编辑 | 林芯
有关Deepseek V4 要来的消息可以说是从去年炒到今年,本月真的要来了吗?
根据相关报道——DeepSeek创始人梁文锋近日在内部沟通中透露,DeepSeek V4将于4月下旬正式发布。

真的可谓是“千呼万唤始出来,犹抱琵琶半遮面”了!
但从节奏上看,这一信号并非孤立出现:
首先是,Deepseek 网页端出现疑似新模型测试痕迹。在4月8日,Deepseek 上线“专家模式”与“快速模式”;以及在部分用户中又增添了一个视觉模式(vision),被认为是V4 版本的灰度测试。
第二,多项关于“万亿参数、超长上下文、国产算力适配”的信息开始集中流出。
换句话说,DeepSeek V4 的发布,从“长期预期”,进入到了可验证的倒计时阶段。
网传模型更新内容
有关V4的模型内容在网络上传的沸沸扬扬,有的媒体使用了泄露的基准测试数据进行了测试。
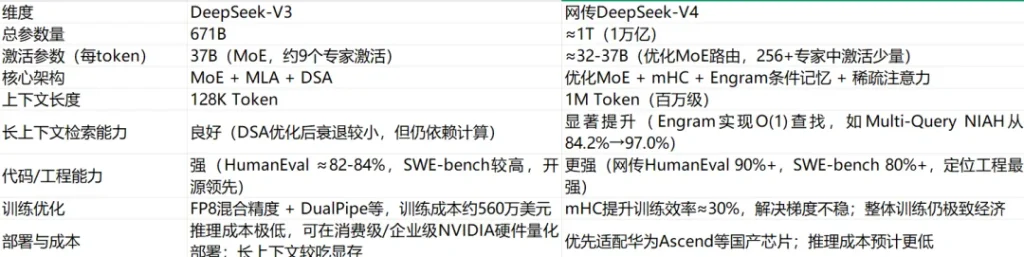
网传的更新内容包括:
优化 MoE 架构,推理成本极低
继承 V3 的 MoE 设计,但更进一步。采用万亿参数混合专家架构,每次推理过程中,只有约 320 亿个参数处于激活状态。这使得推理成本和速度与 V3 相当,甚至 API 定价可能比 GPT-5.4 等低 20-50 倍。
有网友评论:“V4 改变了几乎所有内容,除了每花一美元最大化能力的核心理念。”
引入Engram 条件记忆:“记”与“算”分开
引入条件记忆机制,将静态知识存储与动态推理计算分离,能够高效地从超过 100 万个词元的上下文中检索信息。
传统 Transformer 把所有知识塞进参数,容易导致长上下文检索衰退;Engram该模块将经典的 N-gram 嵌入现代化,以实现 O(1) 查找。
效果也很显著:提升了长上下文检索能力(例如,Multi-Query NIAH:从 84.2 提升到 97.0);减轻 Transformer 主干负担,让模型“记性好”且不浪费显存——与 MoE 的条件计算互补。
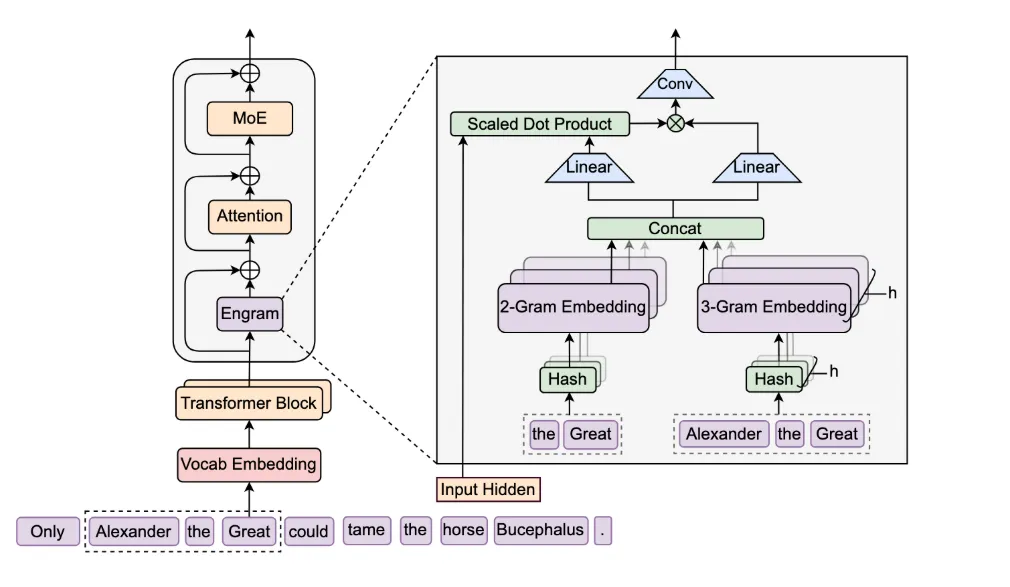
备注:2026 年 1 月 DeepSeek 开源的论文技术 | GitHub: deepseek-ai/Engram
mHC(Manifold-Constrained Hyper-Connections,流形约束超连接)
这是 DeepSeek 在 2026 年1月份发布的另一项架构创新论文成果,主要解决超大规模(万亿级)训练中的梯度不稳、信号爆炸问题。
备注:论文链接 https://arxiv.org/abs/2512.24880
通过 Sinkhorn-Knopp 等数学约束,将层间连接投影到流形上,把信号放大控制在合理范围(例如从传统方法的 3000 倍压到 1.6 倍以内)据报道:可提升训练效率约 30%,让万亿参数模型的训练变得可行。
除此之外,还有降低注意力计算成本的DSA机制——这使得 1M 上下文窗口成为可能等等。
等到Deepseek-v4正式发布,各位大佬可以对照一下~
采用国产芯片
这个可以说是小编最期待的一点。
芯片问题一直是行业最敏感也最关键的痛点。过去几年,中国大模型开发几乎离不开英伟达GPU,从训练到推理都高度依赖CUDA生态。一旦遇到出口管制或供应链波动,整个AI落地节奏就会被卡住。
而根据The information媒体的报道:
DeepSeek 即将推出的 V4 型号将采用华为技术有限公司生产的硬件;与华为和寒武纪科技直接合作,对 V4 核心软件架构的部分内容进行了修改;V4 预计将在未来几周内亮相,同时还将推出另外两款正在研发中的衍生型号。
而在以往大模型开发,早期测试往往优先给英伟达、AMD等美系芯片测试。
而V4反过来,将完全运行在华为最新AI芯片上(主要为Ascend 950PR,部分适配寒武纪芯片)。
阿里、字节跳动、腾讯等巨头已提前向华为采购数十万颗新一代昇腾芯片(Ascend 950PR等),芯片价格一度上涨约20%。华为3月发布的Atlas 350加速卡搭载该芯片,FP8算力达1PFLOPS、FP4算力达2PFLOPS,支持多种低精度,单卡性能强劲。
X上神秘的Elephant Alpha.
在正式发布前,通过匿名模型进行灰度测试,正在成为大模型行业的常见方式。在今年2月,一个名为Pony Alpha的匿名模型出现在OpenRouter上,五天后智谱确认这是其GLM-5系统的一部分;OpenRouter 上也曾短暂出现Hunter Alpha和Healer Alpha,凭借万亿参数与超长上下文迅速引发关注,并一度被猜测为 DeepSeek V4 的前期测试版本——后续被证实是小米 MiMo-V2系列的早期测试版。
而昨天, X.上又出现了一款名为 Elephant Alpha 且拥有 1000 亿参数的即时模型,让网友兴奋起来了!

有网友猜测是 DeepSeek V4,
也有网友认为它是Qwen,或者其他系列的模型,
与腾讯混元同步发布
根据相关媒体报道: DeepSeek V4或与腾讯混元或将同期发布。而混元模型的负责人姚顺雨曾经是OpenAI研究员,于2025年底从OpenAI回国加入腾讯。
DeepSeek V4或与腾讯混元的这次撞期,并非是简单的同台PK,更像是大模型两条技术路径(“底层架构+自主硬件”和“场景驱动+Agent落地”)的碰撞。
到真正发布的那一天,各位大佬可以在评论区分享使用感受~
本文来自转载微信公众号“51CTO技术栈” ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫