先说结论:GLM-5.1 的编程能力,接近 Claude Opus 4.6,超越了 K2.5。
但最让人意外的不是编程强——而是它能自己干活,干很久那种。
智谱最近发布了 GLM-5.1。我自己也是将其作为主力实际使用了快两周,说实话,体感确实猛。不是那种”好像好了一点”的迭代感,是能让你坐那儿愣一会儿的那种。前几天提到的多 Agent 股票分析系统就是用 GLM-5.1 从零开始搭建的。
之前不管模型多强,用起来都像带实习生——你说一步它做一步,做多了忘前面的,复杂任务你得全程盯着。GLM-5.1 不太一样,你给它一个目标,它自己拆步骤、自己推进、中间出问题自己修,最后给你一个完整交付。
说人话就是:以前 AI 是你手边的一个工具,你让它干嘛它干嘛。GLM-5.1 开始像一个你能甩手掌柜的同事了——你给方向,它自己跑完全程。
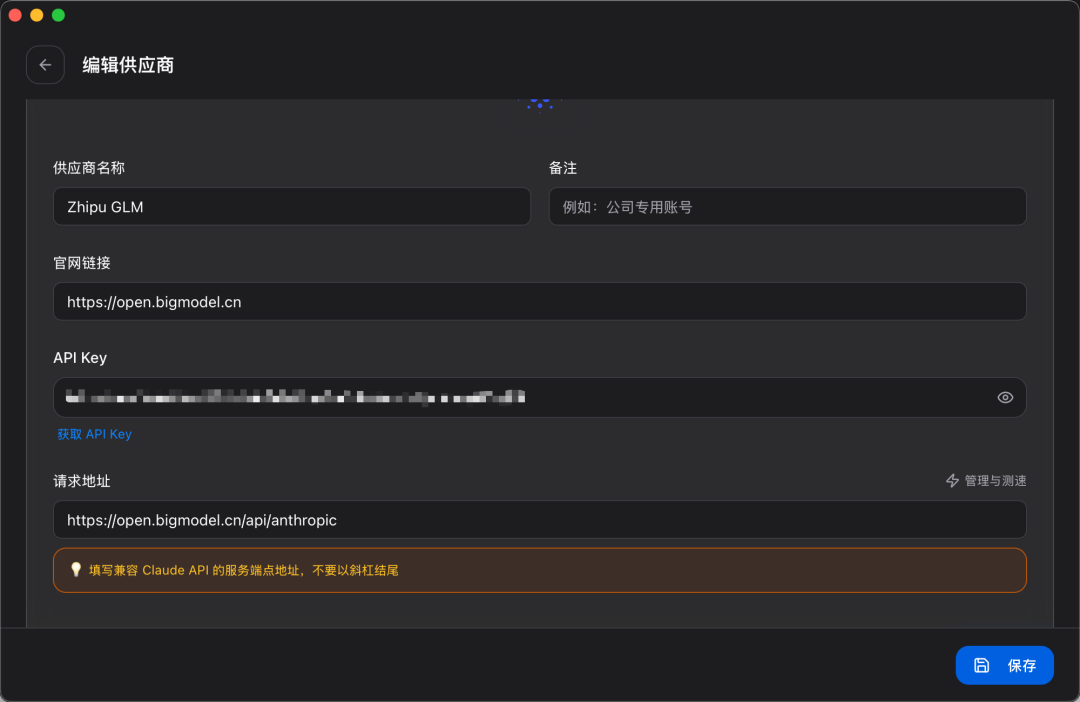
🔧 前置工作:Claude Code + GLM-5.1
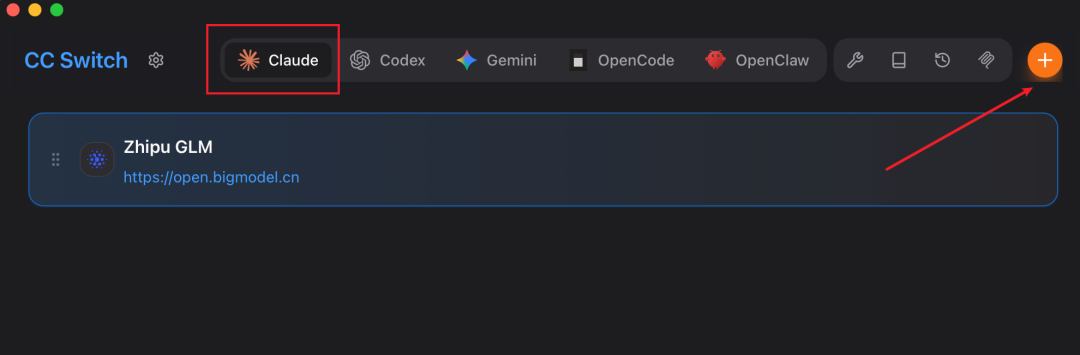
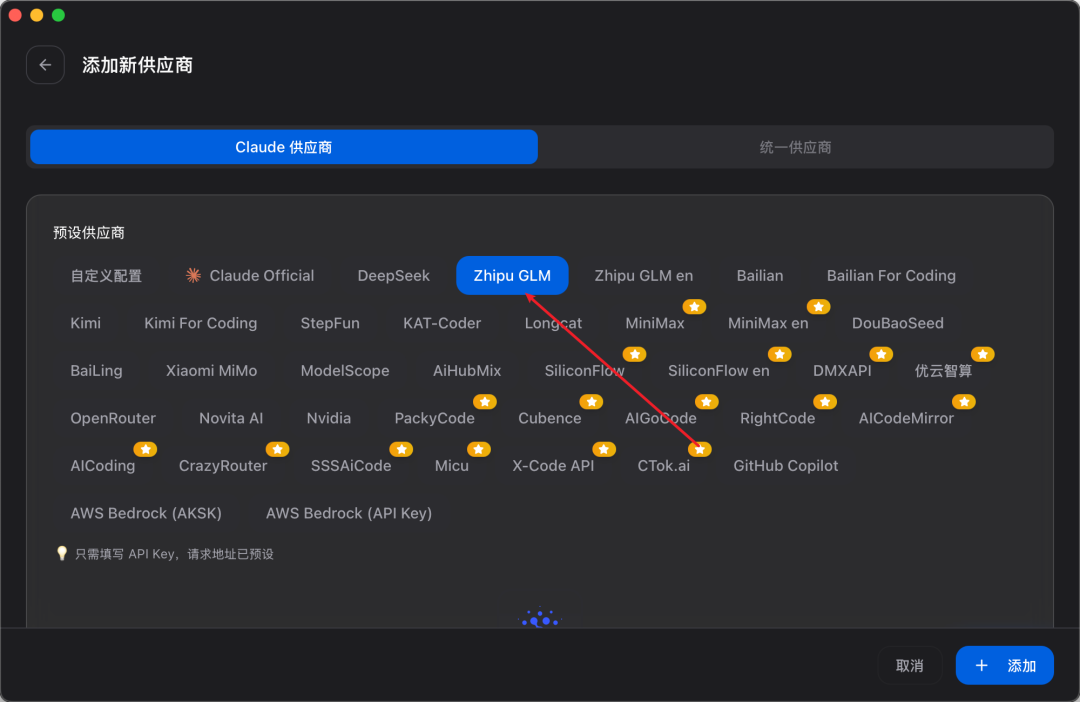
在正式进行开发工作之前,需要进行简单配置。按照业界主流实践,推荐采用 Claude Code + GLM-5.1 的方式进行编码开发工作。
环境配置主要包含两步:
- 安装 Claude Code:
npm i -g @anthropic-ai/claude-code@latest - 安装 CC Switch 完成模型切换(支持管理 Skills、MCP 和提示词,也可直接修改配置文件)
🧪 实测任务概述
口说无凭,实测为证。笔者专门拿出两个近期需要完成的开发任务:
| 任务 | 名称 | 描述 |
|---|---|---|
| 任务一 | Java 智能诊断助手 | 用户只需输入服务地址和业务表象,智能体自动完成故障诊断路径规划、线上问题定位、输出问题代码和解决方案 |
| 任务二 | 企业级慢查询治理 | 百万级数据量下核心订单接口频繁超时,涉及多维度复杂查询的系统性梳理与优化 |
🏗️ 任务一:从 0 开发 JAVA 智能诊断助手
为什么需要 JVM 智能诊断助手?
JVM 线上诊断一直以来都是 Java 开发最棘手的问题。传统排查路径固定而繁琐:
- 查看 Grafana 监控面板,初步定位异常方向
- 登录线上服务器,排查 CPU、内存、GC 等各项指标
- 启动 Arthas 执行诊断指令,逐步缩小问题范围
- 定位到具体代码段,分析根因并制定修复方案
传统模式的三大弊端:
- 监控指标过于主观:研发人员往往依赖经验做主观推断,缺乏系统化诊断方法论
- 诊断链路过于冗长:多工具切换衔接,对紧急线上故障止血来说非常低效
- 高度依赖工程师经验:Arthas 强大但门槛高,必须熟悉各种指令参数才能高效定位
GLM-5.1 如何自主完成技术选型与架构设计?
将完整需求描述交给模型后,它没有立刻开始写代码,而是先结合项目上下文进行推理分析,自主完成了一份包含十几个阶段的完整技术方案。
模型检索了大量资料和 Arthas 官方文档后,输出了系统架构设计图——从上到下分三层:用户层输入服务名和故障现象,Agent 层由 Skill 引擎、Arthas HTTP Client 和 AI 分析引擎三大核心模块协同工作,最底层通过 Arthas 内置 HTTP API 对接多个目标服务实例。
一个细节值得关注:模型针对 Arthas HTTP API 设计了完整的会话模式交互流程(init_session → async_exec → pull_results → interrupt_job → close_session),甚至连 watch、trace 这类持续监听型命令的异步轮询机制都考虑到了。这种对底层工具交互细节的把控能力,说明它确实理解了 Arthas 的通信模型。
模型编码交付效果
整个过程花费不到半小时,模型自主规划了十余个阶段,持续工作约 25 分钟,中间自主检索了多次外部文档,最终交付了包含 9 个子模块的完整项目:
jvm-ai-agent/ ├── jvm-ai-agent-server/ │ ├── agent-common/ # 通用模块:工具类、常量、DTO │ ├── agent-model/ # 数据模型:实体、数据库映射 │ ├── agent-dal/ # 数据访问层:Mapper、Repository │ ├── agent-arthas-client/ # Arthas HTTP API 客户端封装 │ ├── agent-skill/ # Skill 引擎(7个内置诊断技能) │ ├── agent-ai/ # AI 分析引擎 │ ├── agent-service/ # 业务逻辑层 │ ├── agent-web/ # Web 层:REST API、WebSocket │ └── agent-server-bootstrap/ # 启动模块 └── pom.xml
9 个模块、46 个文件全部到位——从通用工具类到 7 个内置诊断 Skill,从 Arthas HTTP API 的 exec+session 双模式封装到 Spring AI Alibaba 诊断分析器,一个不少。
诊断核心逻辑(executeDiagnosis)的逻辑编排比较成熟:Skill 匹配 → 实例定位 → 诊断链执行 → 动态命令解析 → AI 分析 → 报告生成,异常处理也考虑到了非关键步骤失败时继续执行的容错策略。
private void executeDiagnosis(DiagnosisRecord record, DiagnosisRequest request) {
try {
// 1. 匹配 Skill
Optional<SkillDefinition> skillOpt = skillMatcher.findBestMatch(request.getSymptom());
SkillDefinition skill = skillOpt.get();
// 2. 定位目标实例
ServiceRegistry instance = instanceLocator.resolveInstance(
request.getServiceName(), request.getInstanceIp());
// 3. 执行诊断步骤链(支持动态命令变量注入,非关键步骤失败时继续执行)
List<DiagnosticStep> chain = skill.getDiagnosticChain();
for (DiagnosticStep step : chain) {
String command = resolveCommand(step, contextVars);
String result = executeStep(host, port, step, command);
extractContextVars(result, contextVars);
}
// 4. AI 分析 + 5. 保存报告 + 6. 更新状态
String report = diagnosisAnalyzer.analyze(symptom, allData, decompiledCode, skill);
// ...
} catch (Exception e) {
failDiagnosis(record, e.getMessage());
}
}
集成 Agent 交互页面
笔者只给了一个文档链接(Spring AI Alibaba 官方文档)和一句话,模型就自己去读官方文档、理解集成步骤、完成了页面开发。
验收时在聊天框输入:order-service 程序CPU飙升,请协助排查,Agent 迅速完成了完整诊断链路:
- 通过 Dashboard 获取概览定位 CPU 占用最高的线程 ID
- 基于线程栈帧信息精准定位到问题代码段
- 通过 Arthas 反编译(jad)输出热点代码
- 生成包含根因分析和修复建议的完整诊断报告
全程自主完成,没有任何人工介入,SSE 流式输出让每一步诊断进度清晰可见。
⚡ 任务二:百万级数据量慢查询治理(18s → 300ms)
问题背景
这是一个基于 Spring Boot + MyBatis 的订单查询服务,包含四个接口:用户订单查询、订单搜索、品类销售统计、组合条件筛选。数据库中灌入了百万级测试数据。
对搜索订单接口压测后,系统日志输出了刺眼的慢查询告警:
[http-nio-8080-exec-1] OrderController.searchOrders 耗时: 18375ms
LIKE '%蓝牙%' 的全表扫描导致接口耗时近 18 秒,完全无法满足线上要求。
GLM-5.1 定位与优化方案
把慢查询告警丢给 GLM-5.1 后,模型定位到目标业务代码,从索引设计维度给出了系统性解决方案。
数据库层面——新增 5 个精准索引:
| 索引名称 | 类型 | 优化目标 |
|---|---|---|
ft_product_name |
全文索引(ngram) | 替代 LIKE 全表扫描,支持中文分词 |
idx_create_time_amount |
复合索引 | 覆盖时间+金额 WHERE/ORDER BY,避免 filesort |
idx_search_covering |
覆盖索引 | 让 COUNT 查询不回表 |
idx_user_status_category |
组合索引 | 优化多条件筛选 |
idx_status_category_amount |
覆盖索引 | 优化品类聚合统计 |
ALTER TABLE `orders` ADD FULLTEXT INDEX `ft_product_name` (`product_name`) WITH PARSER ngram; ALTER TABLE `orders` ADD INDEX `idx_create_time_amount` (`create_time` DESC, `total_amount`); ALTER TABLE `orders` ADD INDEX `idx_search_covering` (`create_time`, `total_amount`, `product_name`); ALTER TABLE `orders` ADD INDEX `idx_user_status_category` (`user_id`, `status`, `category`); ALTER TABLE `orders` ADD INDEX `idx_status_category_amount` (`status`, `category`, `total_amount`);
应用层面优化:
LIKE '%xxx%'替换为MATCH ... AGAINST全文检索- 深分页场景自动切换延迟关联(Deferred Join),offset > 1000 时走覆盖索引子查询先定位主键再回表
- 按需 COUNT:仅前端显式传
needTotal=true时才执行
/** 深分页阈值:offset 超过此值时自动切换为延迟关联查询 */
private static final int DEEP_PAGE_THRESHOLD = 1000;
boolean isDeepPage = offset > DEEP_PAGE_THRESHOLD;
List<Order> orders;
if (isDeepPage) {
orders = orderMapper.searchOrdersDeepPage(...);
} else {
orders = orderMapper.searchOrders(...);
}
这种”先全面梳理业务现状 → 自底向上分阶段优化 → 结合业务体量给出阈值策略”的做法,说明模型确实结合了具体数据量做判断,而不是给一个通用方案。
📊 榜单与口碑
如果你不信实测体验,还可以看看 AI Coding 领域的权威榜单:
- SWE-Bench Pro(专业级软件开发能力):全球第一,超过 Claude Opus 4.6
- Terminal-Bench 2.0(工程师式命令行操作)
- NL2Repo(从零构建完整代码仓库)
三大基准综合平均分:全球第三、国产第一、开源第一。
SWE-bench Pro 为什么重要?别的榜单考的是”回答问题”,SWE-bench 考的是”干活”——从 GitHub 拉真实开源项目,里面藏着真实 bug,模型要自己读几万行代码、定位问题、写修复方案,还要跑通原项目测试用例。Pro 版更狠,题目更难、评判更严,基本没法刷分。
GLM-5.1 在这个榜单排第一,它后面是 Claude Opus 4.6、GPT-5.4、Gemini 3.1 Pro。
海外社区反应也很直接:YouTube 博主 AICodeKing 的 King Bench、独立开发者 karminski 的 vector bench,GLM-5.1 都是开源第一。Reddit 上的反馈集中在长任务稳、工具调用顺,Hugging Face CEO 祝贺发布。
📝 小结
两个任务跑下来,GLM-5.1 的表现确实超出预期:
- 任务一:从零搭建完整 JVM 智能诊断 Agent,9 个模块、46 个文件全部自主交付
- 任务二:百万级数据量慢查询治理,接口耗时从 18 秒降到 300ms 以内
- 中间遇到问题自己修,全程没让我补过上下文,没有在长链路后半程断链
这不是 demo 级别的 showcase,这是可以往生产环境靠的交付物。
回过头来看,整个过程笔者做的事情只有三件:提出构想、评审方案、验收结果。而真正把构想变成可运行系统的,是模型自己。
人提出方向、模型负责交付的模式正在成形。
本文来自转载JavaGuide ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫