推理能力显著提升。
不过原本 Hyper-connection 的数学原理导致梯度回传和训练不稳定,所以 Seed 发了这个成果后,社区反响并不强烈。
而 DeepSeek 的 mHC 加入了 Sinkhorn 算法(一种数学归一化算法),主要用于约束路由和注意力分布,使其更均衡、数值更稳定,能在一定程度上改善训练过程的稳定性。
这个改进既需要对 HC 的潜力判断和细致分析,又需要基于内观指标,如梯度的 scale、激活值,从现象倒推怎么解决这个问题。
补充一点,Kimi 也刚刚在 3 月初提出了 Attention Residual,它有点像 DenseNet(主要用于 CNN 卷积神经网络的一种密集连接结构,每层与之前所有层直接连接),直接跨层相连,第一层可以直接影响最后一层。
mHC 和 Attention Residual 方法不同,但有异曲同工之妙——都是 layer-wise(层级别)地改进信息流。
晚点:这两种方法的区别是什么?你认为哪种上限更高?
刘益枫:实验室更倾向搞 mHC,因为资源有限,mHC 的 Infra 实现更简单。
Attention Residual 对 Infra 的要求更复杂,它对每层之间关系有一个更精确的描述,我认为它的上限可能更高。
晚点:mHC 对推理框架的影响是什么?
赵晨阳:mHC 把简单添加残差这件事变成了一个需要混合 GEMM(通用矩阵乘法,深度学习中最核心、最密集的数学操作)和 Sinkhorn 归一化的复杂操作。
带来的挑战是:先前的算子对于 mHC 不够高效,我们需要为 mHC 单独写一些新的 kernel(算子核,可以简单理解为直接给 GPU 发的指令代码,告诉芯片底层怎么做基础运算)。为新算法定制新 kernel 在 V3 之前并不频繁。但比较欣喜的是,我们现在有了更多、更好的工具,如 TileLang。
Infra 两个关键词:TileLang & FP4
晚点:正好你提到了 TileLang,接下来就是想聊 DeepSeek-V4 报告里 infra 部分使用的 TileLang 语言和 FP4 训练精度。简单来说,这两个东西是什么,作用是什么?
赵晨阳:先说 TileLang,我喜欢叫它 “太浪”,听起来像拳击大师的名字。
infra 要做的是在计算路径相同的情况下加速计算。比如写 kernel,就是结合底层硬件特性优化计算。同样一个 4096 乘 4096 的矩阵,可以按 128 拆,也可以按 256 拆。不同硬件的显存、带宽不同,适合的拆分方式也不同。总之 kernel 就是让底层的矩阵计算更快。
写 kernel 的语言,通常大家会对比 CUDA、Triton 和 TileLang:
TileLang 的长期价值是大大降低了为新算法快速开发新 kernel 的边际成本。
DeepSeek 提出 mHC 时也写到,他们为 mHC 做了一版 TileLang 的 kernel。我们 SGLang 团队也针对推理场景的小批量解码做了 split-K(把矩阵乘法中的 K 维度拆开并行计算,以提升小批量场景下的硬件利用率)的 TileLang 版本。最近一年半,TileLang 已开始被全球前沿 lab 当作算法实现的默认选择之一。
以前做编译器这一层很苦,但现在大家也看到了它的重要性。
晚点:你提到编译器和 DSL 底层语言,让我想到五年前采访鸿蒙当时的负责人王成录,他提到十年前想做操作系统时,在国内很难招到会汇编语言的人才。
赵晨阳:做编译器一直是非常伟大的事业,但也很苦、离商业远、不被关注。
晚点:TileLang 最初是北大杨智老师团队发起的,后来也有很多社区贡献。那如果 TileLang 这类开源生态越来越繁荣,和 CUDA 长期会是怎样的关系?是更丰富 CUDA 的生态还是形成竞争?
赵晨阳:很难说。就像模型厂商会发技术报告,大家彼此借鉴,但也存在竞争。
刘益枫:TileLang、Triton 和 CUDA 的关系,有点像 C++ 和汇编语言,或者 Python 和 C 的关系,是不同层级的语言,CUDA 更底层。
晚点:那 TileLang 也可以用在其他芯片厂商更底层的软件系统上?
赵晨阳:是的,事实上很多中国硬件厂商正在主动支持 TileLang 生态。
晚点:可以说 DeepSeek 在 TileLang 的投入比别人更多吗?V3.2 里就开始用了。
赵晨阳:只能说他们投入很多,但不一定比其他人更多。其他公司披露的内部技术实现有限。
晚点:这次的另一个变化是训练时的浮点数精度格式从 V3 的 FP8 变成了 V4 的 FP4。这是怎样的演进思路?
赵晨阳:FP4、FP8、BF16、INT4 等等都是数值格式,数字代表存储位宽。比如 BF16 就是用 16 位存一个浮点数,FP4 只用 4 位。
DeepSeek-V3 是第一个把 FP8 做到大规模模型上的工作,到了 V4,他们又实现了 FP4。再往下会不会有更激进的优化和压缩?非常值得期待。
减少存储位宽的好处是减少峰值算力,同时提升显存容量和数据读取效率。但位宽太小也会导致训练中梯度溢出或归零。
DeepSeek 为了解决 FP4 训练问题,在预训练和后训练上都用了很多工程巧思。我比较熟悉的是 QAT 量化感知训练(训练时模拟量化误差以适应低精度部署)。DeepSeek 在后训练里做了 quantization-aware training,即训练时模拟量化、采样时真实量化。
强化学习可以看成两个阶段:先采样,模型生成回复;再打分,把结果拿去训练。训练阶段,优化器维持 FP32 主权重,计算前先压缩到 FP4 范围,再无损反量化回 FP8 计算。这个伪量化过程没有真正前向计算,但会体现量化误差。之后再用 block-wise 的 scale points(缩放系数点,用来校准量化范围)兜住离群点(数值异常偏大的参数或激活),让模型提前适应低精度损失。采样阶段则做真实 FP4 量化,把 FP4 权重真正用于采样,降低访存瓶颈,实现物理提速。更重要的是,这和后续模型部署一致。现在 DeepSeek 发布的 checkpoint(模型权重文件)也是 FP4,训练中采样用的权重就是最终发布权重,而不是先训练 FP8 再量化成 FP4。这样损失更小,也提升了强化学习效率。
强化学习里,模型越大、token budget(单次推理可生成的最大 token 数量上限)越长,采样越重,可能占到 70% 以上时间。采样时降低位宽和显存读取压力,对速度提升很明显。所以训练时伪量化、采样时真实量化,在 DeepSeek 论文里有很强体现。Kimi 的 K2 也用了类似思路。
我们 SGLang 的 RL 团队去年也做了两个相关工作:FP8 全流程强化学习,训练和推理都用 FP8;还有 INT4 的 QAT。INT4 和 FP4 不完全一样,但也属于激进压缩方案。
实事求是地说,在开源领域,我们团队的量化 RL 做得比较领先,但和 DeepSeek 还有差距。我们的 INT4 量化感知训练,采样做的是 W4A16,也就是权重 4 位、激活值 16 位,DeepSeek 做到了更极限的 W4A8。极致性能上,他们走得更远,这也是我们接下来要继续攻坚的方向。
晚点:如果 DeepSeek 把官方推理框架开源,它和其他开源推理框架会是什么关系?
赵晨阳:这涉及开源和闭源推理框架的哲学区别。开源推理框架是众口要调,不只支持 DeepSeek,也要支持小米、智谱、MiniMax、Kimi 等模型。这种整合性,是它和闭源内部推理引擎的重大区别。
晚点:它给开发者或用户的价值是什么?
赵晨阳:最大价值是满足很多公司本地部署推理引擎的需求,而开源推理引擎的性能提升,也会反过来促进闭源推理引擎。
训练上也类似。闭源仍领先不少,但开源能让整个领域更透明。以前开源框架对 RL 的适配负担很重,一个模型 2 月上线,可能到 5、6 月才有开源 RL 框架能跑起来。这次 SGLang 在发布当天就支持了 V4 RL 适配。
RL 和推理关系很近。推理是不带参数回传的前向传播,强化学习则重在采样,采样后做参数回传。我们还是很高兴能在这么大的 MoE 模型上同时做好推理和 RL,并把一致性做到极致。
我也预见到,FP4 已经正式走出硬件厂商的 PPT,成为开源语言模型世界里真正跑通的工业标准。
晚点:目前在这么大规模的开源模型里,FP4 是不是只有 DeepSeek 用了?
赵晨阳:OpenAI 的开源模型 gpt-oss 也是,但大家技术选择不完全一致。只能说 FP4 是全世界都在努力的方向。
刘益枫:英伟达的开源模型也用 FP4 。Blackwell 卡也是支持 FP4 的。
后训练:多专家训练 + 蒸馏的后训练
晚点:DeepSeek-V4 报告最后两部分讲了训练过程,包括预训练、后训练和测评。这个部分有什么亮点吗?
刘益枫:一个亮点是预训练先分裂专家,再做 on-policy distillation(在线策略蒸馏,指在当前模型实际采样分布上进行蒸馏,而不是只依赖离线固定数据)。最近大家又都在研究 on-policy distillation,但各家做法差别很大。
蒸馏的话,之前 DeepSeek-V3 和 R1 都实践过,但 V4 是先训练一些小专家,再把这些专家学到的技能蒸馏出来,节省参数量。训练中,专家越多,容量越大,但参数量和显存要求也越高。所以先让专家学好,再提取专家精华,从而提高最终模型能力。
赵晨阳:他们做的是多专家训练,本质是在解决多目标优化问题。而同时优化目标的个数,是智力上限的体现。联合训练就相当于在多目标 loss surface(损失曲面,损失函数在参数空间的几何形状)上找 Pareto 最优(帕累托最优,无法在不损害其他目标的前提下进一步改善任意目标的状态),但工程里很难同时找到,因为梯度走向复杂,目标冲突严重。比如一味 push coding 能力,数学可能变差;数学修好了,指令遵循可能又受影响。
现在先分裂再蒸馏的做法是:在各个目标上找局部最优,再让一个学生模型拟合多个教师模型的输出分布。这有点像数学插值,把复杂 loss surface 上的联合优化,变成在已收敛离散点之间做插值,工程上更稳定可控。
业界之前也有类似尝试。Qwen 在 post-training 阶段提过 multi-stage(多阶段训练或聚合)的专家聚合,学术界也一直有模型聚合、模型 Spawn(从已有模型派生或扩展新模型)这类技术。硅谷前沿闭源模型大概率也有类似思路,只是披露有限。开源生态是这一波中国实验室对 AI 领域的实质贡献。
晚点:关于测评部分,前面已有部分讨论,还有什么补充吗?
赵晨阳:有一位 NLP 领域很知名的研究者说过一句话:We cannot optimize what we cannot evaluate,“如果一个东西我们无法评估,我们就无法优化它”。所以我更愿意把这件事叫 eval(评估),而不是 benchmark(测评)。测评面向的是具体任务,发布一两年后就可能过时。但评估永远存在。
现在评估也越来越难,因为场景越来越复杂。比如 Claude Code 更新后,常有人说某些方面变差了。我也在想,这类工具到底怎么评估一个 feature 要不要更新?因为做 Agent 的人有很多想法,每个听起来都有道理,但不可能全都满足。东西加得太多,体验反而变差。
整个行业必须把评估做好,否则很容易陷入自欺欺人的循环。
晚点:Opus 4.7 更新后,很多人还是认为 4.6 更好用。
赵晨阳:现在有个词叫 vibe checking 或 vibe benchmarking。大家已经很难判断模型好坏,只能根据有限几次对话说:以前 4.5 能做的任务,为什么 4.7 做不好?
我们已经进入 benchmark 的可信危机。很多模型在 benchmark 上都是 90 多分,但实际差异很大。所以这一代针对智能体能力的评估还没有形成共识,行业还需要更好的评估基建。
刘益枫:我觉得更重要的是发现和提出新的领域能力,比如 Agent、长程注意力能力。
晚点:V4 是不是没有提出什么新的领域能力?
刘益枫:对,这也是它没有那么令人震惊的一点。
赵晨阳:但有一点值得欣喜:这几代模型没有明显退化,之前做得好的任务,后面没有变差,这很难,代价是模型上下文长度已非常夸张。
讲到测评基准,去年 DeepSeek-V3 发布时,我有一篇 ICLR 论文,评估语言模型在 GitHub 上面对刁钻审核者,提交 PR 并合并的能力。它和数学竞赛、SWE-bench(主流代码能力基准)很不一样,这个任务在完成编码后,还要和审核者做多轮修改沟通,再把代码合并进去。
我很欣喜自己做的 benchmark 得到了更多认可,即便今年已经被刷满了,但至少成为了 ICLR oral paper(会议口头报告论文,代表较高认可度)。
比如最近我比较关注的一个基准是 ClawBench,就是评估 OpenClaw 场景下,用户对模型的满意度。我也希望到明年,这种类似个人编程助手的 benchmark 能被刷满。之后肯定还会有新挑战和应用。
美国追新能力、高定价;中国追性价比、工程极限
晚点:最近模型更新密集,从 3 月底到现在,有小米 MiMo 2.5、GLM 5.1、MiniMax 2.7、K 2.6、Opus 4.7、GPT-5.5 等等。你们觉得大家现在努力的共性是什么?
刘益枫:开源模型的方法和架构在趋同。基座基本都是 MLA,优化器也类似,之前大家用 AdamW 或者 AMSGrad(Adam 的一个变体,通过保留历史二阶矩估计的逐元素最大值,限制自适应学习率波动,从而改善收敛稳定性),现在陆续转向 Muon 或基于 Muon 微调。
在能力上,Agent 是开源和闭源模型共同重视的方向。大家发现,未来模型商业化可能更多是给 Agent 提供 token,而不是只靠订阅。
赵晨阳:到底做订阅制,还是 token by token 计费?我更倾向订阅制,同时额度用完再收 token 费。实际上大部分用户用不完订阅额度,所以订阅制可能更赚钱。
刘益枫:但很多公司转向按 token 计费,也是因为现在订阅的价格真的扛不住。高了没人买,低了又亏。
赵晨阳:这确实没有定论。比如 Claude Code 这么成功,但到底盈利情况如何?
晚点:如果今年底 Anthropic 真启动 IPO,应该能看到财务数据。现在很多视频生成产品是你说的订阅加实际消耗,订阅满额度后再额外买积分。影视从业者有刚需,客单价也比想象中高很多。
赵晨阳:商业上我很喜欢视频生成的生态。但坏消息是,开源视频生成模型和闭源差距很大。
晚点:好像也没有太多人愿意开源视频生成模型,这是不是侧面说明它确实挺赚钱?迄今比较先进的开源视频生成模型仍是阿里的通义万象。
赵晨阳:我最近做语音生成模型,也发现开源模型相比 GPT-4o 那个时代的模型仍有不少差距。这些模型可能是很赚钱。
刘益枫:视频模型用户粘性也特别大。相比语言模型,视频生成模型可能更适合订阅制。
晚点:现在关注度基本被 coding、通用 Agent 吸走了,因为竞争焦灼,也都是大公司。但视频或更广义的 AIGC 可能更创业友好。语音也是,像 ElevenLabs 也在自己的空间里持续发展。以上是各家大模型的共性。那你们观察到各家的差异是什么?
赵晨阳:开源模型里,DeepSeek 和 Kimi 取向比较接近,工程和创新性都做得比较极限,比如大 MoE、低激活、长上下文和极致成本优化。
GLM、Qwen、MiniMax 则在 RL 训练端、长上下文落地上有扎实积累。还有小米,MiMo-V2.5-Pro 在 Arena 上的分数比 V4 还高。竞争非常激烈,当然这也给开源推理引擎带来很大工作量。
晚点:阶跃和混元呢?
赵晨阳:阶跃在多模态上发力很早,而且我认为多模态远没有饱和。
混元最近由姚顺雨掌帅,新模型虽然还不在 1T 以上模型的牌桌上,但在 300B 规模上做得很扎实。现在是 3.0 Preview,如果之后上 Pro、进微信端,格局会很有意思。
晚点:中美之间的区别是什么?
刘益枫:总体来说,美国模型更追求领域创新,比如长上下文、多模态融合、Agent 能力,或者像 OpenAI 刚发的 image-2 这种跨跃性能提升。
中国模型更侧重性价比。同等能力下,中国模型收费比美国模型低一个数量级。这和中国充足的技术人员储备、有限的算力资源都有关。
赵晨阳:我之前在 Amazon AGI SF Lab 实习过,也和益枫在字节 Seed 实习过。美国这一代模型的重点是面向智能体的长程任务能力,比如 Claude Code,在多轮 agentic coding 上进步很大。可以想见 RLHF、RLAIF(基于 AI 反馈的强化学习,用 AI 生成的评价或偏好信号来训练、对齐模型)这些对齐方法经过几年积累,已经形成很强的数据闭环。
中国团队的强项是架构创新密度和工程完成度。V4 报告里一次性把混合稀疏注意力、mHC、Muon、FP4、TileLang 这么多事情全部换掉并跑通,这种决心和执行力很罕见。中美路径和风格不同,但行业在螺旋上升。
晚点:美国模型好像没有做得那么稀疏,他们不太追求这个。
刘益枫:美国算力相对多,也不一定要这么稀疏。太稀疏会牺牲一些能力上限。
赵晨阳:这也和美国缺少高质量的工程人才有关。
晚点:所以美国 AI lab 更倾向于先冲性能。反正模型贵也有人买,之后再考虑降成本。
赵晨阳:对。很多人批评中美大搞 AI 竞赛,但我觉得很遗憾,只有中美能搞竞赛,没有其他国家玩得起这一波比赛了。
晚点:V4 或最近这些新模型,会对你们接下来的研究方向和具体工作产生什么影响?
刘益枫:如果在公司实习,我会想做 CSA、HCA 这类 token-wise 压缩的长文本方向。但实验室资源有限,很难做长文本,所以我倾向研究 Hyper-Connection、 Kimi 的 Attention Residual。这可能类似从 ResNet(残差网络,通过跨层捷径连接缓解梯度消失问题的经典视觉架构)到 DenseNet 的变化。对 Transformer 架构来说,也可能会出现提高层间信息流动的新趋势。
另外我也在做优化器。DeepSeek-V4 采用了不同超参数。Muon 怎么进一步改进、超参数怎么设定,都值得研究。Keller Jordan 的五步牛顿-舒尔茨迭代,和 DeepSeek-V4 的十步牛顿-舒尔茨迭代哪个更好,值得继续探索。
赵晨阳:我之前的一个研究是评估多轮 Agent 在 GitHub 上提交 PR 时的真实表现。现在我需要把它用起来。因为维护开源工具时,会收到很多 AI 生成的 PR,我需要把研究里的标准内化到工作中,判断哪些 PR 靠谱、哪些应该毙掉。
另外我最近做语音模型,它的工程优化比语言模型差很多,很多语言模型里的工作都可以在语音模型上重试一次。DeepSeek 这版做了很优秀的 PD 分离(Prefill-Decode 分离,将计算密集的预填充阶段与访存密集的解码阶段分配到不同硬件以提升整体吞吐)、MTP 等工作。语音模型未必用得上 PD 分离,但 MTP 很关键。比如现在和豆包语音对话,它语音吐出的速度很快。但开源模型在这方面还没做到这么好。
晚点:最后想问两位,再过一两年来看,V4 最可能被记住的是什么成果或者思路?
刘益枫:从算法层面看,可能是 token-wise 的极致压缩。之前大家更多是在 KV-cache 上做单 token 降维,比如 MLA 的先降维再升维。但 token-wise 压缩,应该是 V4 首先应用到了工业级模型上。
赵晨阳:我和益枫观点类似。长上下文、极致低激活比例、低单 token 成本这个组合,无论从架构层面还是基础设施层面看可能都是 V4 的持久遗产。
具体到 mHC 或混合注意力,未必会一直以现在的方式。它们可能像 MLA,是某个阶段的最优解,过一两个周期后会被更优雅的方案替代,当然硬件也会反过来推动迭代。
但 DeepSeek-V4 率先验证的这套工程配方,会成为后续很多开源大模型的默认起点。在这个意义上,DeepSeek 一直是开源模型的参考基准。
本文来自转载微信公众号“晚点LatePost” ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫