今天上午,DeepSeek-V4 发布并开源
DeepSeek V4 分两档
- Pro 是 1.6T 总参、49B 激活
- Flash 是 284B 总参、13B 激活
两档都支持 1M token 上下文、都开源,并给出了技术报告

能干什么
V4-Pro 在四个方向上都跨过了一个台阶
Agent 能力
Agentic Coding 评测里 V4-Pro 已经到当前开源最佳水平。DeepSeek 公司内部已经把 V4 作为默认编码模型,反馈是优于 Sonnet 4.5,交付质量接近 Opus 4.6 的非思考模式,和 Opus 4.6 的思考模式还有差距。这次还专门为 Claude Code、OpenClaw、OpenCode、CodeBuddy 这几个主流 Agent 产品做了适配优化,代码任务和文档生成任务都有提升
世界知识
Pro 在知识评测里大幅领先其他开源模型,稍逊于 Gemini-3.1-Pro。SimpleQA-Verified 拿到 57.9,比 Opus-4.6-Max 的 46.2 和 GPT-5.4-xHigh 的 45.3 都高出一截
推理性能
数学、STEM、竞赛代码三类测评里,Pro 超过所有已公开评测的开源模型,和世界顶级闭源模型打平。LiveCodeBench Pass@1 拿到 93.5,Codeforces Rating 3206,都是对比组最高
长文本
Pro 在 1M token 的合成基准和真实任务上都很强,学术评测超过 Gemini-3.1-Pro。MRCR 1M 拿到 83.5,CorpusQA 1M 拿到 62.0
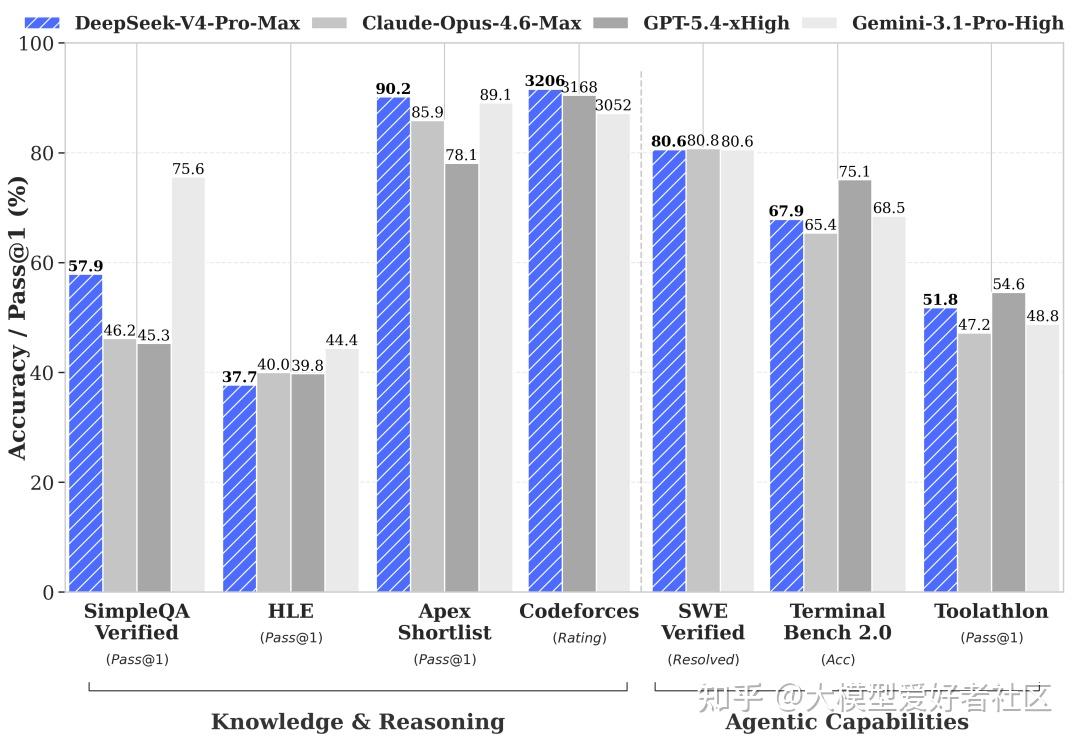
V4-Pro-Max 在 8 个核心 benchmark 头部模型对比
Flash 模型则是另一种取舍:主打便宜,知识题稍逊一筹,但推理能力接近 Pro。在简单的 Agent 任务下,素质和 Pro 旗鼓相当,高难度任务还得看是 Pro
这种分档思路,类似 Claude 的 Sonnet/Opus、GPT 的 Mini/Pro
1M 成了标配
以前 DeepSeek 网页版最多 128K,1M 是灰度测试。从今天开始 1M 是全线官方服务的默认上下文,包括 chat、API、网页、App
这个变化背后,是新的注意力机制
V4 在 token 维度做压缩,再叠加 DeepSeek 自家的 DSA 稀疏注意力。效果是 1M 上下文下,V4-Pro 的单 token 推理 FLOPs 只要 V3.2 的 27%,KV cache 只要 V3.2 的 10%。V4-Flash 更极致,单 token FLOPs 只要 V3.2 的 10%,KV cache 只要 7%
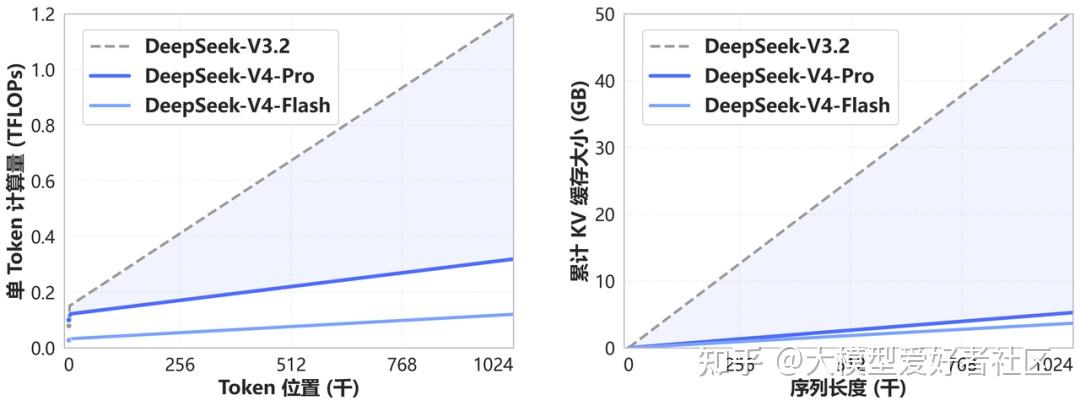
V4 系列对 V3.2 的算力和显存对比,随上下文长度拉得越长差距越明显
对于一百万 token 来说,一次性塞入《三体》三部曲,还绰绰有余,,再叠加 V4 在多轮对话里保留全部 reasoning 历史,长程 Agent 任务的连贯性也有了保障

架构三件套
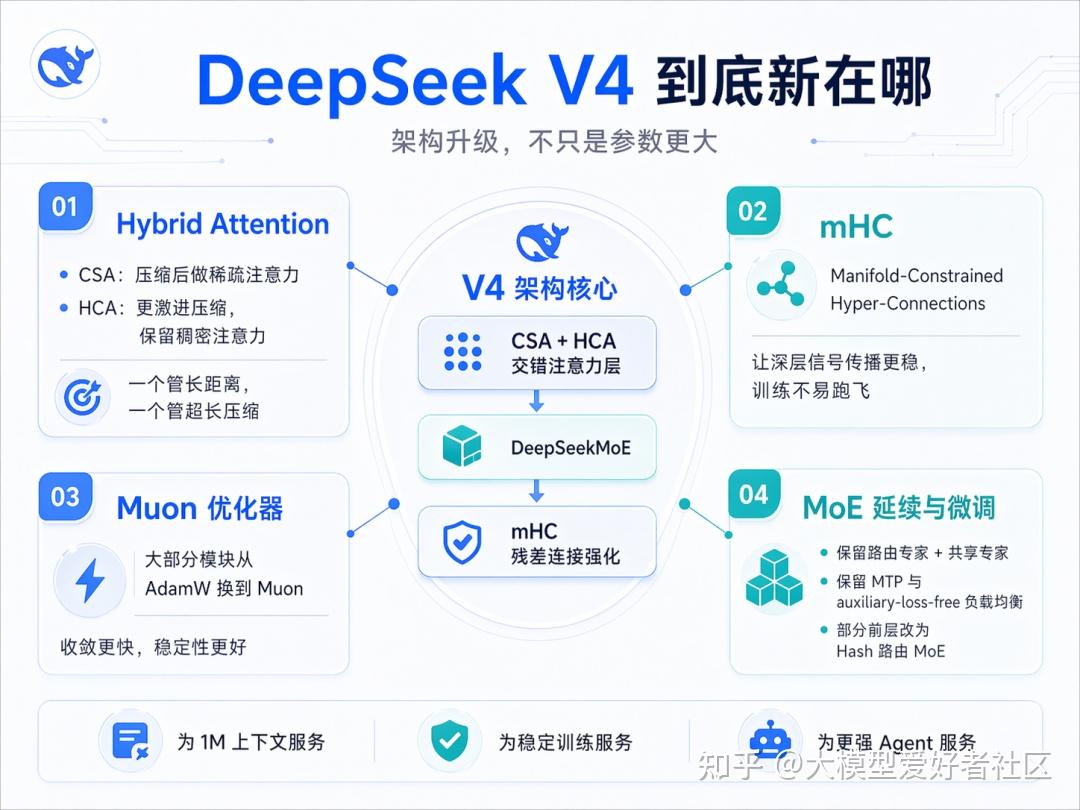
先简单看一下 DeepSeek V4 的架构图,看不懂也不要紧,后面有助记版(方便大家吹牛逼)
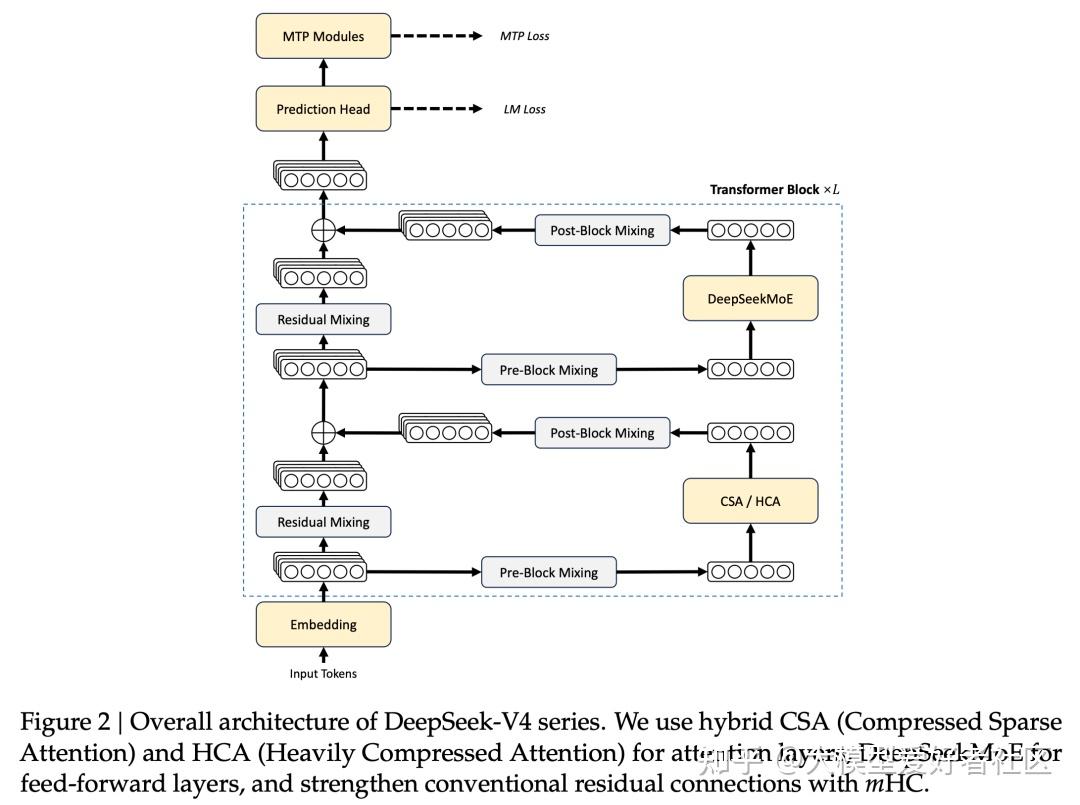
V4 的 MoE 框架沿用 V3 的 DeepSeekMoE,并做了三处升级
下面具体说说这三个升级
Hybrid Attention:CSA + HCA
两种注意力层交错使用
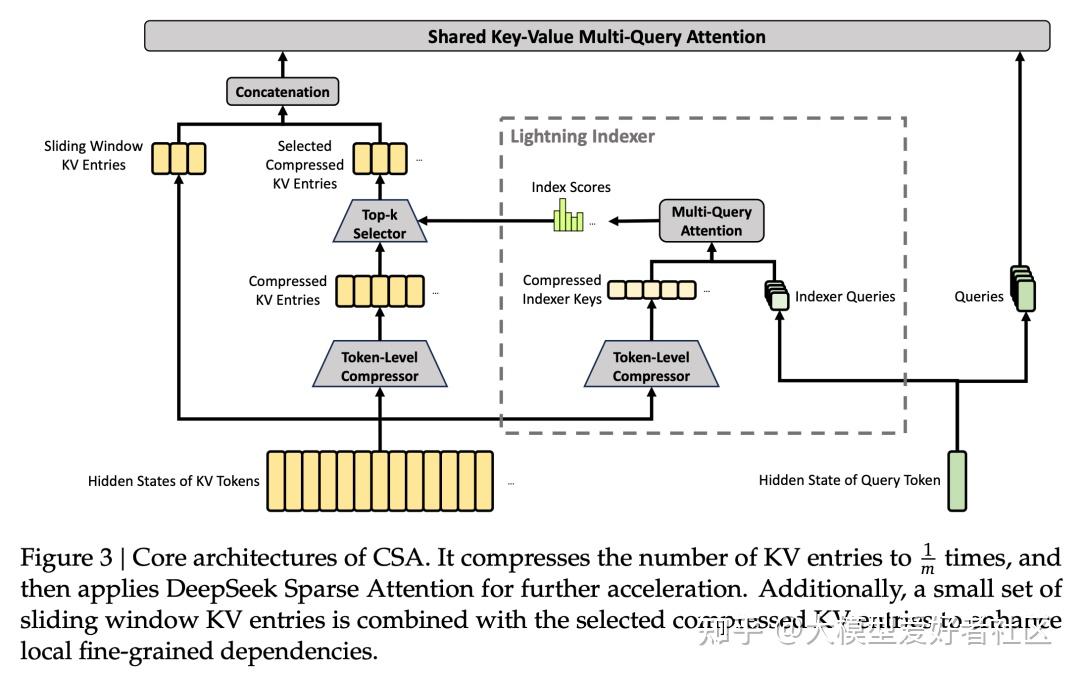
CSA(Compressed Sparse Attention)
的做法是先把每 m 个 token 的 KV 压成一个 entry,再跑 DSA 稀疏注意力,每个 query 只关注 k 个压缩 entry。Flash 版本里 m=4,indexer query head 64 个,head dim 128,sparse attention top-k=512
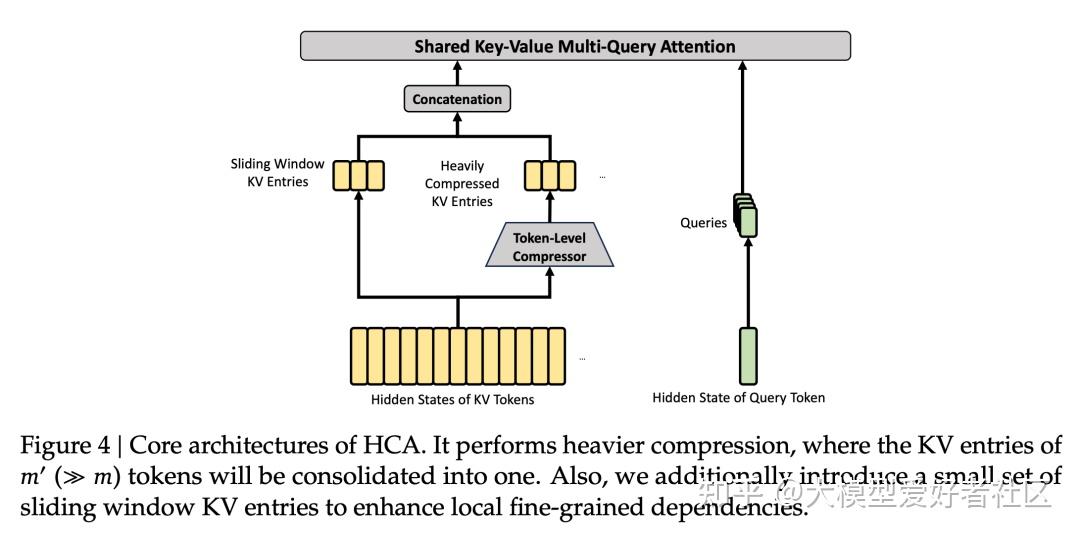
HCA(Heavily Compressed Attention)
这个更激进,每 m′ 个 token 压一个,m′ 远大于 m,Flash 里 m′=128。HCA 不做稀疏选择,保持稠密注意力
这两个东西,一个管长距离,一个管超长压缩。除了核心结构,CSA 和 HCA 还共用了几个细节:
- query 和 KV entry 的最后 64 维加 RoPE,做 partial rotary 位置编码;
- core attention 用 attention sink 技巧,给每个 head 加可学习的 sink logit;
- 同时各自挂一个 sliding window attention 分支处理近邻 token,避免被压缩压掉局部依赖
mHC:流形约束的残差连接
mHC 全称 Manifold-Constrained Hyper-Connections。用流形约束强化残差连接,把残差映射矩阵约束在双随机矩阵流形(Birkhoff polytope)上。这个约束保证了映射矩阵的谱范数有界、传播非膨胀,深层堆叠也不跑飞
实现上,mHC 把残差宽度和 hidden size 解耦,用一个比 hidden size 小得多的 expansion factor n(V4 里 n=4)控制额外开销。参数动态生成,分输入相关和输入无关两部分,输入相关那部分由当前 token 的 hidden state 经 RMSNorm 后产出。这是 DeepSeek 在 1 月公开的论文成果,V4 是第一次进旗舰模型
Muon 优化器
DeepSeek 把大部分模块的优化器从 AdamW 换成 Muon。embedding、prediction head、静态 bias、RMSNorm 这些保留 AdamW,其余走 Muon
Muon 的核心是用 Newton-Schulz 迭代做矩阵正交化,DeepSeek 在标准 Newton-Schulz 基础上做了改进,叫 Hybrid Newton-Schulz。再叠加 Nesterov trick 和 RMS rescaling,让 AdamW 的超参数可以直接复用。收敛更快,稳定性更好
另外,MoE 部分虽然继承自 V3,但也有改动
门控函数从 Sigmoid 换成 Sqrt(Softplus),前几层 dense FFN 换成 Hash 路由的 MoE,路由目标节点数不再限制,auxiliary-loss-free 负载均衡和 sequence-wise balance loss 一起用。Flash 的 MoE 配置是 1 个共享专家加 256 个路由专家,每 token 激活 6 个,专家 hidden dim 2048
训练账
V4-Flash 预训练 32T token,V4-Pro 预训练 33T token。token 化沿用 V3 的 tokenizer,扩了几个 special token,词表保持 128K。文档拼接和 Fill-in-Middle 策略也继承自 V3,做了 sample-level attention masking
精度方面,MoE 的路由专家参数用 FP4 精度,其他参数大部分用 FP8。这是 DeepSeek 第一次在旗舰模型上全面跑 FP4 量化感知训练。当前硬件上 FP4 乘 FP8 的峰值算力和 FP8 乘 FP8 一样,理论上新硬件可以做到快 1/3
训练 schedule 上,序列长度从 4K 起步,逐步扩到 16K、64K、最后到 1M。注意力机制先用稠密注意力暖到 1T token,64K 序列长度时切到稀疏注意力,再继续训练。batch size 从小逐步爬到 75.5M token。学习率 linear warmup 2000 步,2.7×10⁻⁴ 维持大部分训练,最后 cosine 衰减到 2.7×10⁻⁵
稳定性上做了两件事。Anticipatory Routing 是把 backbone 网络和 routing 网络的同步更新解耦,用前一步的网络参数提前算好这一步的 routing indices,避免 loss spike,几乎没有额外开销。SwiGLU Clamping 借自 GPT-OSS 的做法,对 SwiGLU 输出做截断,消除 outlier,对训练性能没有损失
Base 模型的评测里,V4-Flash-Base 用 13B 激活在大多数任务上已经追平甚至超过用 37B 激活的 V3.2-Base,参数效率明显提升
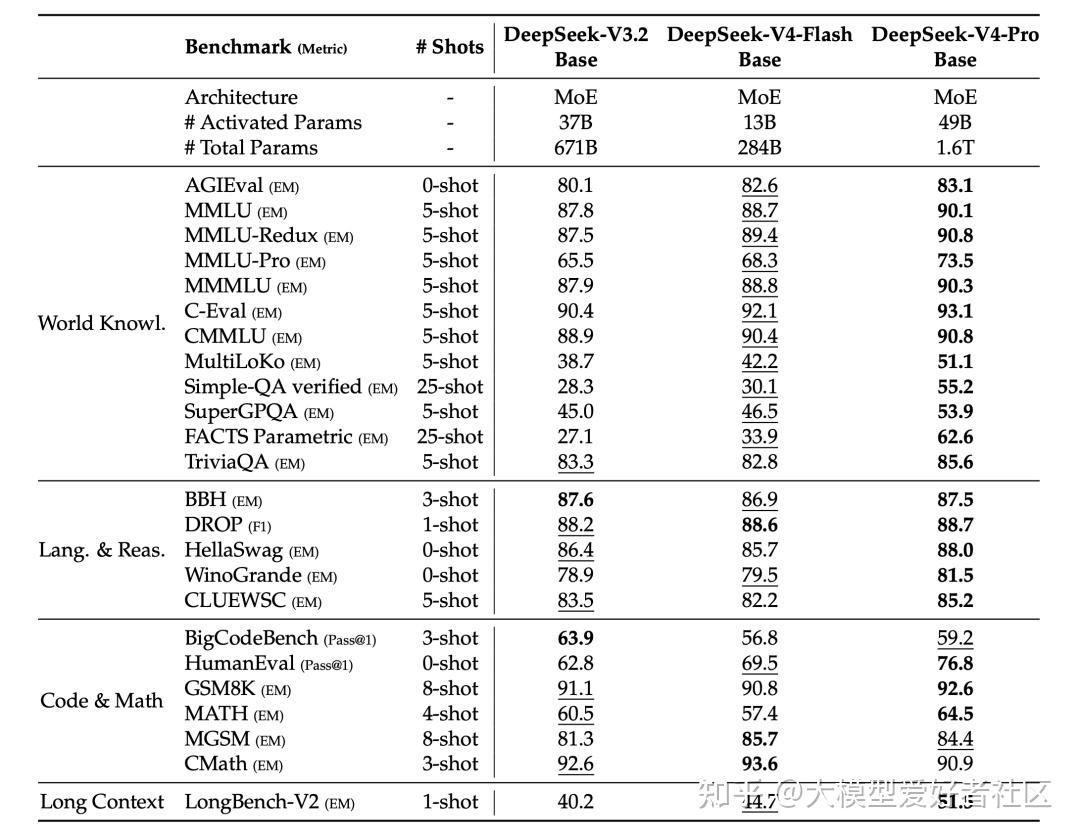
MMLU 88.7、MMLU-Redux 89.4、C-Eval 92.1、CMMLU 90.4 都比 V3.2-Base 高。Code 类任务里 HumanEval Pass@1 拿到 69.5,比 V3.2-Base 的 62.8 高出 7 个点。V4-Pro-Base 在世界知识、推理、代码、长文本四个方向上全面拉开和 V4-Flash-Base 的差距,Simple-QA verified 拿到 55.2,FACTS Parametric 拿到 62.6,是 V3.2-Base 的两倍多
后训练
V3.2 的后训练是 SFT 加 mixed RL。V4 把 mixed RL 阶段整个换成了 On-Policy Distillation(OPD),这是这次后训练里最关键的方法学替换
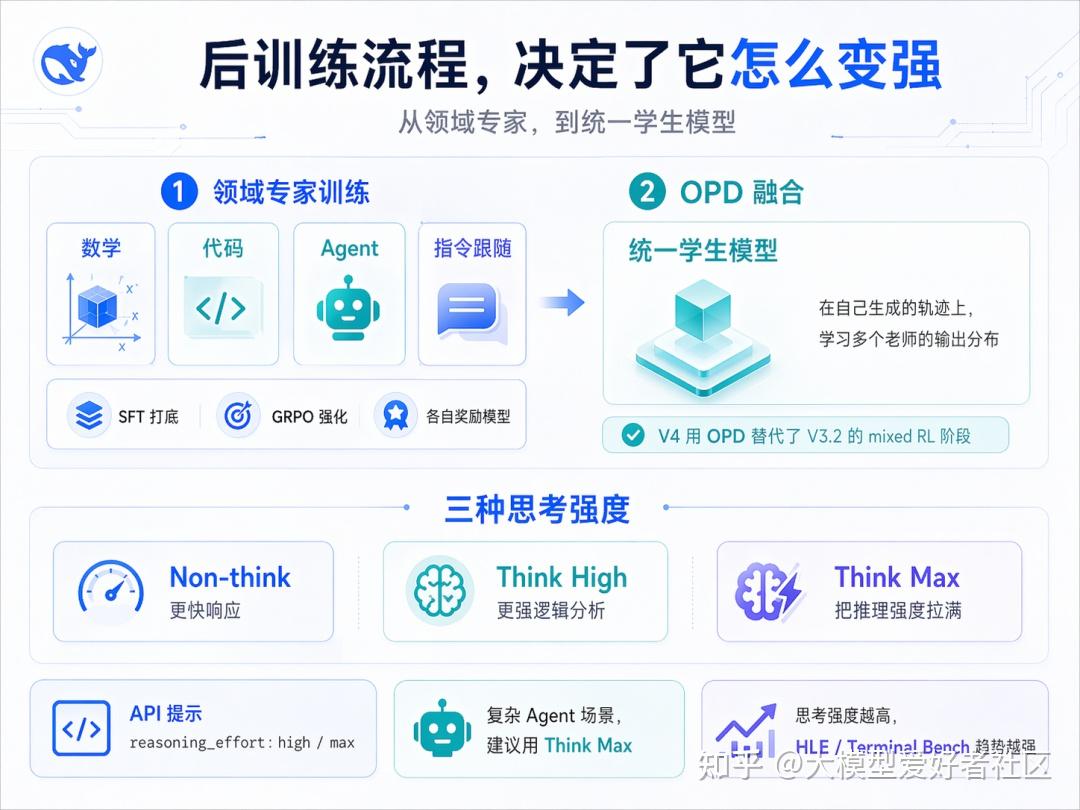
在后训练阶段,整体流程拆成两步:
- 第一步是 领域专家培育(Specialist Training),每个目标领域单独训练一个专家模型
- 第二步是 On-Policy Distillation 融合,把所有专家合到一个学生模型里
第一步:领域专家培育
每个领域走相同的两段流程:SFT 打底,再用 GRPO 做 RL,每个领域配自己的奖励模型。已经做过的领域包括数学、代码、Agent、指令跟随等
每个领域还要训三种推理强度的子版本,分别对应 Non-think、Think High、Think Max。三种模式在 RL 训练时用不同的 length penalty 和 context window:Non-think 用短上下文窗口,Think High 用 128K,Think Max 用 384K,把推理预算拉满
做 Agent 类专家时还引入了 Quick Instruction 机制。聊天产品里有很多附加任务,比如判断是否触发搜索、识别意图。传统做法是另一个小模型做这些,每次都要重新 prefill。V4 的做法是给输入序列直接附一组 special token,每个 token 对应一个附加任务,复用现成的 KV cache,省掉冗余 prefill,把首字延迟(TTFT)压下来
第二步:On-Policy Distillation 融合
第二步把所有专家合到一个学生模型里。做法是让学生在自己生成的 trajectory 上学多个 teacher 模型的 output 分布。这个范式比传统的 SFT 蒸馏更接近 RL 的精神,因为分布匹配是在学生当前策略下的状态分布上做
为了支撑 OPD 在万亿规模上跑通,DeepSeek 做了几件 infra 上的事。teacher 权重统一存到中心化分布式存储,按需加载、用 ZeRO 风格 sharding,I/O 和 DRAM 都减压。词表 100K+ 的 logits 不能全展开存盘,只缓存学生 trajectory 上必要的部分。rollout 用 FP4 量化加速。rollout 服务支持抢占和容错,靠 token 级别的 WAL 加 KV cache 持久化,硬件出错也能从断点续上,避免重新生成带来的长度偏差
百万 token 上下文的 RL 也单独优化。rollout 数据拆成 metadata 和 per-token 两层,metadata 全量加载做 shuffle 和 packing,per-token 用共享内存懒加载、用完即放,CPU 和 GPU 内存都不堆积
Agent 训练靠一套叫 DSec 的 sandbox 基础设施。统一接口屏蔽 container、microVM、TTY 等差异,单集群可以扛几十万个 sandbox 并发。镜像走 3FS 分层加载,毫秒级启动。每个 sandbox 维护一份全局有序的 trajectory log,记录每条命令和结果。训练任务被抢占时,sandbox 资源不释放,恢复时直接 fast-forward 到上次断点,避免重复执行非幂等操作
三种思考强度
V4-Pro 和 V4-Flash 都支持三种思考强度:Non-think、Think High、Think Max
- Non-think。直觉式回应,不展开思考。日常对话、低风险决策走这个。返回格式是空的 加 summary
- Think High。有意识的逻辑分析,慢但准。复杂问题、规划类任务走这个。返回格式是
思考加 summary - Think Max。把推理强度推到极限,探索模型推理能力的边界。需要特殊 system prompt 触发。返回格式同 Think High

但另外来说,Flash-Max 在大多数任务上能逼近 Pro-High。预算紧的时候 Flash 够用,关键任务再上 Pro
从 V3.2 到 V4 的另一个变化,是 thinking 内容的处理
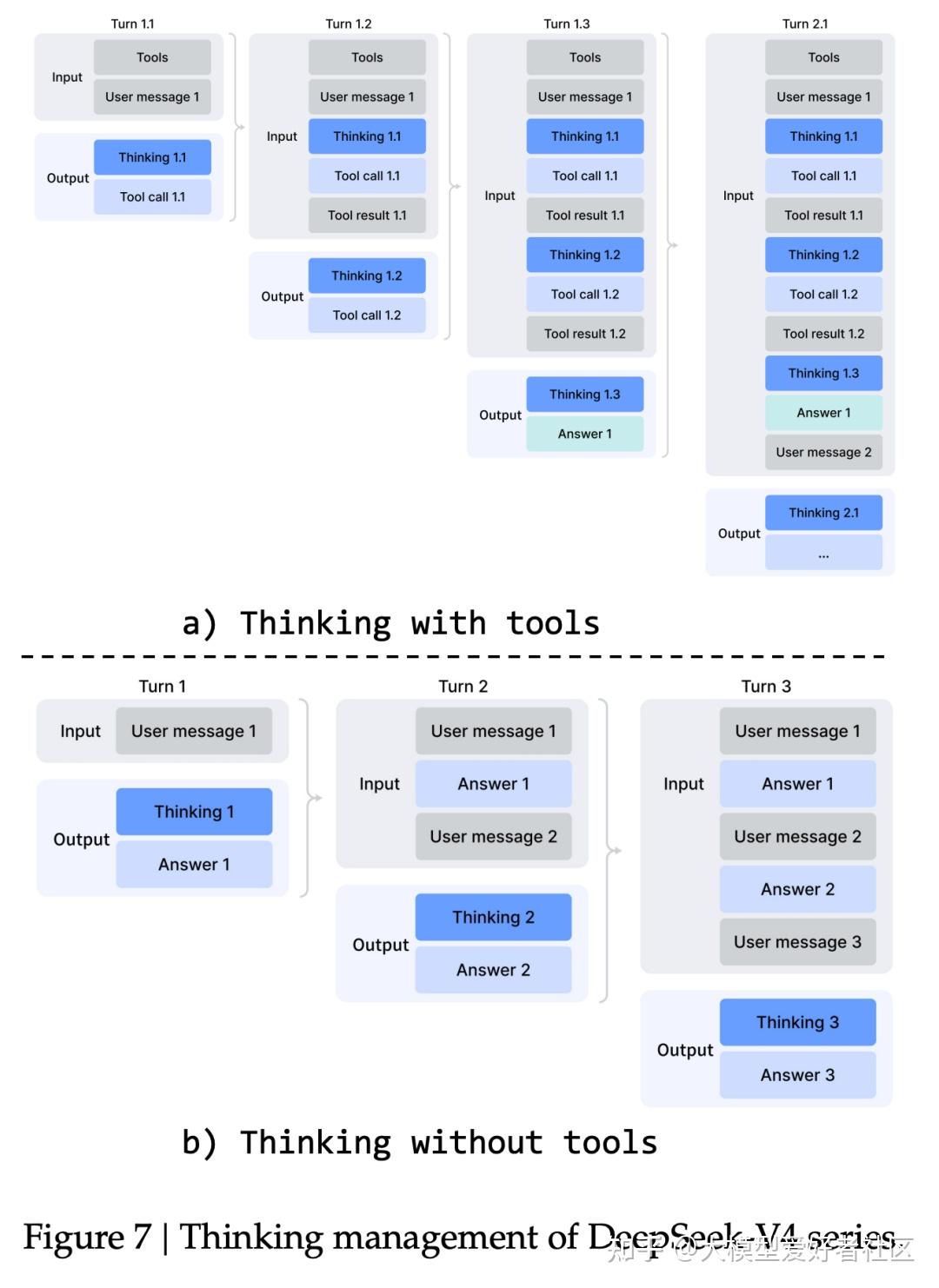
- V3.2 在每个新用户消息开始时丢弃 thinking trace
- V4 在工具调用场景里完整保留全部 reasoning content,包括跨用户消息边界
这项改进对对长程 Agent 任务的连贯性有直接帮助,模型能在多轮调用之间维持一条完整的累积思考链。
基础设施这次也是重点
技术报告,里给「基础设施」单独留了一整章,份量跟架构和训练并列

细粒度专家并行通信
DeepSeek 自己改写的 DeepGEMM 推出了 mega-kernel MegaMoE,对比强 baseline,通用推理 1.50 到 1.73 倍加速,RL rollout 这种小批长尾场景能到 1.96 倍

这个 kernel 在 NVIDIA GPU 和华为昇腾 NPU 两个平台上都做了验证,已经开源
Kernel 开发
从 CUDA/Triton 切到了北大开源的 TileLang。TileLang 把大部分 host-side 逻辑用 Host Codegen 移到生成代码里,CPU 侧 validation overhead 从几百微秒压到很低。同时 TileLang 提供了 IEEE 兼容的数值原语和精确的 layout 标注,能做到和手写 CUDA 比特级一致
确定性 kernel 库
所有 kernel 做了 batch invariance 和 deterministic 两件事。同一个 token 在批里的位置变了,输出比特一致;同一个输入跑两次,输出也比特一致。这两件事对 debug、稳定性分析、post-training 一致性都有用。pre-training、post-training、inference 三段流水线之间,能做到比特对齐
FP4 量化感知训练
FP8 mixed precision 框架基本沿用 V3,没改 backward 流程。FP4 用 simulated quantization:forward 时把 FP8 master weight 量化到 FP4 跑,backward 时梯度直接传给 FP32 master weight,等价于 STE(Straight-Through Estimator)穿透量化算子。inference 和 RL rollout 阶段直接用真 FP4 权重,省内存、加速
Muon 的工程化实现
Muon 需要完整的梯度矩阵做参数更新,跟 ZeRO 的 element-wise 切分有冲突。DeepSeek 设计了一套 hybrid ZeRO bucket 分配策略,dense 参数限制并行度并用 knapsack 算法做负载均衡,MoE 路由专家参数用 EP 分组分配。整体能跑下来,没有牺牲并行性
On-Disk KV Cache
推理框架的 KV cache 管理重新做了。CSA 和 HCA 的 KV entry 异质,sparse 选择又引入了额外维度,所以专门设计了一套 KV cache layout,拆成 state cache(SWA + 未压缩 tail)和 classical KV cache(CSA、HCA 的压缩 entry)两块。开盘存储方面,CSA 和 HCA 的压缩 entry 全部存到 disk,请求命中前缀时直接读复用;SWA 因为体量大约是压缩 entry 的 8 倍,给了三种策略可选:全缓存、定期 checkpoint、零缓存即重算
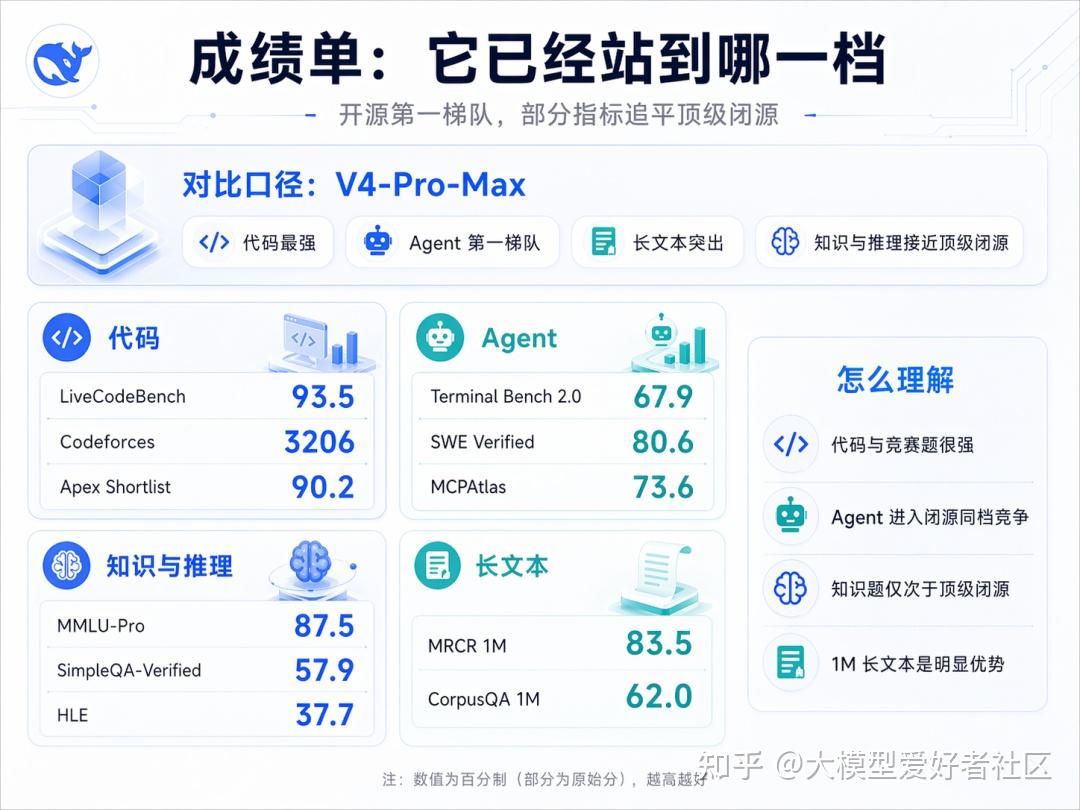
成绩单:V4-Pro-Max 站到哪一档
对比口径是 V4-Pro-Max,对手是 Opus-4.6-Max、GPT-5.4-xHigh、Gemini-3.1-Pro-High、K2.6-Thinking、GLM-5.1-Thinking 五个,覆盖了开源和闭源的当下顶尖位置
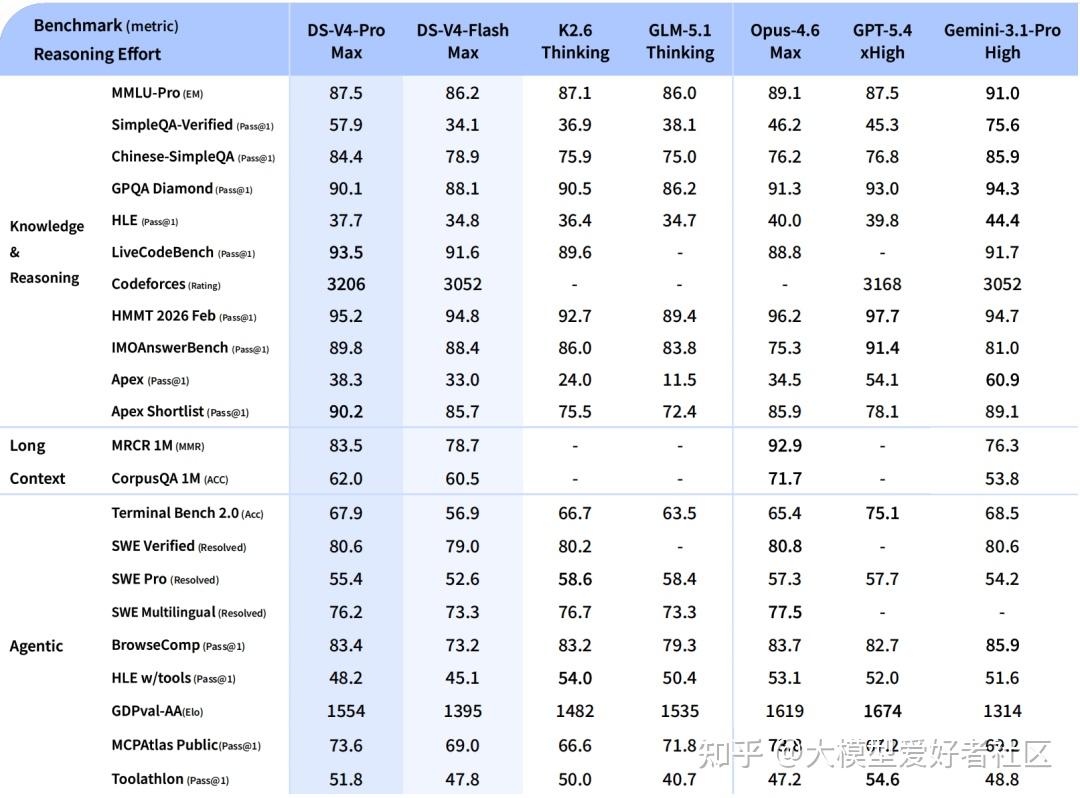
代码方面,LiveCodeBench Pass@1 93.5、Codeforces Rating 3206、Apex Shortlist 90.2,三项都是对比组最高。Codeforces 上 3206 比 GPT-5.4-xHigh 的 3168 高一点
知识方面,MMLU-Pro 87.5 接近对比组中位,SimpleQA-Verified 57.9 高于除 Gemini 之外所有模型,Chinese-SimpleQA 84.4 接近 Gemini 的 85.9。HLE 37.7,比 Gemini 的 44.4 有距离,是最明显的短板
Agent 方面,Terminal Bench 2.0 67.9、SWE Verified 80.6、SWE Multilingual 76.2、MCPAtlas 73.6,整体和 Opus-4.6-Max、K2.6-Thinking 在同一档。GDPval-AA 1554 比 GPT-5.4-xHigh 的 1674 落后一些
长文本方面,MRCR 1M 83.5、CorpusQA 1M 62.0。MRCR 上超过 Gemini-3.1-Pro 的 76.3,但仍然低于 Opus-4.6 的 92.9。CorpusQA 同样是 Opus 第一。在 128K 范围内 V4 的 retrieval 表现非常稳,128K 之后开始下降但仍然有竞争力。
另外,数学和形式化推理这块,HMMT 2026 Feb 拿到 95.2,IMOAnswerBench 89.8。Putnam-2025 上以 hybrid formal-informal 推理拿到 120/120 满分,对比 Aristotle 100/120、Seed-1.5-Prover 110/120、Axiom 120/120
1M 长上下文的 MRCR 8-needle 测评里,V4-Pro-Max 在 8K 范围内能到 0.94,128K 能到 0.92,512K 还能维持 0.85,1M 衰减到 0.66,但仍然是同档对比里最稳的开源模型。Flash-Max 在 128K 内表现接近 Pro,128K 之后衰减更快。这意味着 V4 在中等长度(200K 以下)的真实工作流里基本不会丢信息,只有在 512K+ 的极限场景下才需要担心 retrieval 漂移
真实任务上的表现
Benchmark 之外,V4 还做了几个真实任务的对比

中文写作
这是 DeepSeek 用户最常用的场景之一。V4-Pro 对 Gemini-3.1-Pro 在功能性写作上的胜率 62.7%,Gemini 34.1%。给 Gemini 的解释是它在中文写作里经常自己加戏,盖过用户的明确要求。创意写作上 V4-Pro 对 Gemini-3.1-Pro 的指令跟随胜率 60.0%,写作质量胜率 77.5%。但在最难的多轮约束写作上,Opus 4.5 仍然有 52.0% 对 45.9% 的胜率优势
搜索
Chatbot 的核心能力之一。Non-think 走 RAG,Thinking 走 Agentic Search。pairwise 评测里 V4-Pro 在客观和主观 Q&A 上都明显优于 V3.2,最大优势在 single-value 检索和 planning & strategy 类任务。在比较类和推荐类任务上,V3.2 还有竞争力。Agentic Search 比 RAG 在复杂任务上明显领先,成本只略高于 RAG
白领任务
30 个中文高级专业任务,分析、生成、编辑三类。V4-Pro-Max 对 Opus-4.6-Max 总体胜率 53%、平 10%、负 37%。分维度看,任务完成度 96.68 高于 Opus 的 88.88,内容质量 87.76 接近 Opus,指令跟随 84.06 略低于 Opus,格式美观度 72.68 比 Opus 的 86.52 有差距,特别是在 PPT 类任务的视觉呈现上
V4-Pro 在 Agent 框架下生成的 PPT 内页,营销策划完整版
Code Agent
从 50 多位内部工程师日常工作里抽的 30 个真实 R&D 任务,覆盖 PyTorch、CUDA、Rust、C++ 等多种技术栈。V4-Pro-Max 通过率 67%,高于 Sonnet 4.5 的 47%,接近 Opus 4.5 的 70% 和 Opus 4.5 Thinking 的 73%,不如 Opus 4.6 Thinking 的 80%。85 位 DeepSeek 员工被问「V4-Pro 能不能作为你日常编码的主力模型」,52% 说 yes,39% 倾向 yes,9% 以下说 no。反馈里提到的短板是小错误、模糊 prompt 的解读、偶尔过度思考
整体看下来,V4 在中文写作、专业文档、代码工程这些 DeepSeek 用户基数最大的场景上都明显往前了一步。短板集中在 PPT 视觉呈现这种格式美感类任务、还有最复杂的多轮编码场景,Opus 仍然有领先
API 怎么用
新模型名:deepseek-v4-pro 和 deepseek-v4-flash,base_url 不变
接口兼容:同时支持 OpenAI ChatCompletions 和 Anthropic 接口两套标准
思考模式:thinking.type 设 enabled 或 disabled,默认开。思考强度 reasoning_effort 取 high 或 max。对普通请求默认 high,对 Claude Code、OpenCode 这类复杂 Agent 请求自动升 max。兼容考虑下 low 和 medium 映射为 high,xhigh 映射为 max
旧模型名过渡:deepseek-chat 和 deepseek-reasoner 将在 2026-07-24(三个月后)停用。过渡期内这两个名字分别指向 deepseek-v4-flash 的非思考模式和思考模式
定价。V4-Pro 输入缓存命中 1 元/百万 token,未命中 12 元/百万 token,输出 24 元/百万 token。V4-Flash 对应 0.2 元/1 元/2 元
定价表附了一行小字:受限于高端算力,目前 Pro 的服务吞吐十分有限,预计下半年昇腾 950 超节点批量上市后,Pro 的价格会大幅下调
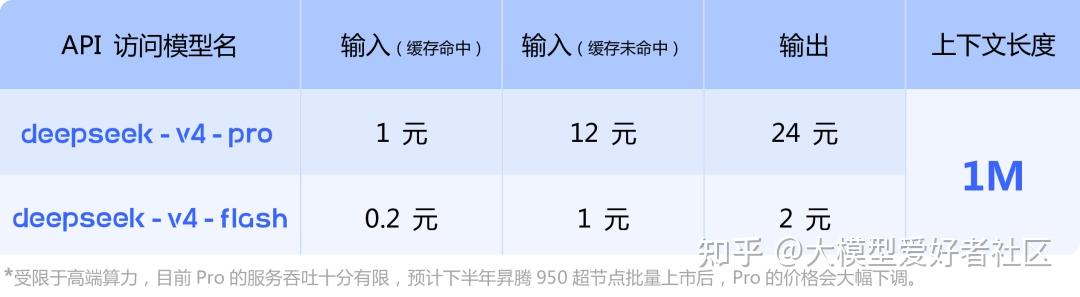
V4-Pro 和 V4-Flash 的 API 定价,下半年昇腾 950 上市后 Pro 还会再降
注意:旧模型名 7 月 24 号到期
能现在用
网页 http://chat.deepseek.com 或官方 App 可以直接对话。API 改 model 参数就能用。开源权重在 HuggingFace 和 ModelScope 上,MIT 协议,有 Pro/Flash 各自的 Base 和 instruct 版本
本地部署推荐采样参数 temperature=1.0、top_p=1.0。Think Max 模式上下文窗口建议至少 384K。Chat template 这次没出 Jinja 格式,给的是一个独立的 encoding 模块,包 Python 脚本和测试用例,把 OpenAI 兼容格式编码成模型输入串、再解析模型输出
在技术报告的结尾,DeepSeek 还规划了未来方向:
- 更稀疏的 embedding 模块
- 低延迟架构
- 长程多轮 Agent 任务
- 多模态

另外,DeepSeek V4 目前仍不支持多模态
本文来自转载赛博禅心 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫