如今,Claude Code 已经在诸多复杂的生产环境中大显身手:无论是数百万行代码的单一代码仓库(monorepos),长达几十年的老旧系统,跨越几十个代码库的分布式架构,还是拥有数千名开发者的庞大组织。与小型、简单的代码项目相比,这些环境充满了挑战。比如,不同子目录下的构建命令可能千差万别,或者历史遗留代码散落在各个文件夹中,连个统一的根目录都找不到。
这篇文章将带你了解,我们观察到的那些让 Claude Code 在大规模场景下成功落地的有效模式。在这里,“大型代码库”涵盖了各种复杂的部署情况:数百万行的单一代码库、沉淀几十年的遗留系统、分散在不同仓库里的几十个微服务(microservices),或者是这些情况的任意组合。此外,这还包括那些通常不被认为适合用 AI 辅助编程工具的编程语言,比如 C、C++、C#、Java 和 PHP(其实 Claude Code 在这些语言上的表现比大多团队预期的要好得多,特别是随着最近模型的升级)。虽然每个大型代码库的部署都会受到其特定的版本控制系统、团队结构和历史习惯的影响,但本文总结的这些模式具有普遍适用性,对于准备引入 Claude Code 的团队来说,是一个绝佳的起点。
Claude Code 是如何在大型代码库中穿梭的?
Claude Code 浏览代码库的方式,就像一位经验丰富的软件工程师:它会在文件系统中穿梭,阅读文件内容,使用 grep 命令(注释:grep 是一种强大的文本搜索工具,程序员常用来在大量文件中查找特定的词句)精准定位需要的信息,并顺藤摸瓜地追踪代码库中的各种引用关系。它直接在开发者的本地电脑上运行,不需要你预先构建、维护代码库索引,也不需要把代码上传到云端服务器。
传统的基于 RAG(注释:RAG,即 Retrieval-Augmented Generation 检索增强生成,指 AI 通过检索外部数据库来寻找答案的技术)的 AI 编程工具是这样工作的:它们会把整个代码库转化为向量(embedding),当用户提问时,再检索出相关的代码片段。但是在庞大的代码库面前,这种系统往往会崩溃。因为向量化的处理速度,根本跟不上活跃开发团队提交代码的节奏。当开发者向索引提问时,系统里的代码可能还是几周、几天甚至几小时前的旧版本。检索出来的结果可能是一个两周前就被团队改了名的函数,或者引用了一个在上个迭代(sprint)中已经被删掉的模块,而且系统还不会提示你这些信息已经过期了。
智能体式的搜索(Agentic search)则巧妙避开了这些雷区。当数千名工程师在不断提交新代码时,它不需要维护向量化的数据管道,也不需要集中式的索引。每位开发者的 Claude 实例都在最新、最实时的代码库上进行工作。
但是,这种方法也有一定的代价:只有当 Claude 掌握了足够的“初始上下文”,知道该去哪里找东西时,它才能发挥出最佳水平。也就是说,代码库的初始设置越完善,通过 CLAUDE.md 文件和各种技能层层铺垫上下文工程(Context Engineering),Claude 的导航能力就越强。如果你在一个拥有十亿行代码的库中,让它去寻找一个模糊不清的代码模式,那么在它开始干活之前,你可能就已经把它的上下文窗口(context-window)限额给耗尽了。所以,那些愿意花时间把代码库设置好的团队,往往能获得更好的效果。
基础设施(Harness)与模型同样重要
关于 Claude Code,人们最常见的一个误区是:它的能力完全由背后的模型决定。因此,团队往往只盯着模型在各项基准测试(benchmarks)中的表现,或者它完成特定测试任务的情况。但在实际应用中,围绕模型搭建的“生态系统”——我们称之为基础设施(harness)——对 Claude Code 最终表现的决定性作用,其实远大于模型本身。
这个基础设施由五个扩展点构建而成:CLAUDE.md 文件、钩子(hooks)、技能(skills)、插件(plugins)和 MCP 服务器(MCP servers)。它们各司其职。团队搭建这些扩展点的顺序非常关键,因为每一层都是建立在前一层的基石之上。此外,还有两项额外的能力完善了整个系统:LSP 集成和子 AI 智能体(subagents)。下面,我们来详细解释一下这些组件和能力到底能做什么:
CLAUDE.md[2]文件是重中之重。 这些是 Claude 在每次会话开始时都会自动读取的上下文文件:根目录下的文件用于掌握全局情况,子目录下的文件则用于了解局部的代码规范。它们为 Claude 提供了出色完成任务所需的代码库背景知识。因为不管是什么任务,这些文件每次都会被加载,所以一定要让它们保持精简,只保留最通用的信息,避免它们变成拖累性能的累赘。
钩子(Hooks)[3]让整个设置具备自我进化的能力。 (注释:钩子是指在特定事件发生前后自动执行的一段代码片段)大多数团队把钩子看作是阻止 Claude 犯错的脚本,但它们更重要的价值在于持续改进。比如,一个“停止钩子(stop hook)”可以在会话结束时,趁着记忆还新鲜,反思刚才发生的事情并提出更新 CLAUDE.md 的建议。一个“启动钩子(start hook)”可以动态加载特定团队的上下文,这样每个开发者不用手动配置,就能为自己负责的模块获得正确的环境设置。对于像代码检查(linting)和格式化这种自动化的工作,钩子可以强制执行规则,这比仅仅依靠 Claude 去记住一条指令要靠谱、一致得多。
技能(Skills)[4]让你能够随时调用所需的专业知识,又不会让每次会话变得臃肿。 在一个包含几十种任务类型的大型代码库中,并不是每次任务都需要加载所有的专业知识。技能通过渐进式呈现(progressive disclosure)[5]解决了这个问题:它们把那些如果不拿走就会挤占上下文空间的专业工作流和领域知识独立出来,只有在任务需要时才进行加载。举个例子,当 Claude 审查代码漏洞时,“安全审查技能”才会被唤醒;而当代码被修改且需要更新文档时,“文档处理技能”才会被加载。
技能还可以被限制在特定的路径下,这样它们只会在代码库的相关部分被激活。比如,负责支付服务的团队可以将他们的“部署技能”绑定到支付相关的目录,这样当有人在这个大型代码库的其他地方工作时,这个技能就不会自动加载。
插件(Plugins)[6]让好用的经验得以传播。 大型代码库面临的一个挑战是,“好用的配置”往往只在小圈子里流传(tribal knowledge)。插件把各种技能、钩子和 MCP 配置打包成一个可以安装的独立包裹。这样一来,当一个新入职的工程师在第一天安装了这个插件,他立刻就能拥有和那些老手们一样强大的上下文知识和能力。企业还可以通过企业内部应用市场(managed marketplaces)[7]把插件的更新分发给整个组织。
举个真实的例子,与我们合作的一家大型零售企业,开发了一项技能,将 Claude 与他们内部的分析平台连接起来。这样,业务分析师不用切换软件,就能直接在自己的工作流里拉取业务表现数据。在向全公司推广之前,他们将这个功能打包成了插件进行分发。
语言服务器协议(LSP)集成为 Claude 提供了像开发者在集成开发环境(IDE)中一样强大的导航能力。 (注释:LSP 是一种让编辑器能理解代码逻辑的协议,实现了类似代码自动补全、跳转到定义等高级功能)大多数针对大型代码库的 IDE 都运行着 LSP,支持着“跳转到定义(go to definition)”和“查找所有引用(find all references)”的功能。把这个能力赋予 Claude,就能让它拥有精确到“符号(symbol)”级别的准度:它可以顺着一个函数的调用找到它的定义,在不同文件中追踪引用,甚至能分清在不同语言里名字完全一样但实际上却是不同的函数。如果没有 LSP,Claude 就只能靠死板的文本匹配,这很容易让它找错目标。我们合作过的一家企业软件公司,在全面推广 Claude Code 之前,率先在全公司范围内部署了 LSP 集成,目的就是为了确保在海量代码中,C 和 C++ 的代码导航依然精准可靠。对于多语言混合的代码库来说,这是最具价值的投资之一。
MCP 服务器(MCP servers)是连接万物的桥梁。 MCP 服务器是 Claude 连接内部工具、数据源和那些原本无法触达的 API 的通道。最硬核的团队会把结构化搜索封装成工具,通过 MCP 服务器让 Claude 直接调用。也有其他团队通过 MCP 把 Claude 与内部的文档系统、工单系统或者分析平台连接起来。
子智能体(Subagents)[8]把“探索”和“编辑”分开。 子智能体是一个独立的 Claude 实例,拥有自己专属的上下文窗口。它负责接下任务,埋头苦干,然后只把最终结果汇报给“父级”系统。当整个基础设施搭建完毕后,一些团队会先启动一个“只读”的子智能体去摸清某个子系统的底细,并把发现记录在一个文件中;然后,主智能体再根据这张完整的“地图”去进行全局的代码编辑。
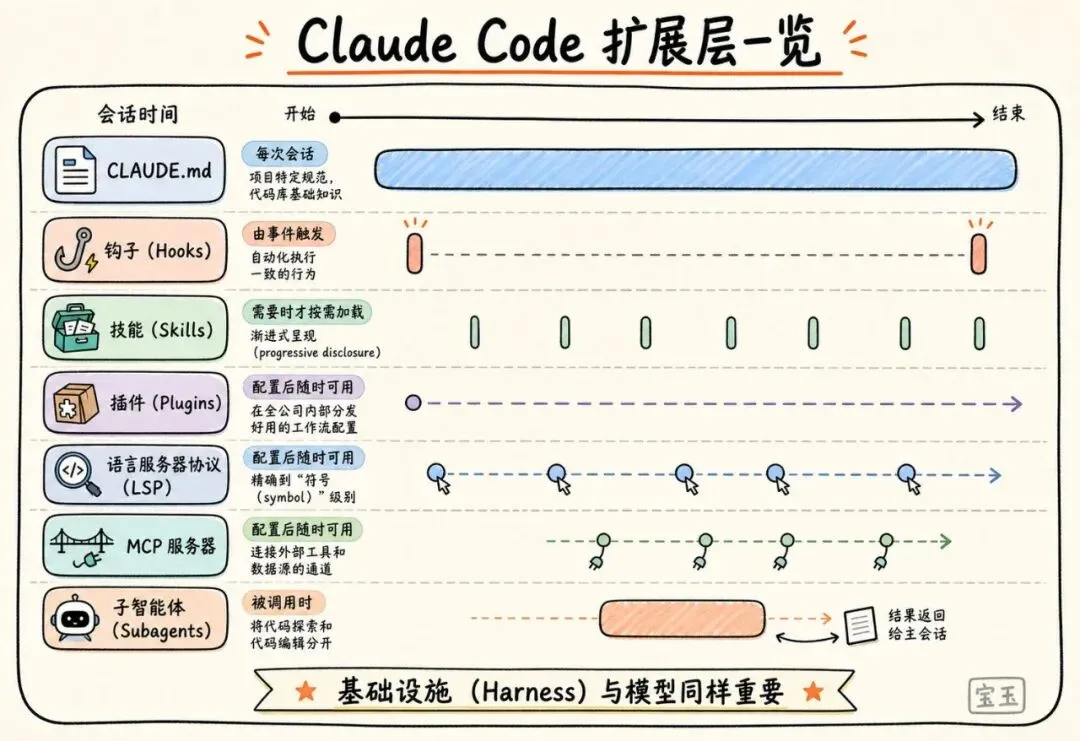
Claude Code 扩展层一览。
下表总结了每个组件的具体功能、加载时机,以及我们观察到的最常见的误区:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
*LSP 是通过插件层访问的。子智能体是一种任务委托能力,而不是一个需要配置的扩展点。
成功部署的三个配置模式
你该如何为一个大型代码库配置 Claude Code,很大程度上取决于这个代码库自身的结构。不过,在我们观察到的众多成功案例中,有三种模式反复出现。
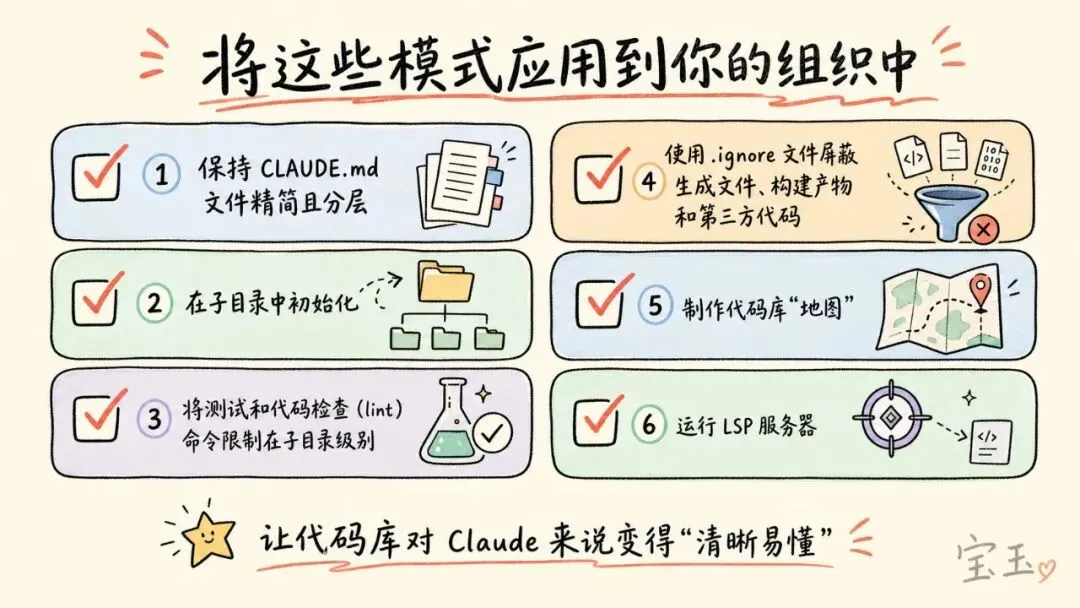
让庞大的代码库变得易于导航
Claude 在大型代码库中能帮多大忙,取决于它能多快找到正确的上下文。如果在每次会话中塞入过多的上下文,性能就会直线下降;但如果上下文太少,Claude 又会像无头苍蝇一样乱撞。最有效的部署方式,往往是在前期投入精力,让代码库对 Claude 来说变得“清晰易懂”。我们总结了以下几个常见模式:
-
• 保持 CLAUDE.md 文件精简且分层。 当 Claude 在代码库中穿梭时,它会不断地把这些文件内容叠加起来:根目录文件提供全局视角,子目录文件提供局部规范。因此,根文件里只应该放最核心的指引和绝对不能踩的坑;除此之外的其他内容,对根文件来说都是噪音。 -
• 在子目录中初始化,而不是在代码库根目录。 把 Claude 限制在与当前任务直接相关的代码区域里,它的表现会是最好的。在单一代码库(monorepos)中,这可能听起来有点反直觉,因为很多工具都默认需要在根目录运行。但别担心,Claude 会自动沿着目录树往上爬,并且读取沿途发现的所有 CLAUDE.md 文件,所以它绝不会丢失根目录的上下文信息。 -
• 将测试和代码检查(lint)命令限制在子目录级别。 试想一下,如果 Claude 只是修改了一个微服务,却跑遍了整个大项目的测试用例,这不仅会导致超时,还会让毫无关联的输出结果塞满上下文。因此,子目录级别的 CLAUDE.md 文件应该清楚地说明只适用于该区域的命令。这种方法在面向服务(service-oriented)的代码架构中非常奏效,因为每个目录都有自己的测试和构建命令。不过,在那些交叉依赖极深的编译型语言大型代码库里,想要做到按子目录限制范围会比较困难,可能需要针对项目定制构建配置。 -
• 使用 .ignore文件屏蔽生成文件、构建产物和第三方代码。 在.claude/settings.json中提交permissions.deny规则,意味着这些排除项进入了版本控制。这样,团队里的每个开发者都能享受到同样的“降噪”效果,不用自己再去折腾配置。在某些项目中,生成的代码本身就是开发工作的一部分。没关系,那些负责代码生成器的开发者可以在本地设置中覆盖项目的排除规则,这完全不会影响到团队的其他人。 -
• 当目录结构不够清晰时,制作代码库“地图”。 有些组织的代码并没有按照常规的目录结构规规矩矩地整理。这时候,你可以在代码库根目录下建一个轻量级的 Markdown 文件,列出每个顶级文件夹以及一句话说明那里边装的是什么。这就相当于给 Claude 提供了一份目录,它在打开文件之前可以先扫一眼。如果一个代码库有几百个顶级文件夹,最好采用分层的方法:根文件只描述最顶层的结构,子目录的 CLAUDE.md 则提供下一级的细节,当 Claude 游走到相应树节点时再按需加载。对于简单的情况,只需使用 @提及(mention)让 Claude 应该参考的特定文件或目录就可以了。
需要注意的是:在某些极端场景下,即便是分层的 CLAUDE.md 方法也会失效。比如一个代码库里塞了几十万个文件夹和几百万个文件,或者是一些使用非 Git 版本控制的老旧系统。我们会在这个系列的后续文章中专门探讨这些难题。
随着模型越来越聪明,要持续更新 CLAUDE.md 文件
随着 AI 模型的不断进化,你为当前模型写的指令,到了未来可能会变成绊脚石。比如,之前为了帮 Claude 绕过某个坑而写的 CLAUDE.md 规则,等新模型发布后,可能就变得多余,甚至变成了束缚。举个例子,假设之前有个规则告诉 Claude:重构代码时必须拆分成对单个文件的修改。这确实能帮早期的老模型稳住阵脚,但如果你换上了更强大的新模型,这条规则反而会阻止它去执行它本可以完美胜任的跨文件协同修改。
同样,为了弥补特定模型缺陷(不管是模型推理能力上的,还是 Claude Code 工具本身的局限)而拼凑出来的技能和钩子,一旦这些缺陷被修复,它们就会变成毫无意义的负担。比如,在一个使用 Perforce(注释:一种常用于大型游戏和企业级开发的集中式版本控制系统)的代码库里,之前写了一个钩子专门拦截文件写入操作以强制执行 p4 edit。但后来 Claude Code 原生支持了 Perforce 模式,这个钩子就成了多余的摆设。
我们建议团队每三到六个月就对配置进行一次认真的盘点。而且,如果在大型模型更新发布后,你感觉代码助手的表现好像停滞不前了,那绝对值得再去审查一次配置。
指定专人负责 Claude Code 的管理与推广
单靠技术配置是无法真正推动团队广泛使用的。那些成功落地的组织,同样在组织管理架构上投入了心血。
那些推广得最快的团队,在全面开放权限之前,都专门投入了人力进行基础设施建设。哪怕只是一个小团队,甚至只有一个人,只要把工具打磨好,确保当开发者第一次接触 Claude 时,它就已经完美融入了现有的工作流。在一家公司里,几位工程师提前编写好了一套插件和 MCP,保证在发布的第一天大家就能用上。而在另一家公司,甚至有一个专门管理 AI 编程工具的团队,在推广开始前就把基础设施全部搭好了。在这两个案例中,开发者初次体验到的都是满满的生产力,而不是挫败感,普及率自然水涨船高。
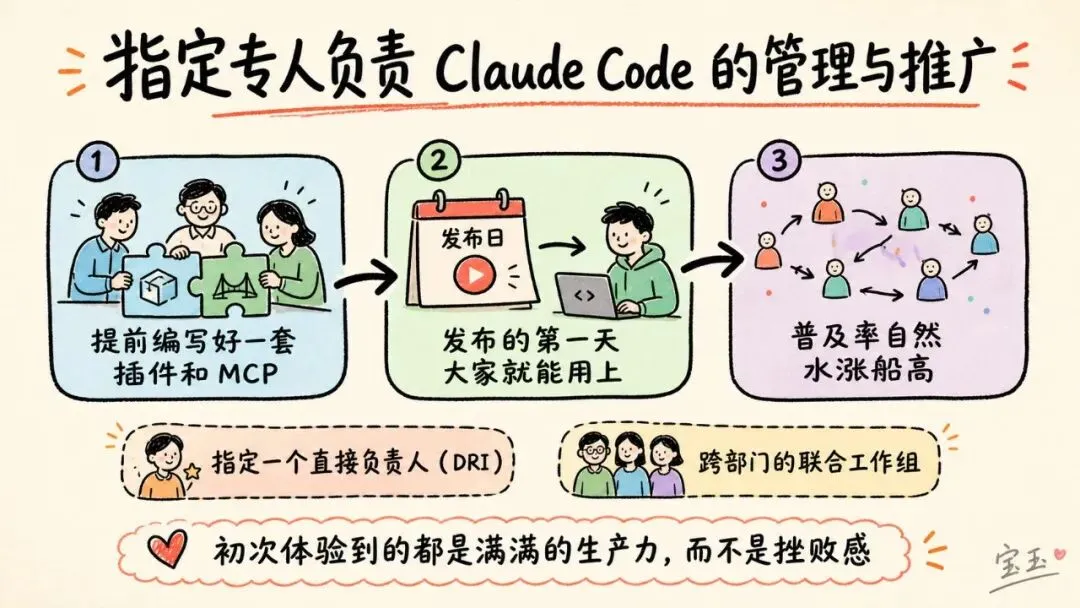
目前,做这些工作的团队通常属于“开发者体验(Developer Experience)”或“开发者生产力(Developer Productivity)”部门,这原本也是负责新员工入职培训和开发内部工具的部门。此外,一些组织里还涌现出了一个新角色:智能体管理员(Agent Manager)。这是一个融合了产品经理和工程师职能的岗位,专门负责管理 Claude Code 的生态系统。对于没有专职团队的公司,最起码要指定一个直接负责人(DRI,Directly Responsible Individual):这个人拥有管理 Claude Code 配置的权限,能够拍板决定各项设置、权限策略、插件市场和 CLAUDE.md 的规范,并负责让这些内容保持最新状态。
由下而上自发的拥抱确实能激发热情,但如果没有人把好用的经验集中起来,这种热情很容易变成一盘散沙。你需要一个人或一个团队来整理、推广正确的 Claude Code 使用习惯(比如标准化的 CLAUDE.md 层级结构,或是精选的技能和插件库)。如果没有人做这些事,经验就会被困在少数人脑子里,工具的普及也就到头了。
在大型组织中,尤其是受到严格监管的行业,早晚会面临各种治理难题:谁来决定哪些技能和插件可以上线?怎么防止成千上万个工程师在自己的电脑上重复造轮子?怎么确保 AI 生成的代码能像人类写的代码一样经历严格的代码审查?为了在早期就应对这些问题,我们建议从设定一组受认可的技能、强制的代码审查流程和最初的有限访问权限开始,随着信心的增强再逐步扩大范围。
我们观察到,推行最顺滑的组织,往往在早期就组建了跨部门的联合工作组。他们把工程、信息安全和合规部门的代表聚在一起,共同定义需求,并制定出清晰的推广路线图。
将这些模式应用到你的组织中
Claude Code 是围绕着传统的软件工程环境设计的:在这些环境里,工程师是代码库的主力军,代码托管使用 Git,代码也遵循标准的目录结构。大多数大型代码库都符合这个模子,但如果遇到非传统的架构,比如包含大量二进制资产的游戏引擎、使用非主流版本控制系统的环境,或者是让非技术人员也参与代码贡献的项目,就需要进行额外的配置工作了。我们这篇指南默认你使用的是传统架构,而且文中提到的这些模式已经在我们的许多客户身上得到了成功验证。如果还存在其他的复杂情况,那就需要根据你们自己的代码库、工具链和组织架构来具体分析了。这正是 Anthropic 的 Applied AI 团队大显身手的地方,他们会直接与工程团队并肩作战,把这些通用的模式转化为最适合你们组织的定制化方案。
立刻体验企业版 Claude Code (Claude Code for Enterprise)[10]。
特别感谢 Anthropic Applied AI 团队的 Alon Krifcher、Charmaine Lee、Chris Concannon、Harsh Patel、Henrique Savelli、Jason Schwartz、Jonah Dueck 和 Kirby Kohlmorgen,感谢他们分享了在大规模环境中部署 Claude Code 的宝贵经验;同时也感谢 Zoox 公司的 Amit Navindgi 对本文提供的宝贵反馈。
引用链接
[1] How Claude Code works in large codebases: Best practices and where to start: https://claude.com/blog/how-claude-code-works-in-large-codebases-best-practices-and-where-to-start[2]CLAUDE.md: https://code.claude.com/docs/en/memory[3]钩子(Hooks): https://code.claude.com/docs/en/hooks-guide[4]技能(Skills): https://code.claude.com/docs/en/skills[5] 渐进式呈现(progressive disclosure): https://platform.claude.com/docs/en/agents-and-tools/agent-skills/best-practices[6]插件(Plugins): https://code.claude.com/docs/en/plugins[7] 企业内部应用市场(managed marketplaces): https://support.claude.com/en/articles/13837433-manage-claude-cowork-plugins-for-your-organization[8]子智能体(Subagents): https://code.claude.com/docs/en/sub-agents[9] 代码智能插件(code intelligence plugin): https://code.claude.com/docs/en/discover-plugins#code-intelligence[10]企业版 Claude Code (Claude Code for Enterprise): https://claude.com/product/claude-code/enterprise
本文来自转载宝玉AI ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫