

“Claude 可能比你更擅长从你这里提取出你想要和需要的东西,而不是由你向 Claude 详细指定。”
“如果 Markdown 文件……超过了大约 200 行,你可能就不太想去读了,而你的同事当然更不可能去读它们。”
“让验证成为事物本身的原生属性,以便 Agent 可以与人类一起驱动它,或最终也可以无主(headless)自动运行。”
当下 AI Agent 越来越强、任务越来越复杂、运行时间越来越长,而这也意味着,我们与 AI 的协作方式或工作习惯必须要改变了!
近期,Claude 官方播客上线了一期“我们如何使用 Claude Code’”的讲座,主讲人是 Anthropic 的内部工程师 Arnaud Doko,核心分享了一个很重要的内容,那就是:如何改变与 Claude Code 的协作方式,从而获得更多价值。
由于 Agent 的运行时间更长,如果它做错了事,海量 Token、时间、算力就直接白费,所以应该在任务刚开始时就避免这种情况的发生。
而这场讲座的核心,就是分享三种高效避坑的新协作方式,从任务起始就避免资源的误耗。
这三种方式分别是:让 Claude 像面试官一样,通过互动来精准提取你的需求信息;改用人类阅读更友好的 HTML 格式作为 AI 规范说明书(spec),而不是 Markdown 格式;将“验证”内置到产品开发全过程,让其成为 Agent 的原生特性。
为了让大家更易理解、快速上手,在演讲全程,Arnaud 以账单均摊(bill splitting)应用的构建为实操案例,直观细致地展示了三种新协作方式的具体落地玩法。

主要内容如下:
让 Claude 像面试官一样,主动挖掘你的真实想法
模型正在变得越来越强大。因此,你应当接受这样一个事实:模型在从你这里提取需求方面,可能比你自己在定义需求时做得更好。
需求其实潜藏在你的潜意识里。就像你和用户交流时一样,用户往往有一种“看到了才知道是不是自己想要的”想法,但他们通常不太擅长清晰地表达自己的需求。
同样地,你可能也是在看到成品时才知道自己想要什么,但 Claude 可能比你更擅长从你这里提取出你想要和需要的东西,而不是由你向 Claude 详细指定。
先给你们举个例子,说明你们平时是怎么做的,以及你们怎么能做得更好。什么是好的提示词?什么是不好的提示词?
不好的提示词就是你说“把它做得更好”。我观察到许多使用 Claude Code 的人只是输入“把它做得更好”或者“不要犯错”。是的,那可不是什么好的提示词。
你应当鼓励 Claude 从你这里提取具体的细节。给出你关注的领域。不要过度指定最终的产出结果,而是指定你感兴趣的范围。对吧?
这就是旁边这个好的提示词不同且更好的原因。例如,关注目标受众,或者提出一种开放式的回答问题的方式,而不是预先定义死,这样就能促使 Claude 进行迭代式的采访。
这时候适合配置快速模式(fast mode)、自动模式(auto mode)和“极高”(X high)“思考程度”(effort)。

这里提示词的关键在于,你想提示 Claude 去使用 ask_user_question(询问用户问题)工具,就像你刚才看到我在之前的提示词里使用的一样。让我提交这些答案。然后它就会编写那个规范(spec)。所以你看到我在提示词中明确引用了 ask_user_question 工具。这就是触发此工作流程的原因。
而且你知道,这取决于你把提示词写得有多好,写得越好,获得的结果就越好。所以它会生成一个规范。然后我们可以将其转化为构建应用的几种不同方式。这需要花一点时间。所以我们先回到我的幻灯片。
那么,假设我们有了一个计划。它生成了一个计划。我们回答了一些问题。它越来越擅长通过一问一答的方式从我这里提取出我真正想要的东西,而不需要我预先自己说出所有的细节。
告别冗长 Markdown!HTML 作为 AI 规范说明书是更优选
我们以前全都是用 Markdown 文件来进行让 Claude 理解和规划任务,现在我们依然在用。我的一位同事曾说过,Markdown 文件是 AI 原生软件开发生命周期的“通用语言”(lingua franca),我觉得这相当有诗意。
但现在看来,这种格式似乎有点受限,它变得太长了,有太多行的 Markdown 文件需要阅读。因此,将更多信息浓缩到 HTML 文件中,就是我们今天要做的事情。
HTML 文件更紧凑,信息密度高得多,也更符合人类工程学,能让你直观地了解这个东西未来长什么样。你甚至可以配合截图来使用。你稍后也可以为此使用 Playwright MCP(模型上下文协议)。
你可以用比面对一个冗长的 Markdown 文件要丰富得多的方式与它进行交互。特别是如果 Markdown 文件变得……你知道,如果它们超过了大约 200 行,你可能就不太想去读了,而你的同事当然更不可能去读它们。

在今天开始之前,我让搭载了 Opus 4.7 的 Claude 为我生成了几个账单均摊应用原型的例子,让我们看看这东西能长成什么样,现在我们就来看看。
我让 Claude 给我几个不同的方向,四个不同的设计方向,去探索它们,将它们生成为 HTML,并让我能够横向对比探索。接着它就给出了这些不同的方案。
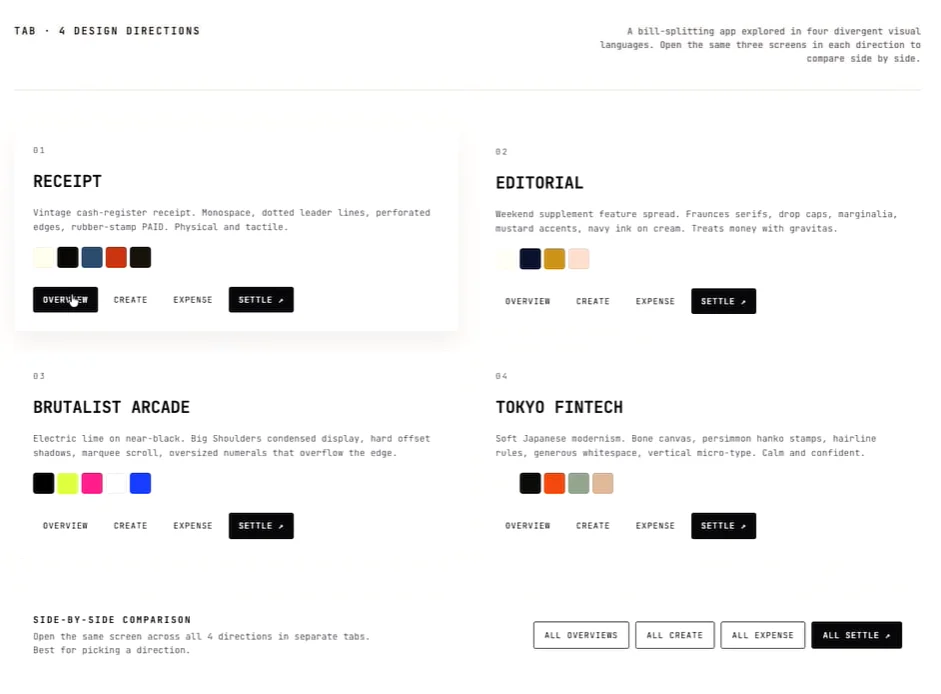
比如有一个是带有一点粗犷主义风格的“东京金融科技”(Tokyo fintech),我们来一个个点击看一看。这就是其中一个看起来的样子。然后这一个,这一个可能看起来像这样。完全不同的美学风格,对吧?

我点击切换,这绝对比仅仅尝试从一个 Markdown 文件中去推测这个东西长什么样,要更方便我向 Claude 提供反馈。我可以像我刚才说的那样,截取屏幕截图,然后把它们反馈给 Claude。这里有谁经常通过截图向 Claude 提供信息吗?非常好。你们确实应该这样做,这非常好。
特别是当你们在做前端开发时,很难用语言精准表达诸如“这个东西有点偏了”或者“这里没有对齐”之类的问题,你会发现自己很快就会遇到语言表达的瓶颈。
实际上,对于尤其是像 Opus 4.7 这样拥有比以前好得多的视觉模型的版本来说,通过截图让它提取出问题所在并主动解决,反而会容易得多。
让“验证”成为 AI Agent 开发的原生特性
让验证成为事物本身的原生属性,以便智能体可以与人类一起驱动它,或最终也可以无主(headless)自动运行。设置你的产品(artifacts),使其能够以你需要的方式原生可测试和可验证。

事实上,我们今天要做的一部分工作是,我们将使用 Storybook 固件(fixtures)、一个测试库、某种数据发射(data emissions)和属性,以及针对 React 应用的 Playwright MCP。
这个应用带有大家以前见过的组件,但它们是以一种全新的方式重新组合(remixed)的,目的是让 Claude 作为智能体可以非常轻松地提取 DOM 中的数据契约(data contracts)。
接着运行验证,甚至记录验证过程。比如,它会自动生成一系列会被执行的验证步骤,并生成一份录像,然后上传到 S3 或与同事分享。
这就是你如何将这些验证步骤转化为由智能体生成的内容,从而让你的直接介入点变得越来越少。这是你们可以复制的做法,特别是从那个重构(rebuild)中借鉴。
实现这一目标的方法是对其进行某种合理的模块化,但当我们看到实际的具体代码时,这一切就会变得非常清晰。所以我鼓励大家访问那个链接(见下图或参考链接)。

那里会有一个代码库,这就是在 CWC 研讨会下的 cloud-with-code-workshops,其中就有今天这场主题为“我们如何使用 Claude Code”的代码库。
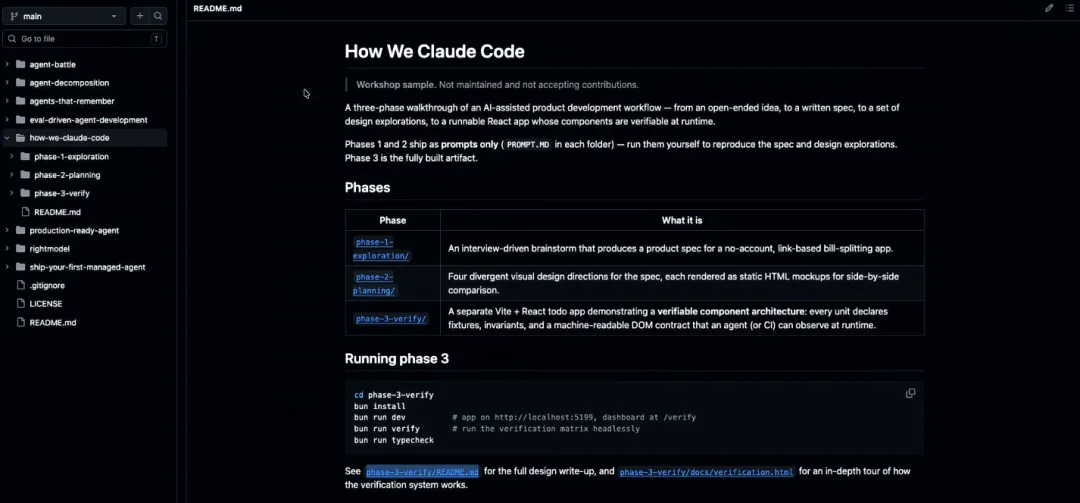
这里面涵盖的内容包括我们刚刚讲过的第一阶段,也就是那个简单的提示词:“嘿,我正在写一个账单均摊应用。请就需求对我进行提问,这样我就不会在给 Claude 的初始描述中漏掉任何内容。”
第二个是生成四种不同的 HTML 设计方向供我们探索,以便我随后提供反馈或做出决定。
第三,我们这里有一个验证框架。它的应用场景不同,与账单均摊应用无关,而是一个关于待办事项(to-do)的应用,一个用 React 编写的小型待办事项应用。
这在第三阶段的 Readme 以及此处的验证详情中都有详细描述。所以如果你想深入了解这是如何配置的,可以阅读这些内容,代码库里都提供了。
我们在这里写了一个小型的待办事项列表应用。我可以添加一个测试项。然后我可以把它勾掉或者删掉。我还可以清除已完成的事项。就状态(state)而言,这里发生了很多变化。
我们希望在已定义的测试之外,验证这一切是否都能正常工作。不过,我们希望这些验证步骤是由智能体来驱动的。
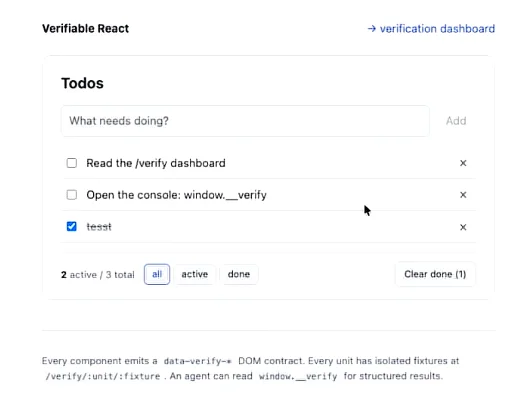
我们有三种方式来实现这一点:首先是用人类可读的方式;但随后,在同样的人类可读仪表盘中,我们将以“智能体优先”的方式进行验证,让 Claude 单独去执行;另外代码库里还有一种独立的方法,你可以直接运行 run verify,它就会在那里跑完测试矩阵。从代码库运行和在这里运行得到的结果可能会有细微差别,但原理是一样的。
也就是说:人类可读模式、通过 Claude Code 或其他工具实现的智能体驱动模式,以及通常在 CI(持续集成)中使用的无主(headless)自动化模式。
我们进入这个应用,实际看一看……好了,我们来看看这里的元素,也就是实际的数据发射(emitting)。比如发射不同的数据维度、数据验证单元、已完成总数和活动总数。组件本身正在将它的状态发布到 DOM 中。
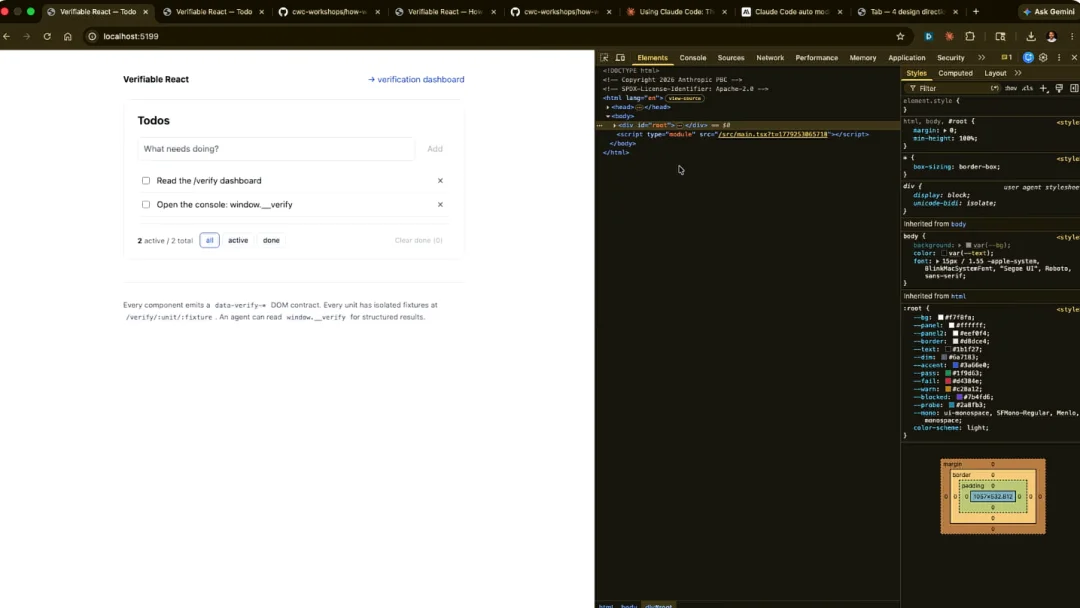
这里的重点是,我想表明我们的思路是让某种智能体原生的东西在这里被读取为 DOM 契约(DOM contract)。这就是我们之前确立的:状态在这里至少对智能体来说是可见的,从而它随后可以自己端到端地运行验证。
在这种情况下,我们还可以做出一个能破坏更多东西的修改。让我看看能不能切断这个链条。我会破坏这个契约,但不会破坏应用本身。我就在这里操作。比如我可以在这里修改——那是在 apps total stats 下面吗?我把它删掉。稍后我也会撤销这个操作。
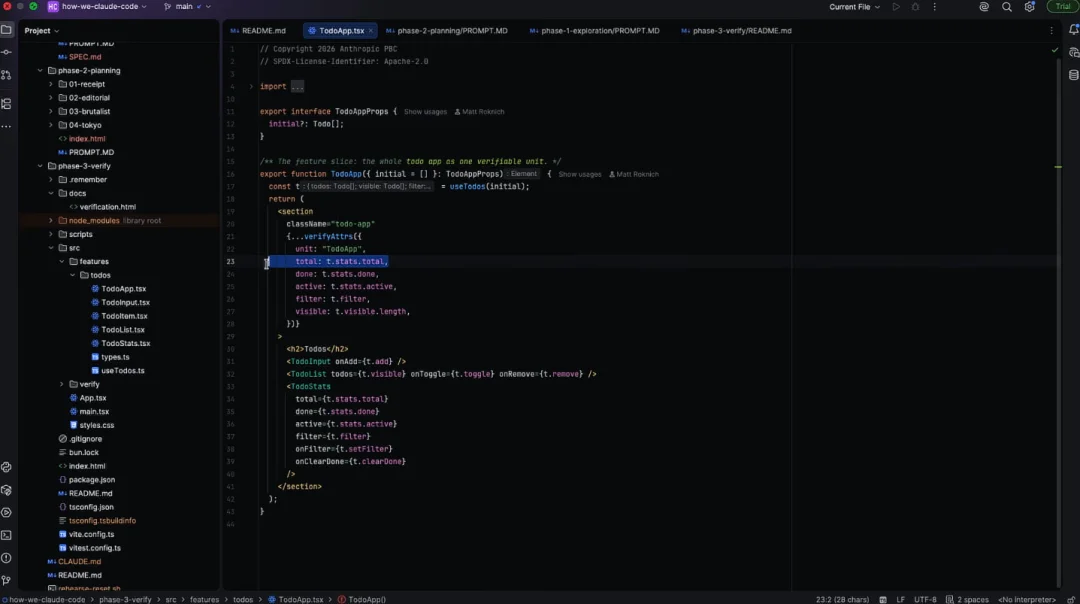
现在的如果我们运行,那么底部这里的这一大片都会失败。当我们再次从这里运行时,也会得到相同的结果。哎呀,看。所有这些都在报错。不是因为我们把应用写坏了,而是因为我们破坏了契约。然后 Claude 就可以利用它进行原生验证。太棒了,很好。
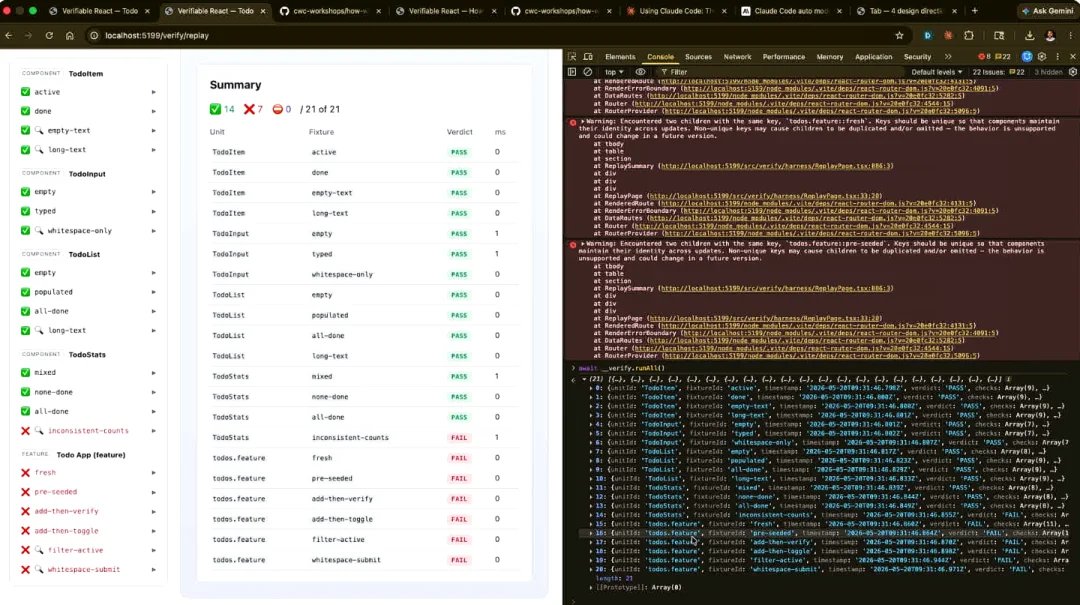
我想让 Claude 告诉我是怎么回事。至少……好吧,不是我刚刚弄坏的那些,我会把弄坏的地方撤销掉,但我希望它告诉我这一个到底出了什么问题。所以让我修正之前做的改动。Ctrl + Z,自动保存,重新运行,搞定。
这样配置之后,我们就通过手动操作展示了我们所做的如何与智能体看到的保持一致。但我们同样也可以让 Claude 自己在无主模式下运行它。那我就来操作一下,把它打开。让它运行。这一个是故意弄坏的,其余的都能正常工作。太棒了。
在这个案例中,我们要做的是让 Opus 4.7 帮我们找出为什么那个特定的验证会失败。我已经为此连接了 Playwright MCP(模型上下文协议),它会调用它并开始运行。
Schema(模式)被拒绝了,4 加 3 并不等于 10。是的,在这种情况下,如果你去运行bun verify,测试实际上是可以通过的。因为我们是故意把验证写错的,就是为了证明原有的测试矩阵本身依然能顺利通过。
不过这里的核心思想是把人类能做的事情,与通过智能体直接在浏览器中使用你刚看到的这些命令所能做的事情区分开来,同时还可以直接在 CLI(命令行界面)中进行无头自动化运行。
如果你也想这样操作,就可以像我们刚才谈到的那样记录结果。在这一套特定的配置中,你确实有能力展示如何记录这些内容。我们展示过的这种延时运行也可以运行并录制下来作为证据,基本上证明它是可行的,而且你可以存储它,让它像那样运行。这在目前非常普遍。
Claude Code 团队基本上就是这样记录他们所做的所有代码改动的,至少所有的前端改动都是如此,尤其是在我们目前的快速发版节奏下。
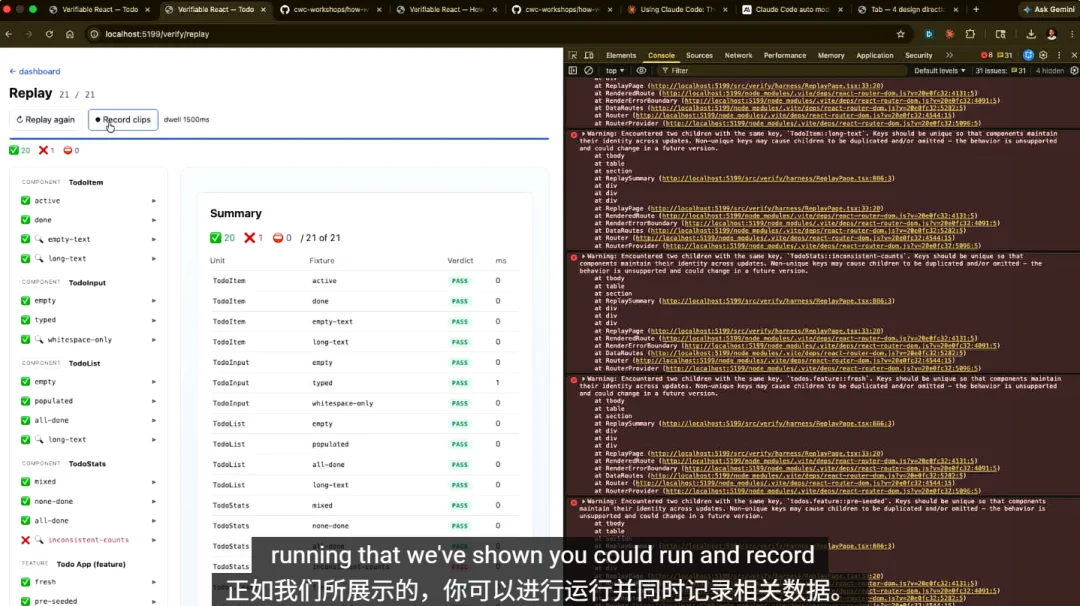
是的,你可以存储它们。我的意思是,你可以把它们放在 S3 或其他地方,或者和同事分享。而在我们的实际场景中,我们有一个内部版本,它比我在这里演示的自动化程度更高。在我们的生产中确实会录制它们。
我不确定会保存多久或具体在什么场景下,但这是常规开发节奏的一部分。好了。所以你拥有了每一个片段,你可以把它们全部下载下来,或者单独下载它们,这基本上就是证明验证通过的证据包。
Opus 4.7 的效果非常好,因为它拥有更出色的视觉模型。这就是它的绝对优势所在。如果你用的是 Sonnet,我个人不太推荐,所以尽量用 Opus 4.7 来跑。也可以试着用一下快速模式。快速模式很棒,虽然成本高点,但非常适合用来快速迭代产品规范。
有时人们会问:“用 HTML 编写规范不是更消耗 Token(效率更低)吗?”答案通常是否定的。原因在于,长远来看,如果你有一个结构良好且内涵丰富的 HTML 规范,你的迭代次数就会变少,即便单次生成它时确实会消耗更多的 Token。所以,你甚至可以配合快速模式来尝试。就是这样。
这就是我给各位的建议。很高兴能与大家交流,感谢大家的聆听。
参考链接:
https://github.com/anthropics/cwc-workshops
https://github.com/anthropics/cwc-workshops/tree/main/how-we-claude-code
本文来自转载51CTO技术栈 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫 







