短的结论:漫长等待的超值回报
基本情况:
DeepSeek 确实是最早备战编程的厂家之一了,早在V2 时代就发过单独的V2 Coder 模型,直到V2.5 才合入主线。此后DeepSeek 的编程基本功一直在线,DeepSeek V3.2 在之前的编程V2 榜单上也一直是代码一遍过率最高的国模。只不过Agent 时代全面到来之后,V3.2 在越来越复杂的Agent 工况下,表现没那么突出了。
DeepSeek 原本无意竞争,但树欲静而风不止,在无尽的传言与漫长的等待之后,新一代V4 正式登场。
新的V4 有Flash 与 Pro 两个模型,分别支持多档推理。Flash 与主流的中小尺寸模型大小相近,高速,低价。而Pro 则以万亿身躯,主打智力上限。
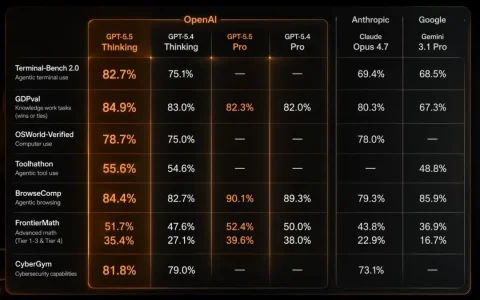
V4 Pro 则基本上重新拿回了国模编程冠军的荣誉。在编码工程测试上,max 档位基本都能胜过前冠军GLM-5.1,大幅缩进了与Opus 的差距。而high 档位也都能跑完4 个工程。 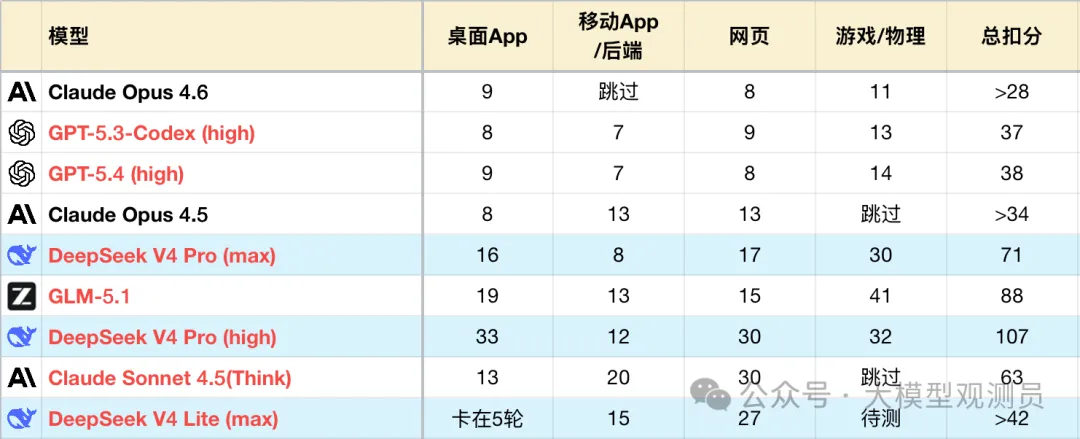
测试方法参见:大模型编程应用测试-V3榜单
细分来看,V4 Pro 在编程上有几个鲜明特点。
其一,广泛的编程知识。4 个工程,尤其C 和 F 非常需要各种细分领域知识,如果知识不足,就会出现很简单的Bug 也改不了的情况,比如没有正确配置storyboard 导致macos 的程序无法正常显示窗口等。V4 的知识量基本涵盖了这类非热门领域,并且面对各种边缘Case,V4 Pro 可以不靠猜,直接锁定Bug根因,这一点和GPT、Opus 等很像。比如E 项目中因为Canvas 配置错误导致渲染失败,V4 Pro 可以马上锁定问题,而之前测试的某一款国模在相同问题上耗费8 轮反复定位,也徒劳无获。开发完成后的自测阶段,V4 Pro 掌握的自测手段也很多,甚至会使用一些冷门方法进行代码正确性检查。V4 Flash 对于大面上的知识,掌握程度并不比Pro 少太多。Lite 只是弱在掌握的边缘知识少,遇到不直观的Bug 容易束手无策。
其二,长上下文的低幻觉。由于工程测试采取的是逐轮叠加功能的考察模式,因此在测试的后几轮,再提出全局性修改时,模型往往就需要重新阅读整个工程,找到所有关联细节。这对于GPT/Opus 等模型不是难事,但对于一众国产模型确是相当有门槛。V4 Pro、Flash 在high、max档位上,基本都能保持相当低的幻觉水平,长代码后续流程的Bug 率依然保持较低水准。
其三,偶发性的注意力失焦。遇到工程体量大,要求多的情况,V4 Pro 在high 档位下,受限于思考预算分配,会有概率随机丢弃一些实现细节,但好在经过提醒,加自测一到两轮后,问题基本都能修复,这对智力足够的V4 来说不是难事。而在max 档位下,由于思考预算充足,这类badcase 出现概率就明显下降,复杂功能一遍过的概率大幅提升。不过注意力问题并没有根除,即便在max 档位也会有小概率出现。相比Codex/Opus 这类一线模型,他们基本不犯这类小错,一般是某些小细节考虑不周导致扣分。而且V4 Pro 在Bug 定位的方法论训练上还不够充分,遇到生僻的Bug 最初也没有正确定位思路,一般要人工提示加log 跟踪。
其四,不讲究的架构与UI。V4 基本保留了之前DeepSeek V3 在各类架构设计上的思路,不讲究,不够精致,但也不糊弄,该有的分层,解耦,都会有。做不到Opus 那样一看就出自大手的规范性架构。UI 方面同样如此,直出效果不算优秀,偶尔会有些精细表达,但多数时候就是基本能用的程度。甚至high 档位偶尔下限更低,考虑不周全。如果实际开发配合设计稿,那么问题不大。但如果是纯vibe coding,那实现效果就需要反复抽卡。
总体上看,V4 Pro 的max 和 high 档位,都有着相当高的可用性。在一轮开发中,会较为严格的遵循先充分思考,再一次性写对代码,最后自测收尾的流程。没有出现边写代码边思考,或者自测到一半去改设计的情况。这种严格的编码纪律帮助V4 Pro 规避了大量可能流出的低级错误。
并且max 的消耗没有比high 高太多,平均输出基本持平,但工具调用轮数,工程文件阅读深度会明显高于high 档,至多会多出60%。这意味着使用max 档位,经济成本不会高太多,但完成任务的耗时会大幅提高。
V4 Flash 在编程上整体情况没有差V4 Pro high 档位多少,在中低难度的oneshot 任务上,二者表现几乎一致。在处理较复杂功能时,V4 Pro 一遍过的概率更高,而Lite 总会犯一些小错。并且Flash 的随机性更高,上下限差异大,相同提示词,V4 Flash 可能在完全不可用且几遍也改不好,到一遍过之间随机。不过小尺寸模型大都有此问题,并非V4 Flash 特有。V4 Flash 在Token 消耗上,显著高于V4 Pro,不过综合其单价和TPS,可用性和任务适应性也非常可观。
由于DeepSeek V4 模型整体测试规模很大,因此逻辑部分另外行文,望海涵和耐心等待。
本文来自转载大模型观测员 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫