短的结论:冷静与炙热共存的 Token 熔炉
基本情况:大模型团队都在加速狂奔,离 Opus 4.7 发布也不过一个半月,Opus 4.8 就如期而至。按官方的说法,Opus 4.8 并不是一个大版本,主要优化在对模型行为的约束。
不过由于 4 月下旬国产重磅模型陆续更新,导致笔者错过了对 Opus 4.7 的测试,加上 5 月开始,各模型的测试档位也提到了 xhigh,所以只能对比 Opus 4.8 xhigh 与 Opus 4.6 的 high 档位。所以极限性能看上去有不小提升,但考虑跨了代,而且升档,Opus 4.8 相比 4.7 的提升或许确实不大。
此外还需说明,Opus 4.8 的 xhigh 档位虽然能提高解答正确率,但也会极大拉高 Token 用量,导致其在难度最高的部分 Pass 上会因为输出超长,按规则计 0 分,使得中位分看起来异常的低。但实际上思考预算给够,用户体验应该更接近极限性能。
逻辑成绩:
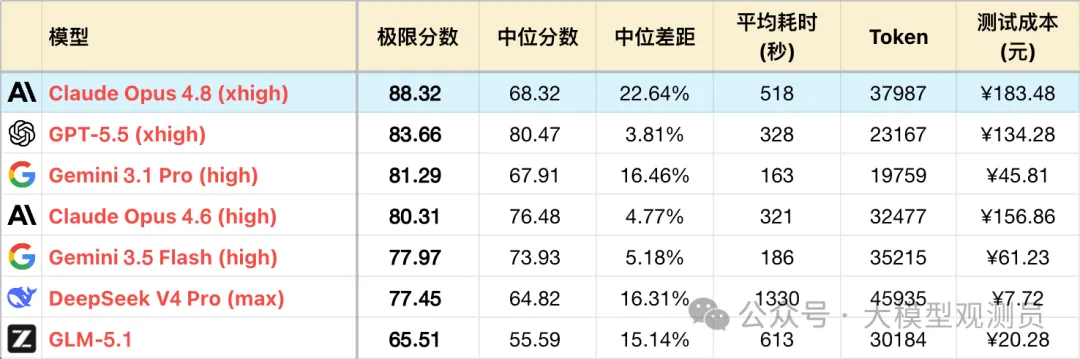
*1 表格为了突出对比关系,仅展示部分可对照模型,不是完整排序。
*2 题目及测试方式,参见:大语言模型-逻辑能力横评 26-04 月榜,额外新增#63,#64,#65,#66 4题。
*3 完整榜单更新在 https://llm2014.github.io/llm_benchmark/
*4 红字模型代表工作在推理模式下(慢思考),黑色模型则是对应的非推理模式(快思考)
考虑到 Opus 4.6 已经隔代,不适合直接对比,因此下文只对比 Opus 4.8 和 GPT-5.5,二者都工作在 xhigh 档位。
优势:
- 幻觉优化:Opus 4.8 的幻觉控制较 4.6 有小幅进步,在新增的长文本类任务中,之前 Opus 4.6 只能拿到和国产模型一梯队相同的分数,而 4.8 则显著提升到几乎无损。即便输入内容存在大量相似文本,4.8 也能准确分辨。与 GPT-5.5 相比,GPT-5.5 幻觉较低且能保持稳定,而 Opus 4.8 最好表现强过 GPT,但最差情况则还是弱一些。
- 指令遵循:Claude 系列一直在对齐人类意图上持续改进,但 Opus 4.6 还会出现少量明确违背意图的情况,比如约定了输出格式,但实际还会额外发挥一些内容。而 4.8 则进一步减少了这类问题,几乎会严格按原始要求行事。但这不代表 Opus 4.8 会无脑响应用户要求,但 Opus 感知到自己无法完成任务时,也会精准止步,承认不足,或者要求用户补充信息。这些特征与官方宣称的强化点基本对应。
- 问题定位:编程测试还在进行中,就目前看到的情况而言,Opus 4.8 的问题定位能力较 4.6 有显著提升,按照给 Coding 能力分级标准而言,之前 4.6 在一些场景只能拿到C 档,即犯的错误需要多轮才能妥善修复,而 4.8 则几乎可以一次性修好。这会使得 4.8 的体感较 4.6 有一定提升。完整情况有待完成编程工程测试后分析。
不足:
- 思考效率:Opus 的思考效率严重落后于 GPT,在各类任务上,消耗都要比 GPT 高30% 以上。一些中低难度的指令任务,规模不大,GPT 表现接近非推理模型,只分配不到 2000 Token 思考预算,而 Opus 会反复检查条件,并且对输出内容再三确认,导致消耗高到 23K。复杂任务,Opus 也基本要耗到 GPT 一倍左右。只有在需要洞察和直觉的问题上,二者基本打平。还需要指出,Opus 4.8 的 xhigh 档位的消耗比 high 要多20%,但正确率提升非常有限,边际收益过低。不过 Opus 的消耗情况要好于国产模型中,消耗较高的几位,同类任务,国产模型的推理预算更加失控。
- 直觉归纳: 当前直觉问题几乎是 GPT 的专长,其他模型很难与之比肩。Opus 从 4.6 到 4.8 基本没有在这方面发力。有些提示比较明显的任务,Opus 也能完成,但如前所述,消耗 Token 远高于 GPT,思维链(只能看到总结)能看到也基本靠暴力搜索。GPT 的这种能力有利于其在前沿科学任务上大展身手,Opus 则需要更多人为约束。
赛博史官曰:
大模型进入Agentic 能力主导发展方向之后,头部厂家基本暂缓了继续冲高模型极限智力,转向利用数据飞轮高速迭代模型。只是各家的选择有所不同。有些团队将模型有限的参数尽量分配到 Agent 任务强相关领域,放弃通用智力。而有些团队则想要分 Agent 一杯羹的同时,放不下全能模型的担子。Anthropic 和 OpenAI 两家是少数可以做到鱼和熊掌兼得的。
面对 Agent 这台赚钱机器,OpenAI 选择是让模型更高效的思考,但提高 API 单价,总成本上升,赚更多钱。而 Anthropic 选择让模型思考更充分,搭配自家一系列 Harness 工程里各种能力放大工具,最终也将 Token 消耗成倍放大,也能赚更多钱。孰是孰非,留与用户评说。
本文来自转载大模型观测员 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫