短的结论:君问归期未有期
基本情况:
在 Chatbot 时代步入尾声,Agent 时代尚未全面展开之际,Seed 凭借领先全模态加上优质的推理,也曾独占过国内 SOTA 几个月。而在 Agent 时代,几位二线模型奋起直追,一跃飞升。同门师弟的 Seedance 也延续了视频类 SOTA 地位。Seed 语言模型团队想必也会感到落寞,重新夺回第一是其必争的目标。
等待时间越长,用户期待就越高。4 个月时间足够本土竞争对手迭代 2 次,够北美的领先者迭代 3 次。Seed 2.1 pro相对 Seed 2.0 pro虽说算不上跨越式提升,但也是稳扎稳打,巩固传统优势的同时,尽可能解决已知问题,算是一次忠于版本号的改良。
Seed 2.1 pro对 Token 预算基本上物尽其用,在 high 档位下,几乎会用满给定的额度。因此这次 Seed 在不超测试上限的前提下,大幅提升了平均 Token 用量,来到了史无前例的 65K,比第二位高出 25%。Seed 的非推理模式曾经是高效思考的典范,如今也大幅涨至 5K,一些时候也像思考模式一样大段推理。
加上定价也从16 接近翻倍到了 30 每百万 Token,总使用成本空降国模第一。比他更贵的只有 GPT 和 Opus 了。这或许是字节也面临了算力压力,不得已之举。
逻辑成绩:
从本次测评起,表格的排序切换为按中位分数降序。
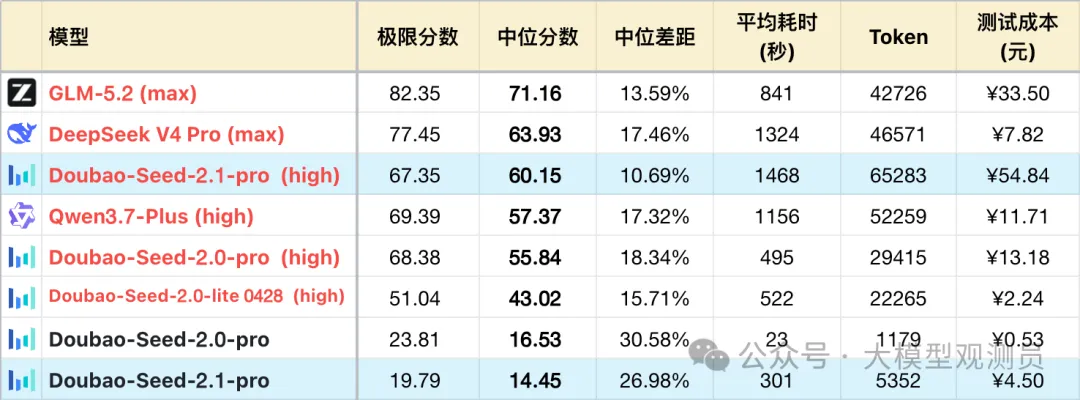
*1 表格为了突出对比关系,仅展示部分可对照模型,不是完整排序。
*2 题目及测试方式,参见:大语言模型-逻辑能力横评 26-05 月榜, 已更新#67,#68 两题。
*3 完整榜单更新在 https://llm2014.github.io/llm_benchmark/
*4 红字模型代表工作在推理模式下(慢思考),黑色模型则是对应的非推理模式(快思考)
以下对比 Seed 2.1 pro (high 档位)与前代 Seed 2.0 pro (high 档位)的差异。二者分别简称 Seed 2.1 和Seed 2.0。
改善:
- 指令遵循:Seed 2.1 的指令理解能力略好于前代,能做到更稳定的遵循。不过代价是消耗 Token 也翻倍,尽管 Seed 2.1 隐藏了思维链,但从总结来看,以其中一题为例,前半部分随着执行推进,中间反复质疑,确认和重复理解原始指令,后半段也在重复对照要求做确认。Seed 2.1 的非推理模式在指令类测试题也经常出现大段输出推理过程的问题,阅读输出可知,情况与前面分析基本一致,可见 Seed 2.1 在这方面的执行效率仍有待优化。由于加强了指令遵循,模型更倾向于相信用户提供的材料,这导致当用户材料本身有歧义和误导,模型会大概率选择相信,这在一些特定任务中,可能会带来副作用。
- 幻觉水平:幻觉问题是困扰前代 Seed 2.0 的硬伤之一,乃至一个月前的 Lite 版本也没有彻底解决。而 Seed 2.1 则有一定改善。体现在中篇幅文本任务上,基本可以稳定无幻觉执行。而且 Seed 2.1 自身工作时输出更多思考内容,幻觉抑制能力也只少量衰减。但需指出 Seed 2.1 的幻觉总体水平依然差于第一梯队的 GLM-5.2,Qwen3.7-Max等模型,这些模型的幻觉更低且稳定。
- 编程:Seed 2.1 的编程能力,大体上要优于Seed 2.0 以及特化的 Seed 2.0 code 模型,表现在有更大的概率可以一次性满足用户原始需求。不同技术栈下的 UI 审美都要显著高于旧版,会在用户没有明确提及的UI 细节和交互上大量着墨,美观程度几乎是国模之冠。不过这仅限于平面 UI,如果涉及立体建模一类,Seed 2.1 则还有不足。Bug 定位能力也有小幅改善,大部分情况可不依赖打日志,仅凭逻辑分析找出问题,并且修正消耗的轮次要少于前代。但依然做不到 Bug Free,或者凭直觉修复 Bug 的境界。按编程能力档位来判定,常见任务 Seed 2.1 大致在 C 档到 C+档,优于前代。任务消耗上,Seed 2.1 也有和逻辑测试相同的问题,即消耗大幅激增。以 GLM-5.2 为基准,Seed 2.1 的任务 Token 读写消耗均在其 2 倍以上,如果遇到复杂 Bug,更是有可能达到 3 倍。这导致 Seed 2.1 完成任务的耗时也显著更高。编程测试尚未全部完成,以上结论只基于已完成的部分来评估,所以排序也欠奉。
不足:
- 能力有偏:旧版 Seed 2.0 的传统劣势项,如空间智力,数学能力,归纳推理等,Seed 2.1 也没有明显改善,依然找不到正确思路,依赖暴力穷举。但编程类,尤其 Oneshot 算法题,Seed 2.1 则表现出更强的直觉,非推理模式也能高分通过。观察到 Seed 2.1 非推理模式整体比前代有小幅退步,可能是训练语料更倾向带推理长上下文和多步轨迹导致的,对日常聊天的影响不大。
赛博史官曰:
在 Agent 领域,有了中美各自的珠玉在前,再想要博取专业用户关注的难度就很高了。但好在 Seed 有豆包,TRAE做载体,并不缺少普通用户。能在实用性上向前迈步,普通用户总是受益的。而且随着各家都在推出适配自家模型的 Agent 产品,用户选模型的习惯会逐渐演化为选 Agent 产品。这对字节这种擅长打造应用端的 App 工厂来说是个好事,前提是模型留在第一梯队,别太差,Seed 显然做到了。
本文来自转载大模型观测员 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫