在 AI 工程界,长文本推理一直是个“富贵病”。
为了让大模型回话快一点,厂商们不得不把数千颗昂贵的GPU塞进同一个机房,并配上天价的 InfiniBand 交换机。
原因只有一个:KVCache(键值缓存)太重了。 只要跨出机房、跨过普通网线,传输延迟就会瞬间拖垮系统,让推理变成“慢动作”。
难道算力只能在昂贵的“孤岛”上跳舞?
近日,月之暗面发表重磅论文,提出 PrfaaS(Prefill-as-a-Service,预填充即服务) 架构。他们用一组惊人的数据证明:即便没有天价网络,靠普通的以太网线,也能实现万亿参数模型的跨中心调度!

剑指大规模LLM推理挑战:KVCache带宽瓶颈
相信关注AI圈的朋友现在都已经知道了这个概念:PD 分离。
而月暗的这篇论文,简单理解,就是将剑锋指向了大规模 LLM 服务中非常实际的问题:
如何在不同数据中心之间、异构硬件环境下,高效地将 Prefill 和 Decode 分离,而不被 KVCache 传输带宽所限制。
过去,跨数据中心推理被视为“工程自杀”,是因为传统模型的 KVCache 像海啸一样,会瞬间挤爆带宽。
论文中指出了原因所在:传统的 PD 分离架构虽然把计算密集的 Prefill 和内存带宽密集的 Decode 分开,但 Prefill 阶段产生的大量 KVCache 必须通过高带宽网络(如 RDMA)快速传输给 Decode 节点,否则会阻塞推理。这导致:
-
Prefill 和 Decode 必须部署在同一个高带宽网络域内(如单数据中心)。
-
异构硬件(如 H100 用于 Prefill,H20 用于 Decode)很难独立扩展,因为无法跨低带宽网络高效传输 KVCache。
-
资源弹性差:一旦硬件比例固定,难以适应请求长度、缓存命中率的变化。
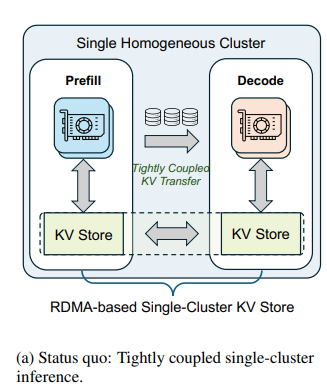
单数据中心设计问题大,跨数据中心又难存在各种诸如带宽等软硬件扩展的瓶颈,如何解决呢?
关键观察:混合注意力模型能大幅降低 KVCache
论文指出,新型混合注意力模型(如 Kimi Linear、SWA + GQA)中,只有少数全注意力层产生随序列长度增长的 KVCache,多数线性复杂度层只产生固定大小的状态。
通过建模分析,团队发现:
KV Throughput(单位时间产生的 KVCache 大小)仅仅是稠密模型1/4,甚至最低可以达到 1/36。
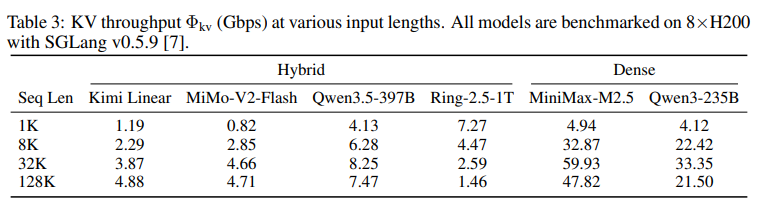
这种数量级级别的 KVCache 减少,就好比:以前传输数据像是在搬运一整座山,现在只需快递一张光盘。堪比对 KVCache 来了一场算法级的“物理瘦身”。
这使得 KVCache 通过普通以太网跨数据中心传输成为可能。
除了这一观察,论文中 Kimi 团队还提出了一个构建跨数据中心的万亿模型的核心思路:
跨数据中心 KVCache 的核心思路,并不是把所有 prefill 都外包,而是在“远程 prefill 加速收益大于传输成本”时,有选择地将解耦后的 LLM 服务扩展到单一集群之外。
PrfaaS 的核心思路:
如何把推理“海啸”变成“溪流”?
那么,理论上可行之外,实际工程方面,PrfaaS 是怎么实现的呢?不得不说,团队确实是做到了“算法+系统”的双重创新。
PrfaaS-PD 架构的整体思路很清晰,即将本地 PD 集群和 PrfaaS 集群的处理职责区分开:
专用的 PrfaaS 集群:在高吞吐、成本更优的加速器上执行计算密集型长上下文 prefill(未命中前缀的缓存),并通过通用以太网将生成的 KVCache 流式传输到本地 PD 集群;
本地 PD 集群:处理短请求或已命中缓存等对带宽不友好的请求,负责 Decode。
注意:两者是通过普通以太网(如 VPC、专线)来传输 KVCache 的。
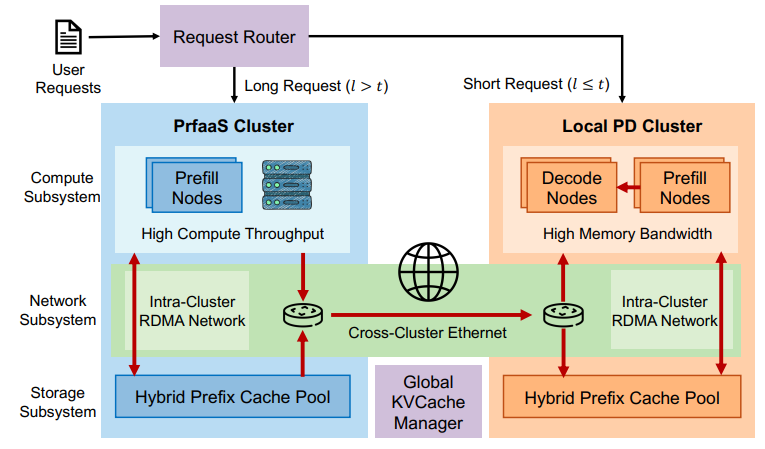
而专用 PrfaaS 集群的灵魂设计就在于: 混合前缀缓存池(Hybrid Prefix Cache Pool)的设计。
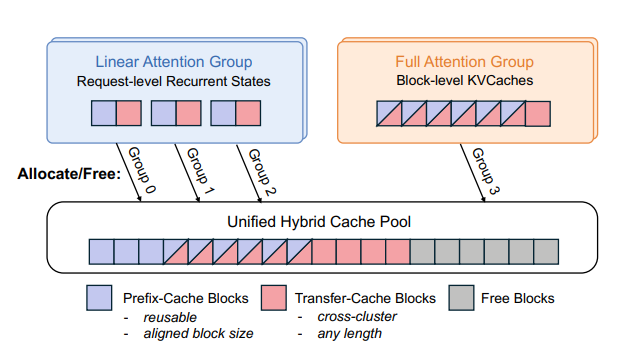
虽然混合注意力模型的 KVCache 变小了,但类型却也多元了。
在混合模型中,线性注意力或 SWA 层的循环状态是请求级别的:它们的大小与输入长度无关,并且只有当缓存长度完全匹配时才能被复用。
相比之下,全注意力层的 KVCache 是块级别的:它们随输入长度线性增长,并支持部分前缀匹配。
这种异构性对传统的全层统一 KVCache 存储范式提出了挑战。
显然,混合前缀缓存池的设计解决的正是这个问题,同时也可以做到跨集群、跨数据中心的 KVCache 高效传输与复用。
篇幅关系,这里用简单一点的话来解释如何做到的:分开管理,内存统一。缓存池将线性状态和全注意力 KVCache 分开管理,但这些组具有对齐的块大小,允许所有组从一个共享的 KVCache 池中分配和释放块。
多说一嘴,这个缓存池是 Kimi 团队基于 vLLM 的混合 KVCache 管理器发明的。感兴趣的朋友可以翻阅相关的论文。
内置双尺度调度,避免推理卡顿
解决了这个问题之后,还要解决的则是调度问题。PrfaaS 并非天真地外发所有任务。对此,研究团队内置了聪明的“分流”逻辑:
-
选择性卸载:只有增量长度 > 阈值的请求才发往 PrfaaS,避免短请求浪费跨集群带宽。“短请求本地消化,长请求异地处理”。系统会自动识别:只有当文本足够长(比如超过 19.4K token),才派发给远端的高算力中心。
-
带宽感知:实时监控 egress 带宽和队列深度,动态调整路由。考虑缓存亲和性:如果某集群已有部分前缀缓存,优先使用,必要时跨集群传输缓存。
就像手机导航会避开拥堵路段,调度器会监控网速。如果两地之间的网线“堵车”了,它会自动调整路由,优先保证本地推理不卡顿。
此外,调度策略上,团队还给出了一种双时间尺度调度策略:
-
短时:根据带宽和缓存分布动态路由请求。
-
长时:根据流量变化调整 PD 集群内的 Prefill/Decode 实例比例,重新优化阈值 t。
硬件解构:让 H200 专心“冲刺”
不仅如此,在实测中,Kimi 团队用 H200 组成 PrfaaS 集群(专攻计算,负责 Prefill),而用 H20 集群负责 Decode(解码)。
这种“跨机房合体”让每颗芯片都跑在自己的舒适区,可以说为业界解决了“算力够、带宽不够”的尴尬问题。
实测数据:1T模型的“降维打击”
在这项针对 1 万亿参数级混合架构模型(类似 Kimi Linear)的实测中,PrfaaS 交出了一份足以重塑行业逻辑的成绩单!
具体部署如下:
PrfaaS 集群:32 × H200(高算力)
本地 PD 集群:64 × H20(带宽优化)
跨集群带宽:100 Gbps 以太网
首先,相比传统部署,PrfaaS 系统吞吐量提升了 54%。比无调度的异构 PD 提升 32%。
这还没完,结果显示,如果在同等成本下,PrfaaS 系统吞吐量仍提升约 15%。
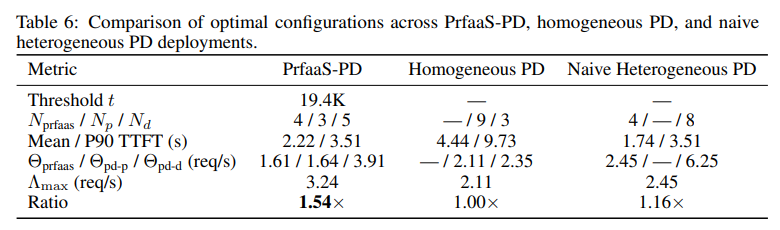
其次,延迟也大幅降低: 代表用户体验的 P90 首字延迟(TTFT)大幅降低 64%。
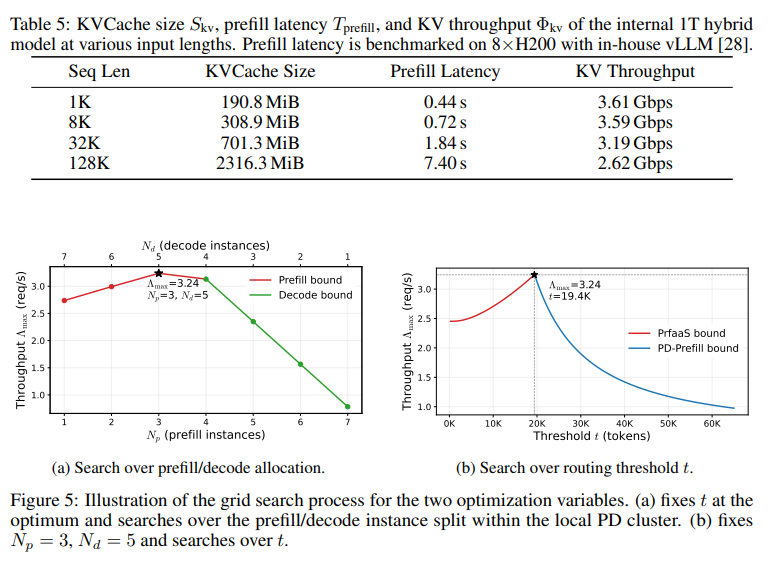
更重要的是,成功实现了跨城市级别顶级算力调度。据介绍,PrfaaS 处理万亿模型时,跨中心带宽占用仅为 13 Gbps(占 100 Gbps 的 13%),远低于稠密模型的需求。
这意味着,你用一根最普通的 100G 网线,就能在两座城市之间调度顶级算力。
终结“唯显卡论”:普通网线也能调度全球算力
大模型迎来“东数西算”时代
这是大模型狂奔的第四个年头。在推理算力日益紧缺的语境之下,Kimi团队 之一 PrfaaS 架构的出现,恰逢其时。
这篇论文不止是提出了跨城市跨数据中心的分布式算力AI框架,还给出了许多关于未来AI推理的想象空间。
小编看来,有这样几点值得讨论:
首先,Kimi 这篇研究让“异地推理”的真正落地更近了一步。大模型领域的“东数西算”被它证明完全在工程上是可行的:以后 Prefill 可以放在电费便宜的西北,Decode 放在靠近用户的北上广。这一点就足够 amazing。
其次,异构芯片也终于有了大规模采用的希望。推理非得全用 H100?当然不是。
大家同样可以用国产大算力芯片做 Prefill 中心,用高带宽芯片做 Decode 中心。而 PrfaaS 就像“粘合剂”,让不同品牌、不同地域的芯片也可以很好地协同。
最后,则是二阶影响。大家或许看到“吞吐量提升”、“延迟降低”这样的术语感觉不深,但这背后其实都会真实反映到大家的“钱袋子”上。
因为这些指标的改进,折射到模型侧,就意味着 1T 模型的处理效率翻倍,意味着处理千万级上下文的成本将大幅下降,而折射到用户侧,则意味着 API 价格的实打实的下降!
总之,不难预见,模型圈很快将会经历“单体机房”向“分布式算力云”的转变。
而月之暗面的 PrfaaS 也再一次用实际效果向外界证明:通过算法和工程的协同进化,用普通网线也可以调度全球算力!而大家的模型订阅价格降下来的希望也更大了!
从这个维度上看,AI 的普及才真正开始。
论文地址:
https://arxiv.org/pdf/2604.15039v1
本文来自转载51CTO技术栈 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫