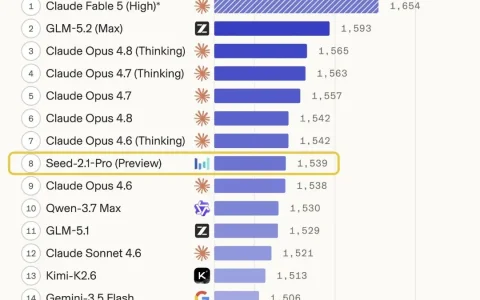
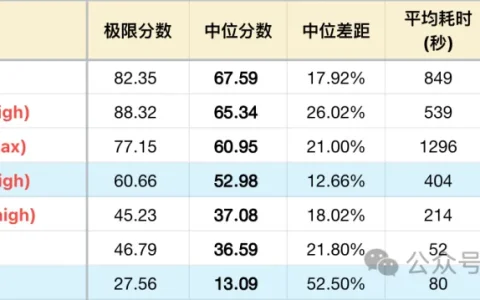
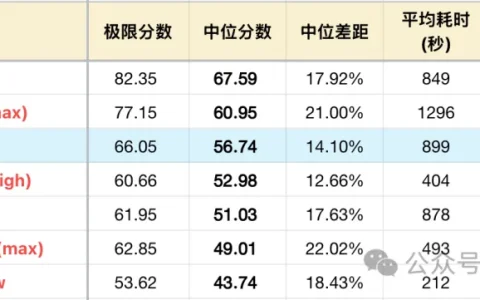
MiniMax M3突然上线后,Token Plan的新计费方式也引起了热议。
众说纷纭之下,MiniMax官方也火速回应,提高了周用量限额,并对以前没有周限额的老用户保持了这个设定。

但价格争议之外,更值得我们关注的,依然是模型能力。
全球开发者,也都在关注模型能力和技术。
比如 Hermes框架的开发平台Nous Research的联创,就公开在X上给M3背书。
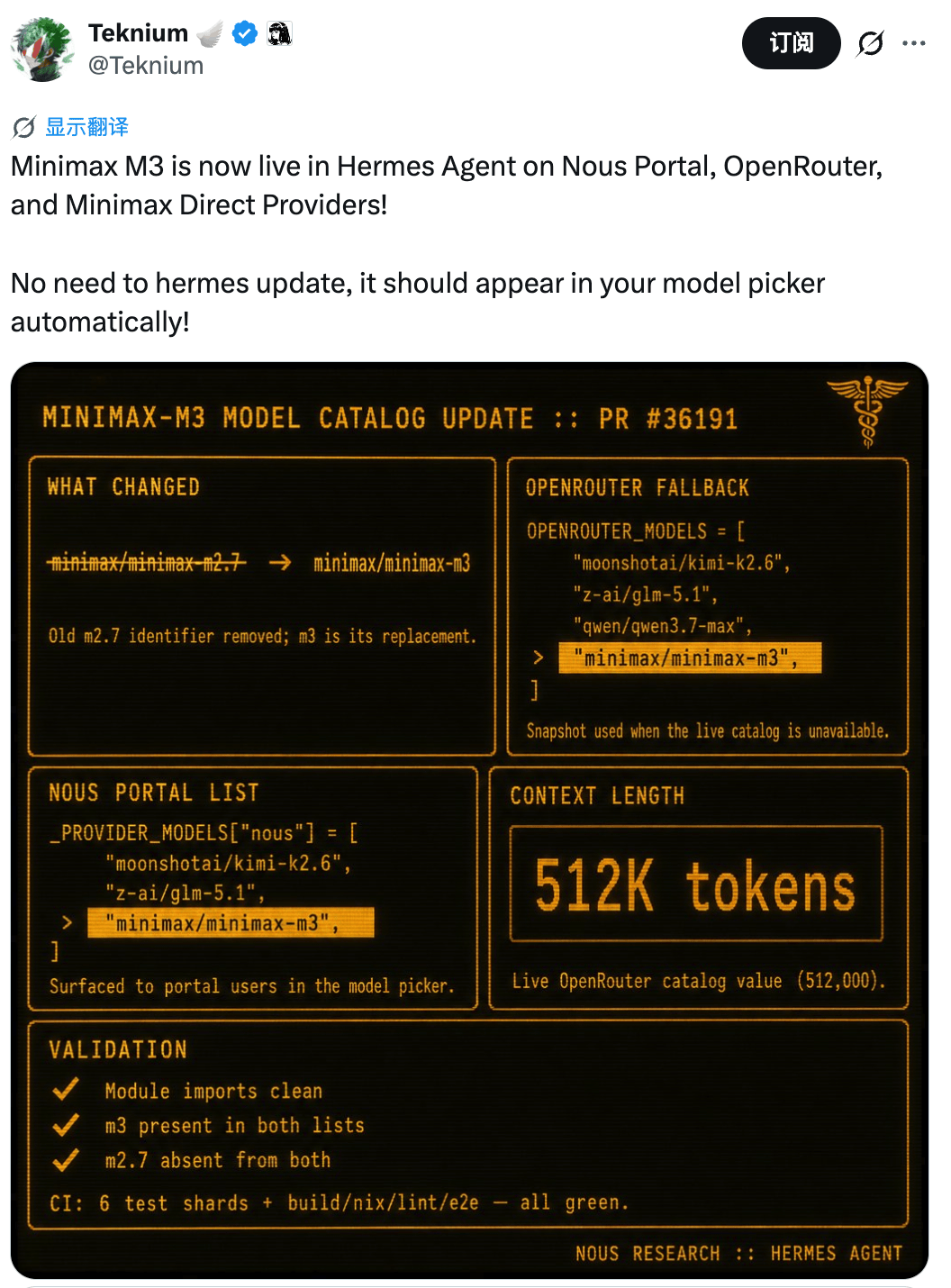
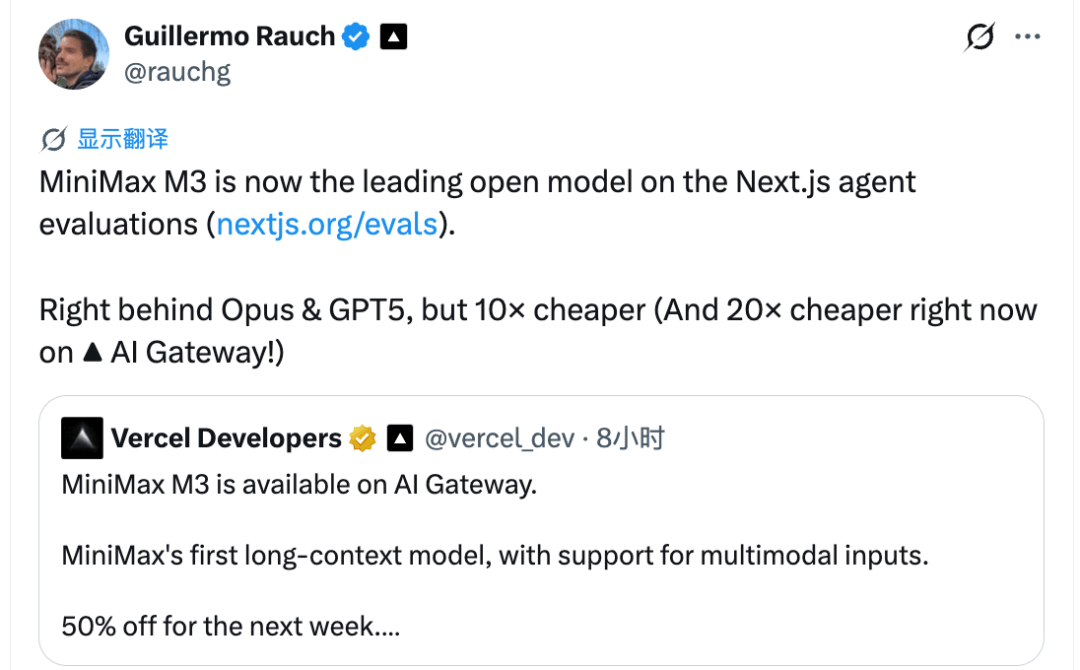
还有 Vercel CEO、GitHub 540k星AI大佬Guillermo Rauch,也在X上公开推荐MiniMax M3,称它的表现紧跟Opus和GPT-5,但价格只有其十分之一。
至于模型的实际任务表现,官方一共给了三个Demo——复刻论文、优化CUDA算子,还有自己训练模型。
我也自己上手,让M3尝试了一些新鲜玩法。
不管是官方Demo还是我自己的测试,想完成这些任务, 长上下文、多模态、Coding三个能力得同时在线才行。
而M3,是国内第一个把这三件事同时做到的开源模型。
就算在闭源模型当中,能做到的也就只有“御三家” (GPT、Claude、Gemini)的最新旗舰。
M3给出的成绩是,SWE-Bench Pro上跑出59%,超过GPT-5.5和Gemini 3.1 Pro,接近Opus 4.7。
而且M3效率更高,1M上下文下每token计算量压到上代的1/20,decoding实测加速超过15倍。
同时,为了搭配M3,MiniMax这次还同步推出了 MiniMax Code。
这是个专为M3设计、并与M3一起训练的Harness,对标的就是Vibe Coding客户端里的扛把子Claude Code。
既然如此,那就直接模型框架一起测,用MiniMax Code来看看M3的表现究竟如何。
一手实测MiniMax M3
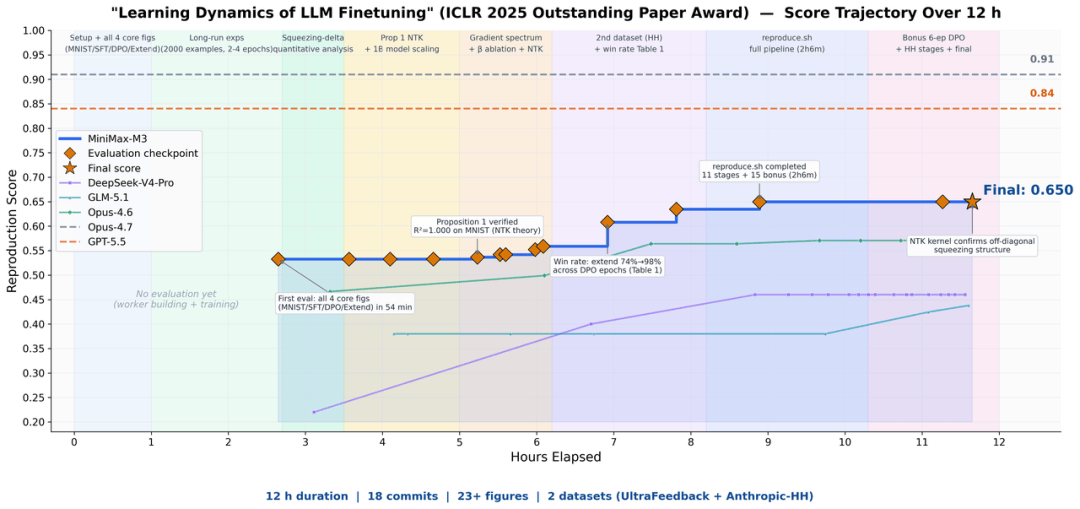
官方Demo里,有人把一篇ICLR 2025的论文扔给它,让它独立复现,结果M3连续运行12小时后成功交付结果,全程没有任何辅助。
这是一篇Outstanding Paper Award获奖论文,研究的是 大模型微调过程中的学习动力学。
具体来说,论文的核心是用“学习动态”框架统一解释大模型微调中的反直觉现象,该框架将每步梯度更新分解为三个因子,揭示了更新如何通过样本相似性在不同输出之间传播。
基于此,论文提出在SFT阶段同时训练y−,让负样本提前“离开低概率区域”,从根源上缓解挤压效应。

这个任务中,M3 自主运行接近12小时,产出18次commit与23张实验图表。
它不仅跑通了核心实验,成功吻合了SFT阶段的预测概率变化趋势,还清晰观测到DPO实验重点讨论的挤压效应,并顺利验证了原论文提出的Extend缓解方法。
中途遇到跑不通的实验,它会自己进行诊断,碰到结果对不上的地方就自己调整, 整个过程始终没有人工介入。
我也照葫芦画瓢,找了一篇ICLR 2026的论文让它复现。
这篇论文解决的是训练大模型时会遇到的一个底层问题。

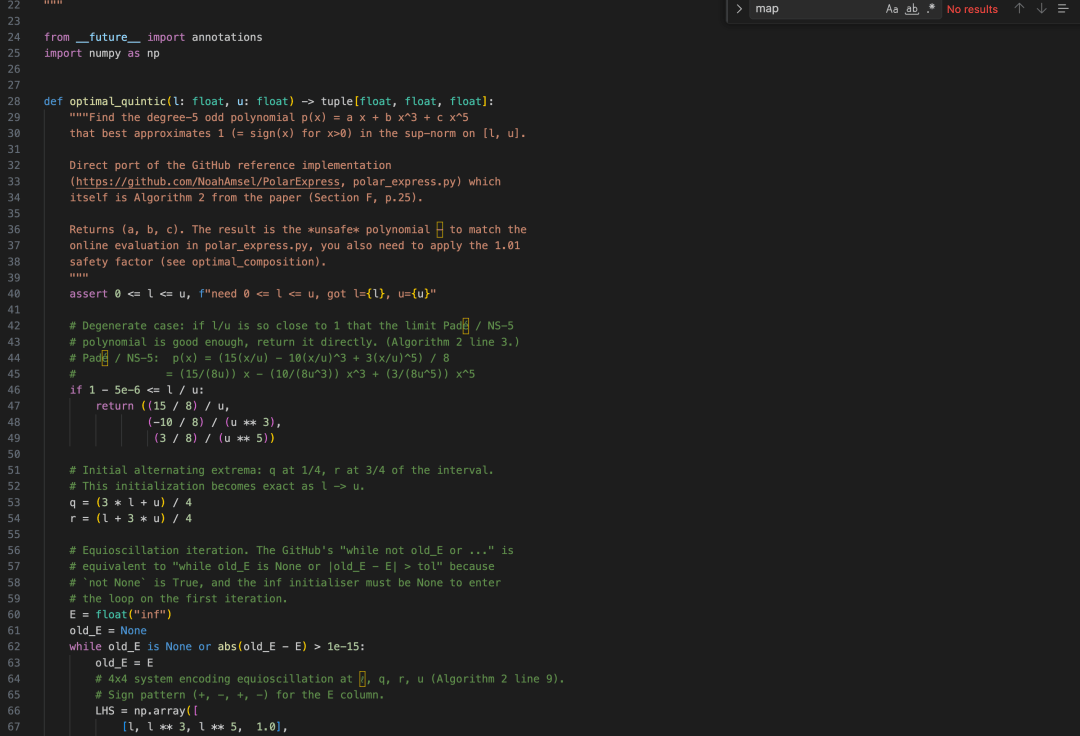
Muon是最近很火的优化器,它每一步更新权重之前,需要对梯度矩阵做一次矩阵极分解。
经典做法是用Newton-Schulz迭代,每步套一个固定的五次多项式,简单但收敛慢。
这篇论文提出的 Polar Express,把固定系数换成了动态求解,即每一轮根据当前矩阵的奇异值范围,现场算出本轮理论最优的多项式系数。

M3把整个实现拆成了三个模块,包括baseline方法、最优多项式求解器,以及主算法本体。

其中最有含金量的是求解器,它从等波动条件出发,建线性方程组,迭代求解,自己算出一组系数。
然后它专门画了一张验证图,把自己从零推算出来的系数,和论文里硬编码的数字并排放在一起,八个迭代步骤逐一比对。
结果就像下面这张图,两条线几乎完全重叠,差异肉眼不可见。
这张图本身就是最好的复现证明,说明M3独立走了一遍和论文作者相同的推导路径,得到了相同的答案。
除了论文,我还用M3玩出了更多新花样。
这不是老黄前一阵子来北京打卡了南锣鼓巷吗,当时量子位还专门做过一期。
于是我就想,能不能 让M3按照老黄的行程,做一个打卡地图呢。
当然那篇文章我是没喂给M3看的,因为我想看看,它能不能凭借自己的力量,把这些信息搜集到。
Prompt就这一句:
搜一下黄仁勋最近一次来北京都打卡了哪些美食,利用真实地图制作可交互的一个打卡攻略网页
实话实说,这个任务我一开始并没有抱太大希望,倒不是说这个任务有多难,是我觉得M3可能会卡在获取地图资源这一步。
但我没想到,还真有免费的地图开发资源可以直接获取,而且还被M3发现了。
它先搜集了网络上的信息,然后总结出了老黄去过的打卡点,然后搜索他们在地图上的坐标,决定利用Leaflet (一个用于构建Web地图的开源JS库)和高德地图瓦片为核心工具来完成我的这个任务。

最终呢,M3也是成功把老黄去过的9个美食打卡点,都标记在了地图上。
交互页面支持普通地图和卫星地图两种模式,点击交互也全都正常。
这里多一句嘴,其实老黄那天去的地方有11个,但财神庙和拓意玩具店不属于我提示词里说的“美食”,所以M3的操作是正确的。

来看下一个任务。
既然前一个任务已经利用上老黄了,那就再让他发光发热一次。
就在昨天的ComputeX上,黄仁勋发表了演讲,其间就提到了“DSX AI工厂生态系统”。
讲到这里的时候,老黄放了这样一张PPT。

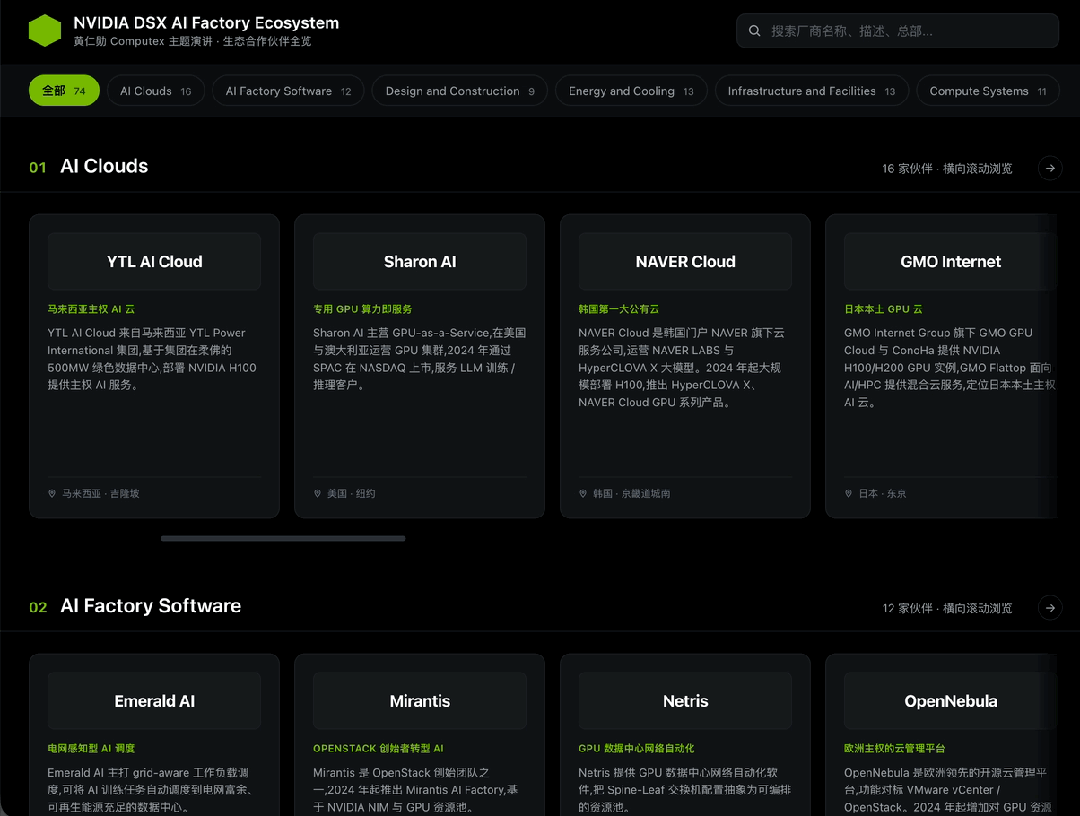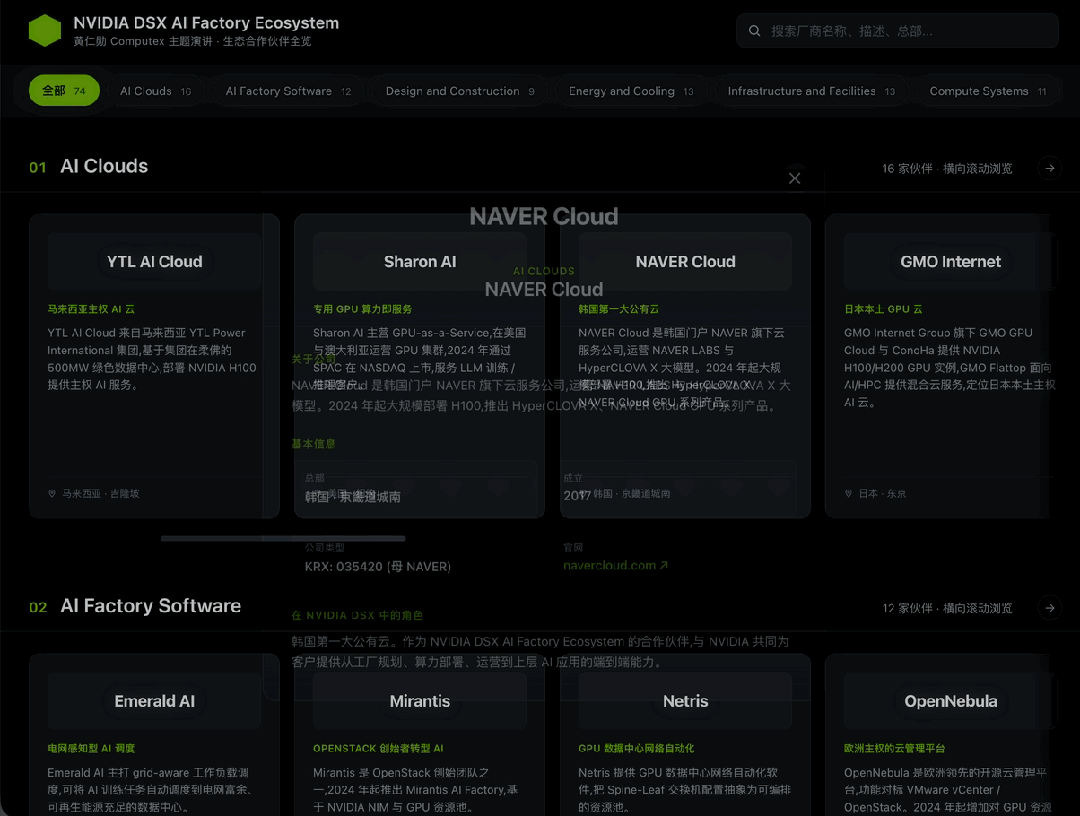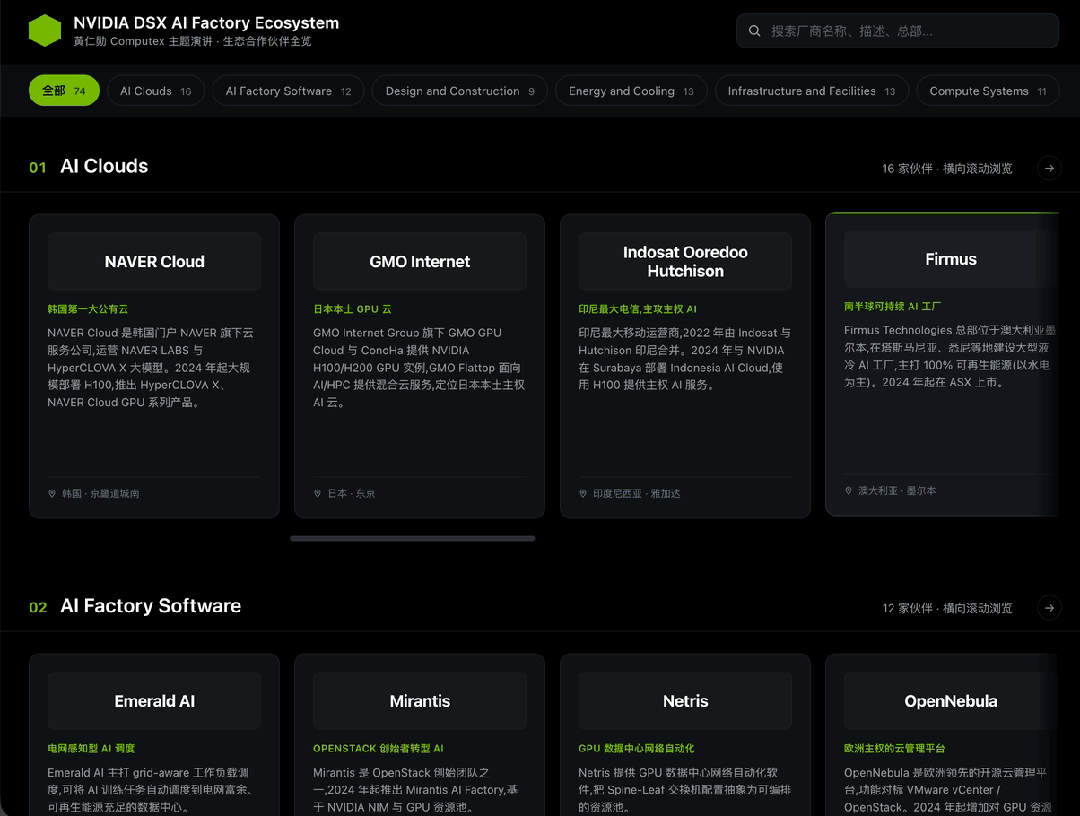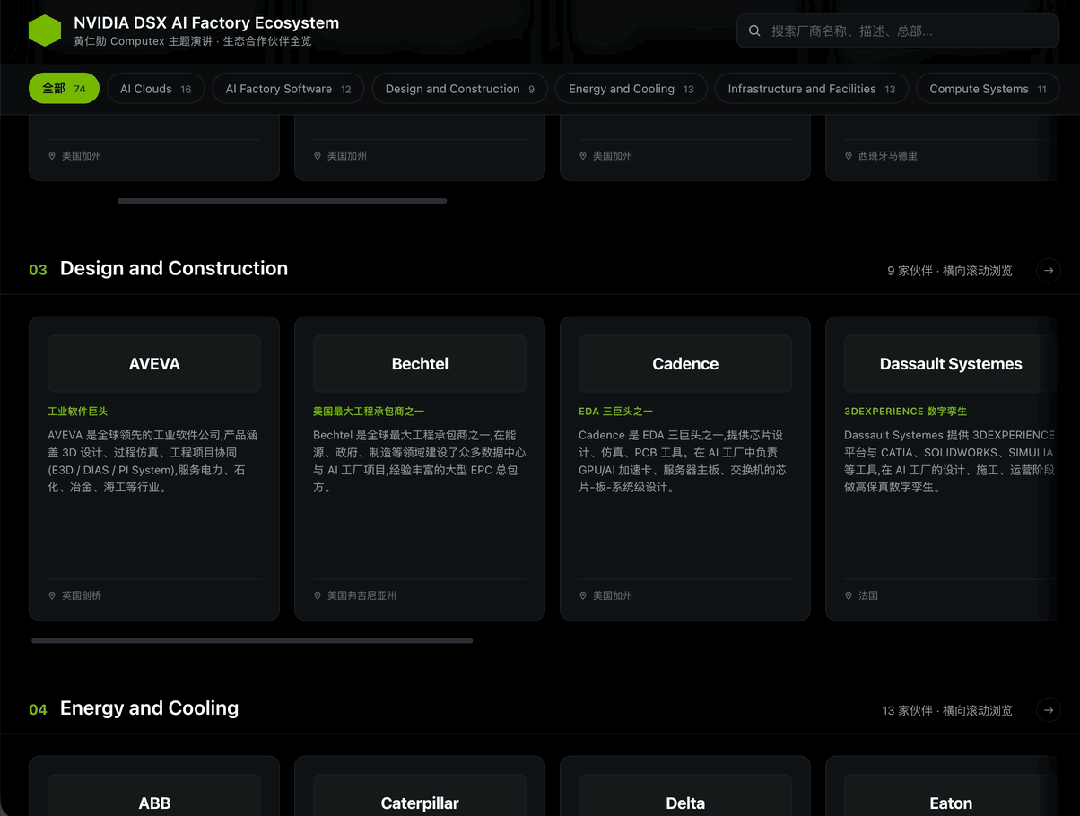
这一轮,我布置给M3的任务就是 把PPT里的这74家(我亲自数过)企业的资料全都找到,汇总做成一个交互式网页。
提示词长这样:
这张图是黄仁勋在ComputeX上介绍的DSX AI生态系统厂商名单,搜集所有这些厂商的信息,制作一个横向的瀑布流网页,点击其中的卡片显示公司介绍。

到这里我依然有些担心,70多个公司,用的还全是Logo,不知道M3能不能看得过来,反正我已经很晕了。
但经过我硬着头皮仔细核对,M3找到的这74家公司无一例外全都正确。

有了公司名单之后,就是搜集这些公司的资料并设计网页了,最终M3也是成功完成了这项任务。
直接看效果,布局完全符合要求,卡片可正常点击,甚至配色用的也是英伟达的标志颜色。
文本、图像都给它看了,检索编程也都考过了,接下来该给M3看视频了。
这回,老黄终于可以休息一下了。
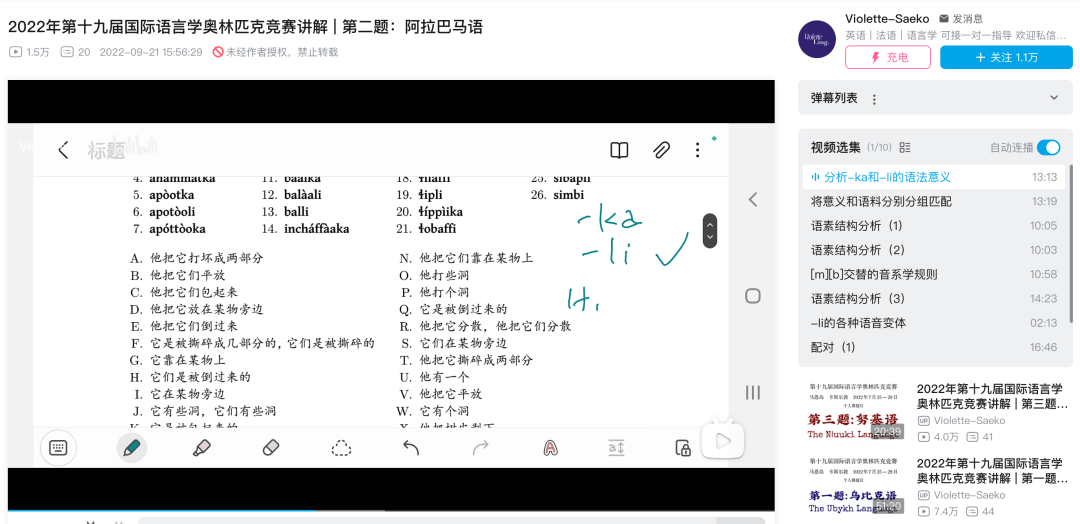
我从B站上找了一道国际语言学奥林匹克竞赛的试题讲解视频,看 M3能不能把这个过程看懂,然后复刻一个讲题的网页出来。
先看下这道题的题目,需要说明的是,我只给M3看了第一问的部分,要求它生成的讲解也只有这一问。

多啰嗦两句,语言学乍看是个文科专业,但其实这道题需要极其复杂的逻辑推理。
实际上,自打OpenAI推出o1的那天起,我就一直在用这道题考验各种推理模型,结果至今无一模型答对 (除了Gemini靠背题答对)。
视频的话,这里放个B站链接,大家感兴趣的话可以看一看,不过时长将近两个小时。
传送门:https://www.bilibili.com/video/BV1LN4y1K7Ld
当然这次M3不需要自己推理,只是需要把视频里up主的解题过程复现出来。
这里我把分P视频全部下载了下来,然后剪辑到了一起,存在了本地目录,并将其设为MiniMax Code的project目录,提示词依然很简单:
理解这里面的视频,做一个交互式网页给我讲明白这道题的第一问。
M3先是用ffmpeg,把这段1.3G的视频压缩到了它能处理的大小程度。
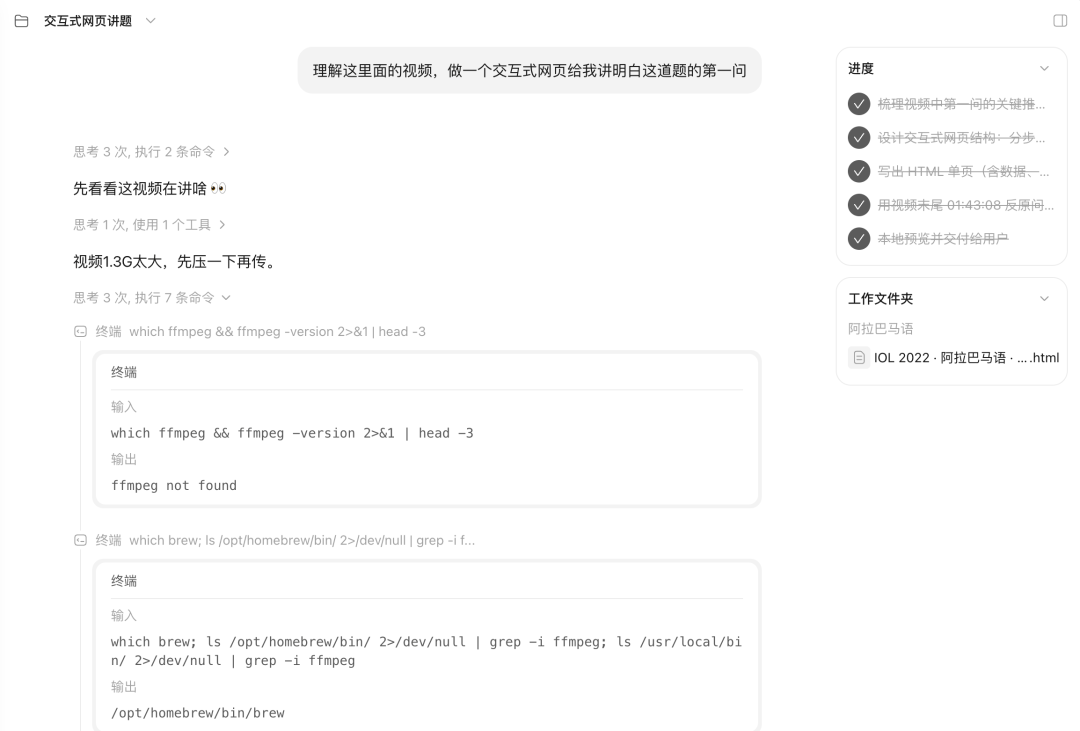
然后M3给自己提出了一系列的问题,开始心中带着问题学习up主的讲解。

之后,M3设计出了页面结构。

对应up主的推导过程,一共分成了三个大的步骤:

我们来看其中一个,的确是简洁、美观又清晰:
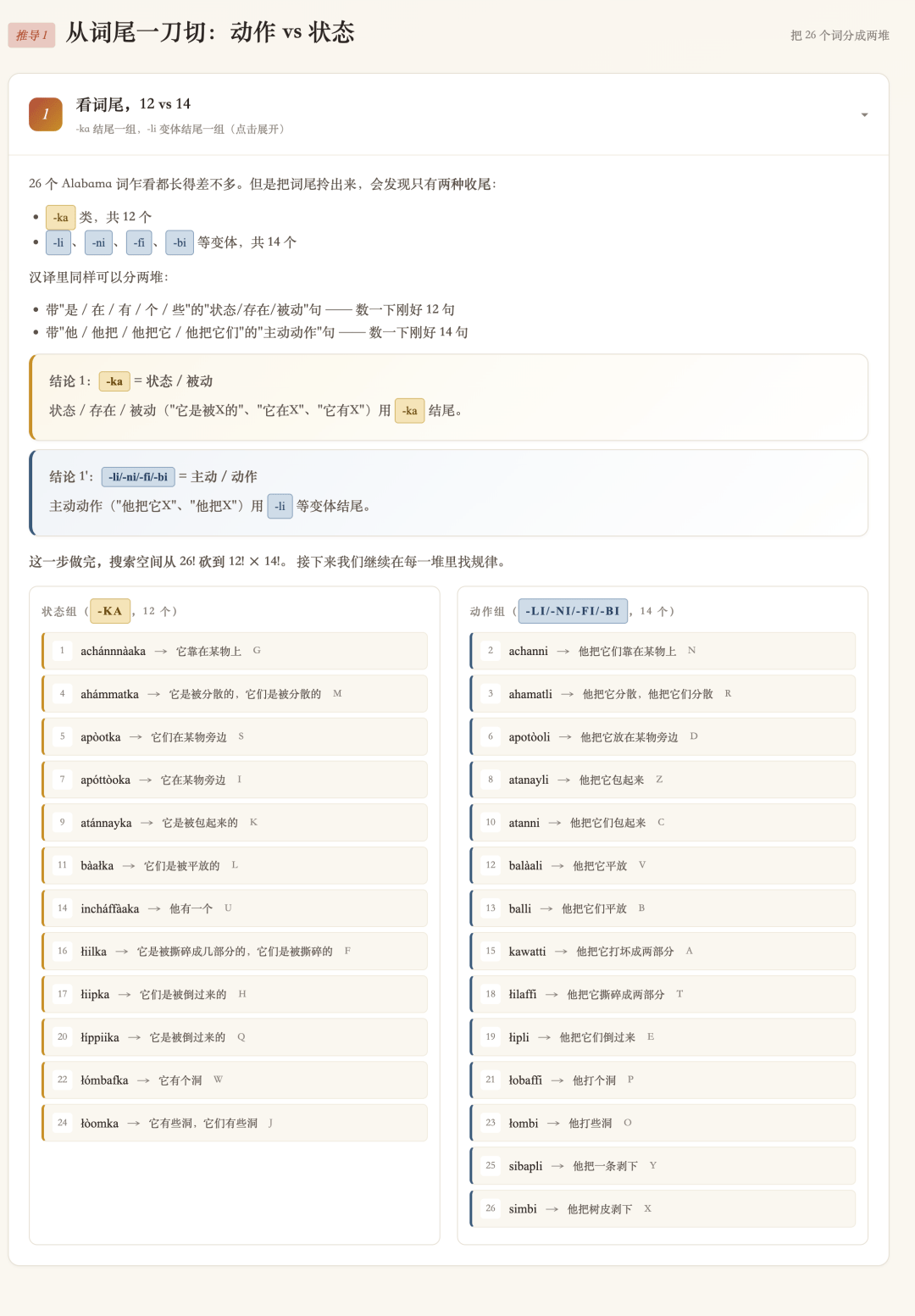
最终的解题结果,和视频也都能对得上。
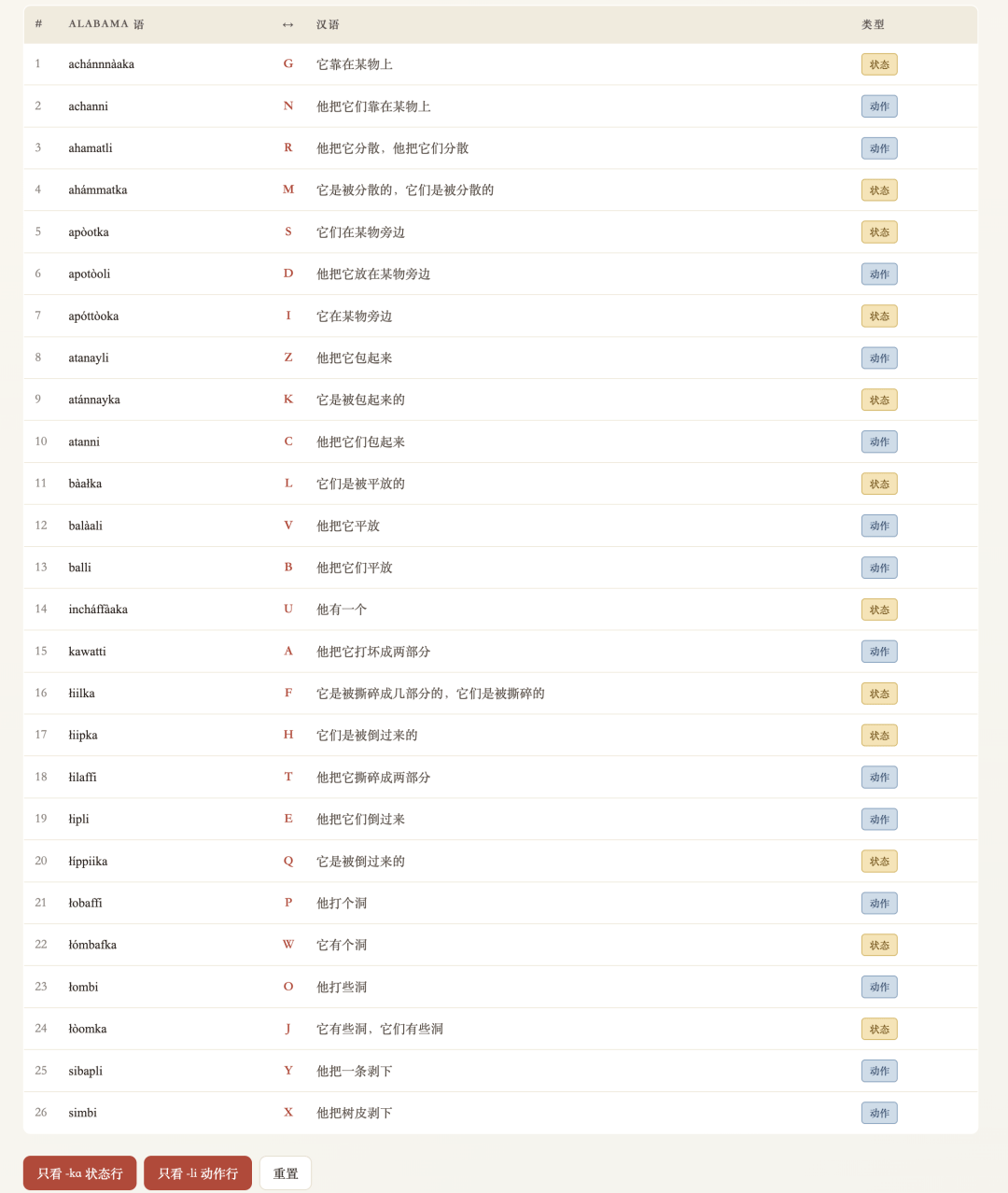
而且讲完题之后,M3还不忘自己做延伸,整理了一套解决语言学推理题的学习心得。

总之这一大串任务做下来,M3的表现属实是超出了我的想象,说它已经进入全球最能打的第一梯队也不为过。
M3用了哪些技术?
M3这次的三大能力,背后各有一个杀手锏。
先说1M长上下文,这里MiniMax选用了一种新型的稀疏注意力机制 MSA,即MiniMax Sparse Attention。
MSA通过以KV块为外层循环汇聚命中它的query,让每块只读一次、访存连续,获得了极高的硬件利用率。
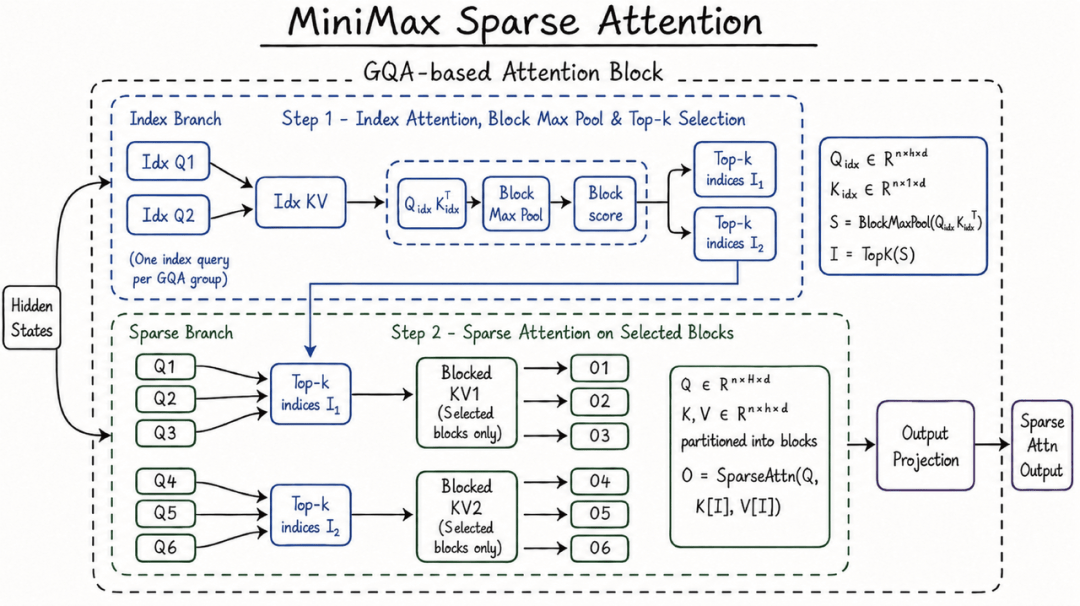
稀疏注意力这条路几家都在走,但赌的方向完全不同。
在MiniMax Sparse Attention出现之前,清华、浙大和月之暗面联合提出的MoBA (arXiv:2502.13189)是思路最干净的方案,把序列切块,轻量路由器给每个query选top-k相关块,复杂度从O(n²)压到近线性。
不过,原版MOBA的GPU效率不行,直到MIT和英伟达联合团队以此为基础,用fused CUDA kernel重写之后改造出了FlashMoBA (arXiv:2511.11571),MoBA路线才算真正落地。
NSA (N代表Native,arXiv:2502.11089)是DeepSeek在研究层面的探索,它的论文数字好看但结构复杂,后续分析也指出质量提升主要来自门控机制本身,而不是稀疏化。
真正跑在DeepSeek产品里的是DSA (D代表DeepSeek),它是NSA在工程侧的落地演进版。
到了DeepSeek V4,DSA进一步发展成CSA (C代表Compressed)+HCA (Heavily Compressed Attention)混合架构。
虽然这是个很好的方法,但它的设计也极为复杂,行业玩家如果想自行使用,难度较大。
相比之下,虽然MSA目前的公开信息不多,但是从架构图能看出来设计思路清晰明了,同样实现高效Scaling,MSA用的是最简单的架构。
Coding和Agent方面,MiniMax用LLM模拟真实开发者的协作行为,构建了 交互式用户模拟器框架,专门用来训练M3的有关能力。
真实开发场景里用户往往在同一个session里持续协作,需求反复修改、中途加新约束、最后推翻重来。
这套框架模拟的就是这些,它让模型在训练阶段就接触接近生产环境的交互场景。
学术侧这个方向已经有实证支撑。
有研究显示,在复杂软件工程任务上,关闭用户模拟器、让Agent在模糊prompt条件下独立工作,F1会从64.5直接掉到44.1。
相关框架包括Simia (arXiv:2511.01824)、MUA-RL (arXiv:2508.18669)、AgentGym-RL (arXiv:2509.08755)等等,思路各有侧重,但核心都是把LLM模拟的用户反馈引入训练循环。
但在商业侧, 把交互式用户模拟器显式用在大规模前沿模型训练上的,MiniMax还是第一家。
多模态方面,M3 从预训练第一步就做图文混合训练,文本和视觉的语义空间从一开始融在同一套框架下,路线上跟Google Gemini一致。
MiniMax发现,interleaved data对模型性能的提升,比通常大家认为的更关键。
基于此,MiniMax重建了整套数据管线,预训练数据规模提升到100万亿token量级。
放眼行业,Google Gemini是这条路线最早的代表,它从设计上就是原生多模态,decoder-only Transformer接收图文音视频交错的token序列。
学术侧,ICCV 2025上有论文 (arXiv:2504.07951)专门研究native multimodal model的scaling law,结论是 early fusion在低算力预算下表现更强,训练效率更高、部署更简单,没有发现late fusion有任何结构性优势。
同一篇论文还发现,interleaved data比image-caption数据更能从更大模型中受益。
值得认真对待的开源选项
长程Coding任务、多轮协作开发、图文混合的复杂文档处理,这三个场景M3的表现已经能撑得住。
对于有这类需求的开发者来说,它是目前开源模型当中的一个可以认真放进清单里的选项。
最近关于Token Plan定价的讨论很多,MiniMax的响应也比较及时。
不过随着实测结果陆续出炉,模型本身的效果开始在海内外成为更持久的话题。
如果把M3本身的效果单独拿出来看,它作为旗舰模型重回国际第一梯队,综合能力和使用成本放在一起算,性价比依然站得住。
往大了说,前沿模型能力长期被少数闭源产品把持,这件事在过去几年里几乎未被打破。
Claude Opus、GPT-5.5、Gemini 3.1,能同时跑通Coding Frontier、1M上下文、原生多模态这三件事的,此前只有这几个名字,而且全是闭源的。
开源社区一直在追,但把这三件事同时凑齐,M3是第一个撕开这个口子的开源模型。
无论是海外还是国内,大模型的更新都越来越卷,但MiniMax这次追得很快。
从M2到M3,Coding能力已经大幅度跃迁。
综合对比下来,M3已经和顶尖闭源模型站在了同一条起跑线上。
本文来自转载量子位 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫