短的结论:筑起高台摘星辰
基本情况:
在 4 月初,智谱发布的 GLM-5.1 彻底拉开了与 MiniMax M2.7 的差距,问鼎国产模型 Coding 王座至今。而彼时稀宇的下一代模型尚在襁褓,在硬扛了 2 个月压力之后,M3 终于落地。
新 M3 在综合逻辑性能上相比上一代有巨大飞跃,稳定性也来到了国模上游区间。但代价也同样显著,Token 用量不等比地上涨了77%,位居所有模型之首。大部分中等任务消耗涨至 60~70K 用量,所以毫不意外的,复杂任务大量超长。如果不计成本敞开跑,M3 的极限分数大概还能上升 5 分左右,仍落后于 DeepSeek V4 Pro。
而在 Coding 场景,M3 整体优于前代 M2.7,在输出质量,架构思维,测试手段上明显提升,进入可用区间。
虽然 M3 的定价在折扣后持平上代,但受用量影响,综合成本已大幅高于前代。如果未来折扣取消,成本还将上涨一倍。
逻辑成绩:
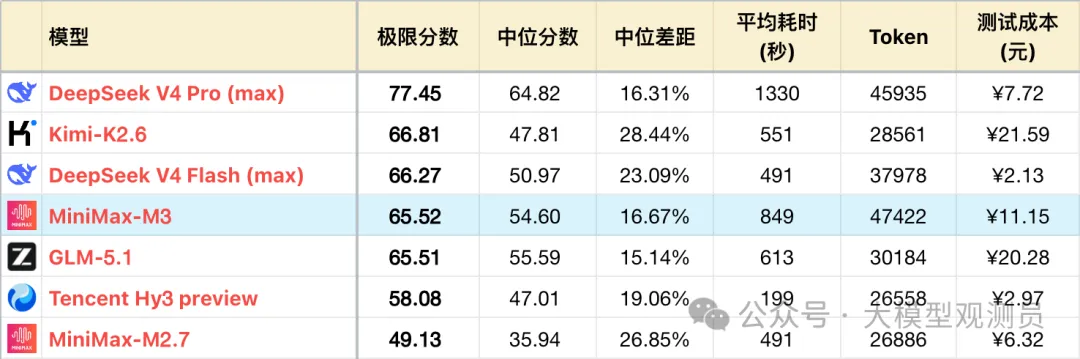
*1 表格为了突出对比关系,仅展示部分可对照模型,不是完整排序。
*2 题目及测试方式,参见:大语言模型-逻辑能力横评 26-05 月榜
*3 完整榜单更新在 https://llm2014.github.io/llm_benchmark/
*4 红字模型代表工作在推理模式下(慢思考),黑色模型则是对应的非推理模式(快思考)
下面重点对比 MiniMax M3 与性能相近的 DeepSeek V4 Flash(以下简称 DS4 Flash),部分参照前代 M2.7。
优势:
- 长文幻觉:在长文本任务中,M3 表现出较好的上下文幻觉抑制能力,能较为准确的从文中任意位置找到关键信息。相关题目中 M3 通常不会因为“看不见”而丢分。前不久的新题#65,需要模型反复检索文本拼凑信息,国产模型几乎全灭,而 M3 表现与 Qwen3.7 Max 相似,也能拿到高分。
- 复杂推理:需要说明,大部分复杂推理任务,M3 都会因为超过规定推理长度,输出空白,仅从有效输出部分来看,长链推理任务M3 显著进步,表现达到国产第一梯队。不过从思维链来看,M3 解决这类问题主要靠保守的逐步试探,每一步都输出大量中间状态信息,较少出现“灵机一动”瞬间。
不足:
- 指令遵循:M3 的指令遵循表现出较高的不稳定性,其本身具备强遵循能力(上限高),简短且明确的指令基本可以稳定无误的遵守,显著优于前代。长指令的遵循较为随机,处于能较好遵循到完全不遵循之间。尤其在长工况环境,模型工作产生了较长上下文之后,这种问题更加凸显,表现是前半程还能准确无误的执行,在某个转折点后,突发失智。
- 思考效率:M3 在大部分任务上的的思考消耗都高于 DS4 Flash max 档位,仅在直觉类问题上,DS4 Flash 思路不对,采用穷举法,而 M3 能找到正确巧妙解法,所以 Token 用量更低。考虑到这种表现通常只存在万亿以上模型,或许暗示 M3 的参数规模同样不小。在中低难度任务上,M3 通常也会消耗达到 30K 级别,而 SOTA 模型普遍在 10K 以内。M3 的思维链中充斥着重复的确认,以及中英文互译等内容,优化空间不小。
MiniMax M3 的编程能力整体较 M2.7 有较大进步,其中前端工程从需要人工辅助,进化为可自行 Debug。M3 的开发行为被调教的非常严谨,会遵循先规则,再按模块逐个实现和测试,最后跑全流程测试,再更新记忆或文档。M3 的架构设计能力进步很大,能结合项目实际做出不用力过猛,刚刚好的架构安排。前端的 UI 实现也继承了前代的审美,精细度较高,但 M3 也存在把调试信息写到 UI 上的小毛病,实战时需要额外约束。 M3 的测试部分消耗的 Token 和时间甚至数倍于编码。
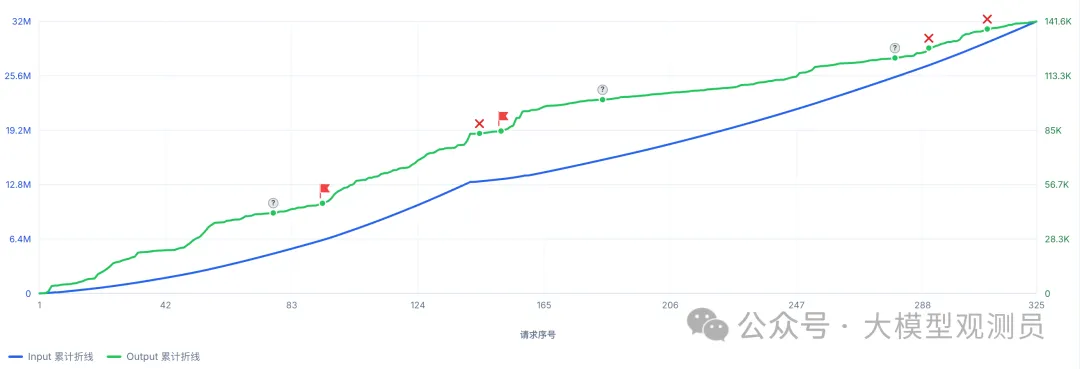
图中是一次 M3 典型的编码过程,可以看到自测(灰色问号)到交付(红旗)少则16 轮,多则106轮。M3 的第一遍直出代码质量并不高,自测过程通常伴随持续的 Bugfix。
然而充分自测也不能保证 M3 最终交付的代码是 Bug Free 的,前文有提到 M3 在长工况下有概率丢失原始指令,在 Coding 场景就表现为,经过几十上百轮工作后,反而遗忘了最初要求中的部分细节,虽然功能整体测试通过,但功能会有缺失,甚至违背初始要求。M3 可以交付尚可用的代码,但需要控制每次实施的变更规模,改动尽量控制在千行以内。
总体上,M3 的编程能力进入到可用区间(超过 Sonnet 4.5),但离 Opus 4.5 差距还十分显著。主要输在细节控制,开发效率上。M3 的自测环节不可省略跳过,否则代码将几乎不可用。对于复杂 Bug,结合其视觉理解能力,可进行自主高效定位,通常不会磨超过 3 轮。
赛博史官曰:
在大模型竞赛中,不存在魔法。MiniMax 的进步并不慢,M3 距离M2.7 也不过 2 个月,如果说前代靠的是孤注一掷,全部参数倾注到 Agentic 相关能力上,那么 M3 则是朝通用智力方向拉回了一些,有更多精力照顾其他泛用领域。
不过也依然能通过测试管窥 MiniMax 在这代模型上的思考与取舍,在效率与质量的权衡上,选择了先保证交付结果。这也是目前市面上同代模型的主流选择,只不过 M3 在效率上舍弃的多一些罢了。但欠账总有要还的一天,这是 MiniMax 即将要面对的问题。
本文来自转载大模型观测员 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫