短的结论:能说会道的小天才
基本情况:
字节 Seed 团队在春节发布的 Seed 2.0 Pro 可谓是当时智力巅峰,但发完之后便进入了静默期,苦练内功解决模型的实际动手能力去了。等待近 3 个月之后,并没有等来传说中的 Seed 2.1,而是作为先行的 Seed 2.0 Lite。
Seed 发力多模态已经一年有余,Seed 系列模型一直是多模态方面的国内标杆,在国际上也属于第一梯队,与 Gemini 互有输赢。这次的小体量的 Lite 版本基本继承了大哥 Pro 的多模态能力,并进一步发展。
在逻辑思考能力上,Lite 虽然离大哥 Pro 有差距,但在同梯队中能做到综合成本最低,但受限于日益紧张的算力资源,Lite 这次也没有跑出小体量模型该有的速度。
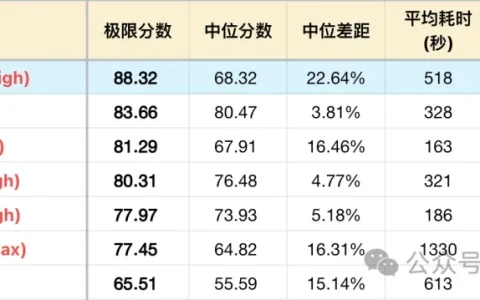
逻辑成绩:
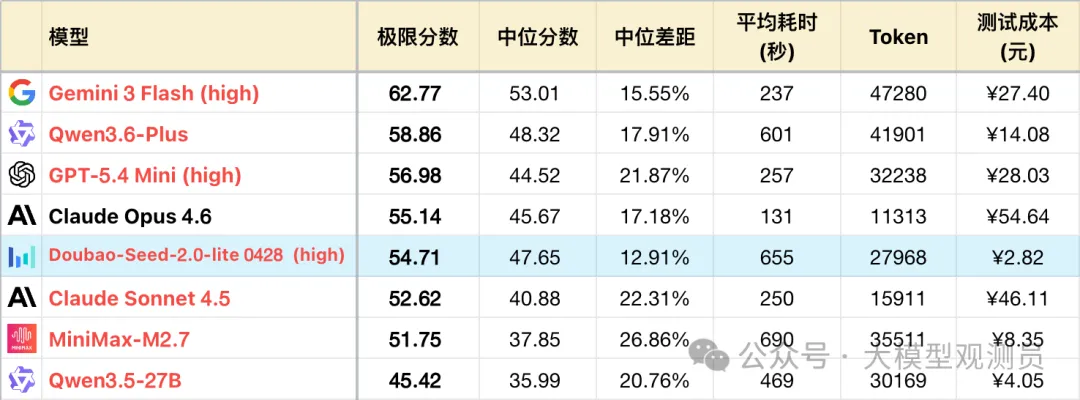
*1 表格为了突出对比关系,仅展示部分可对照模型,不是完整排序。
*2 题目及测试方式,参见:大语言模型-逻辑能力横评 26-04 月榜,额外新增#63,#64,#65 三题。
*3 完整榜单更新在 https://llm2014.github.io/llm_benchmark/
*4 红字模型代表工作在推理模式下(慢思考),黑色模型则是对应的非推理模式(快思考)
下面取与其能力相近的GPT-5.4 Mini 作为对照模型,同时参考 Seed 2.0 Pro (简称Pro)的表现。
优势:
- 多步推理:Pro 在多步推理上有着惊人表现,但奈何思维效率不高,经常会花费额外数千 Token 进行答案确认,而 Lite 从 Pro 中学到了大量的高效思考技巧,并做出有效改进。在输出结果相同的任务上,Lite 使用 Token 平均仅有 Pro 的 80% 左右,但不绝对,也存在反面使用略高的情况。在中等难度的任务上,Lite 基本可以做到和 Pro 相同,并且稳定性甚至略高一些,这与官方 Benchmark 中一部分任务成绩超过 Pro 是吻合的。而在高难度挑战上,Pro 凭借更深入思考,还是可以拿到更多分数。而 Lite 似乎被抑制过多思考,在该深入思考的任务上,使用 Token 也很有限。不过GPT-5.4 Mini 在同样低的 Token 消耗下,仍能有效思考并拿分。
不足:
- 幻觉:幻觉问题是 Seed 系列的传统顽疾,2 月的 Pro 相比前代改进不大,而 Lite 相对 Pro 则又有一定程度劣化。在数据提取(捞针改进任务)上,Lite 表现过于随机。这一代虽然看不到完整思考链,但从仅有信息来看,Lite 确实被大量数据干扰,没有提取到所有数据就仓促输出。在本月新增的难度更大的长文本阅读题中,Lite 同样看不到题干中所有有效信息,导致最终输出偏差过大。
- 指令遵循:当任务条件多或者描述文本长,Lite 大体上可以遵循,但无法稳定,多遍可能会随机遵循其中一部分。这方面 Pro 表现稍好,但算不上优秀。GPT-5.4 Mini 相对稳定和精准一些。如果指令本身也较为复杂,有组合条件,条件变量等情况,Lite 情况要更坏一些,进行较长思考后,注意力跟不上,遗忘原始约束时有发生。不过这类问题 Lite 的 Token 用量只有 Pro 的70% 乃至 50%,效率有提升。
赛博史官曰:
Lite 的主战场不在推理,并不是所有的任务都要用到最强大的推理能力,尤其在多模态任务中,更需要模型能均衡地发展各个模态能力,并将其融合贯通,那么模型便会像一个睁开眼的人那样,解锁更为广大的可能性。而 Lite 几乎就是这样的模型。这样强大的多模态能力又将反哺到 Seed 团队进行Agent,Coding,媒体素材标注等多种场景的运用,这是数据飞轮运转必不可少的离合片。Seed 真正下一代当惊世界殊之时,Lite 必是功臣。
本文来自转载大模型观测员 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫