 2026年4月,AI大模型战场密集发布前所未有。OpenAI发布GPT-5.5,DeepSeek推出V4 Pro/Flash双版本,Anthropic更新Claude Opus 4.7,月之暗面开源Kimi K2.6,智谱发布GLM-5.1——多个旗舰模型扎堆亮相。从整体格局看:海外模型在代码修复和终端自动化上仍占优势,但国产阵营在算法竞赛和性价比上已实现反超。价格方面,国产模型普遍仅为海外旗舰的几分之一到几十分之一,且 DeepSeek V4 Pro、GLM-5.1、Kimi K2.6 均已开源。本文基于代码修复、终端操作、工具协同、IDE编程、算法竞赛五大公开基准交叉验证,结合官方API定价,给你2026年4月最新AI编程模型选型参考。完整数据总表见文末附录。
2026年4月,AI大模型战场密集发布前所未有。OpenAI发布GPT-5.5,DeepSeek推出V4 Pro/Flash双版本,Anthropic更新Claude Opus 4.7,月之暗面开源Kimi K2.6,智谱发布GLM-5.1——多个旗舰模型扎堆亮相。从整体格局看:海外模型在代码修复和终端自动化上仍占优势,但国产阵营在算法竞赛和性价比上已实现反超。价格方面,国产模型普遍仅为海外旗舰的几分之一到几十分之一,且 DeepSeek V4 Pro、GLM-5.1、Kimi K2.6 均已开源。本文基于代码修复、终端操作、工具协同、IDE编程、算法竞赛五大公开基准交叉验证,结合官方API定价,给你2026年4月最新AI编程模型选型参考。完整数据总表见文末附录。
一、分梯队排行
第一梯队:编程旗舰
Claude Opus 4.7 —— 代码修复最可靠
-
优点:代码修复、工具协同、IDE 编程三项第一,出错率仅 36% 全场最低 -
价格:输入 5 美元、输出 25 美元每百万 token -
不足:终端自动化不如 GPT-5.5,新分词器可能增加 token 消耗
GPT-5.5 —— 终端自动化无人能敌
-
优点:终端操作和 DevOps 自动化断崖式领先(82.7%),领先第二名 13 个百分点 -
价格:输入 5 美元、输出 30 美元每百万 token -
不足:幻觉概率高达 86% 旗舰最高,代码修复比 Opus 4.7 低近 6 个百分点
两者维度不同:写代码修 Bug 选 Opus 4.7,跑终端搞自动化选 GPT-5.5。
Claude Opus 4.6 —— 工具协同性价比之选
-
优点:工具协同接近 4.7(仅低约 2 个百分点),token 消耗少 0-35% -
价格:输入 5 美元、输出 25 美元每百万 token(与 4.7 相同) -
不足:代码修复和 IDE 编程弱于 4.7,适合对极致性能要求不高的场景
第二梯队:强力竞争者
GPT-5.4 —— GPT-5.5 的半价平替
-
优点:代码修复与 GPT-5.5 持平甚至微弱领先 -
价格:仅为 GPT-5.5 的一半,输入 2.50 美元、输出 15.00 美元每百万 token -
不足:无 GPT-5.5 的全新 Agent 能力
DeepSeek V4 Pro(国产)—— 算法最强、价格最低
-
优点:算法竞赛和编程解题碾压所有对手,LiveCodeBench 93.5% 全场最高 -
价格:输入约 1.67、输出约 3.33 美元/百万 token(限时 2.5 折至 5/5,折后 ¥3 / ¥6) -
不足:知识推理偏弱,刚发布不久,独立评测仍在积累中
GLM-5.1(国产)—— 开源代码修复冠军
-
优点:开源模型中代码修复最高(SWE-bench Pro 58.4%),发布最早(4/8),数据最充分 -
价格:输入约 0.80、输出约 4.00 美元每百万 token -
不足:上下文窗口仅 20 万 token,对手普遍 100 万以上
Kimi K2.6(国产)—— 黑马,但证据不足
-
优点:综合智能指数开源最高,支持 300 Agent 并行协作,MIT 开源 -
价格:输入约 2.00、输出约 8.00 美元每百万 token -
不足:4/21 刚发布,数据均来自官方自述,尚无独立第三方验证
GLM-5.1 的数据在独立榜单上可查证,已发布两周多,多组评测交叉印证。Kimi K2.6 虽官方数据更亮眼,但”官方说强”和”被验证强”是两回事。
Gemini 3.1 Pro —— 超长上下文、旗舰最低价
-
优点:上下文窗口 200 万 token 全场最长,Google Cloud 生态无缝集成 -
价格:输入 1.25 美元、输出 5.00 美元每百万 token,旗舰级中最便宜 -
不足:代码修复(SWE-bench Pro 54.2%)弱于第一梯队,幻觉率 50%
第三梯队:数据不足(排名为推测)
-
Qwen 3.6 Plus(国产):Code Arena 国内第一,OpenRouter 日调用量登顶。输出约 1.40 美元每百万 token,编程基准数据暂缺。 -
DeepSeek V4 Flash(国产):极致性价比之王,输出仅 0.28 美元每百万 token。详见下方 Flash vs Pro 对比。 -
Grok 4.20:编程非核心定位,输出约 15 美元每百万 token。
以上三个模型目前缺乏可靠的编程基准分数,排名带有猜测成分。
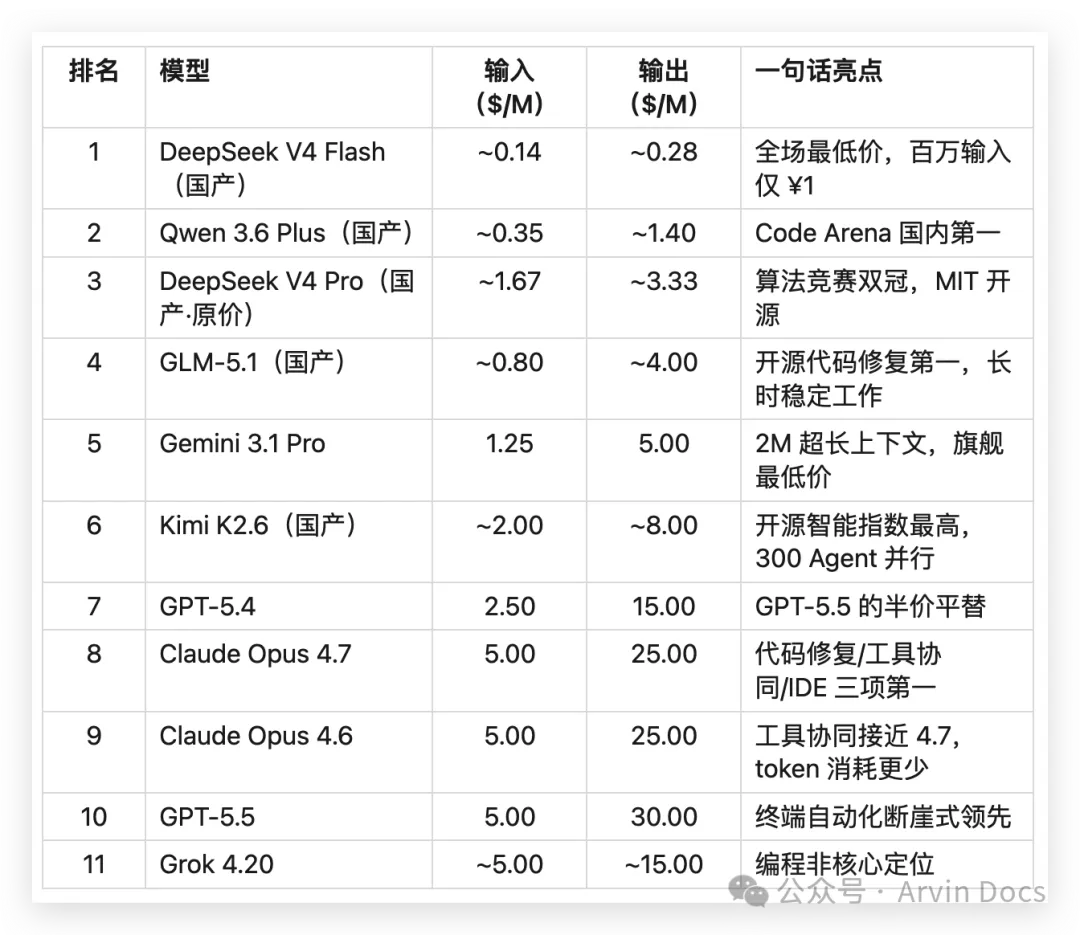
二、费用完整对比(美元/百万token)
成本速算:
-
DeepSeek V4 Flash 花费不到 Opus 4.7 的 2%(约 1/90) -
DeepSeek V4 Pro 折扣价花费不到 Opus 4.7 的 10%(约 1/12) -
Qwen 3.6 Plus 花费不到 GPT-5.5 的 5%(约 1/20)
三、选型指南
写代码、修 Bug:首选 Claude Opus 4.7,备选 GPT-5.5。代码修复、IDE 编程、工具协同三项第一,生成的代码最可靠。
终端操作、Agent 自动化:首选 GPT-5.5,备选 DeepSeek V4 Pro。终端基准断崖式领先,Agent 执行能力最强。
算法竞赛、高性能计算:首选 DeepSeek V4 Pro,备选 Opus 4.7。竞赛编程和算法解题两项全场最高。
预算有限、日常够用:首选 DeepSeek V4 Flash,备选 Qwen 3.6 Plus。花费不到旗舰的 2%,日常编程几乎感知不到差距。
首选 = 该场景下综合表现最佳;备选 = 表现接近但价格更低或调用更方便。 两者不是”强与弱”的关系,而是”最强 vs 最划算”的取舍。
四、DeepSeek V4 Pro 与 V4 Flash 有什么区别?
很多人以为 Flash 是 Pro 的”降精度版本”,其实不是——这是两个完全不同的模型,Flash 是一个独立设计的小模型。
架构差距:Flash 的”大脑”只有 Pro 的四分之一
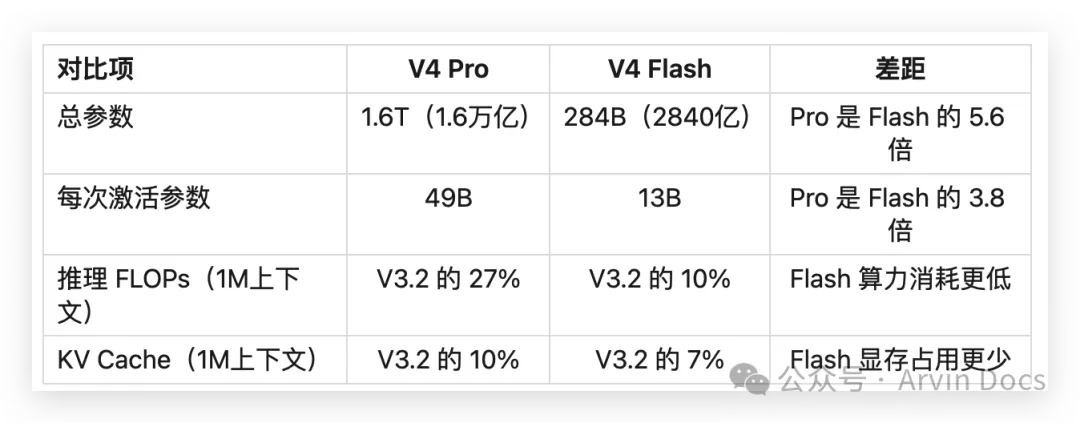
Flash 每处理一个 token 调用的”大脑容量”只有 Pro 的四分之一。它不是”缩水版”,而是一个为效率而生的独立设计。
Flash 为什么便宜到离谱?三重原因
原因一:模型小 = 算力消耗少。 Flash 处理每个 token 的算力约为 Pro 的 1/3 到 1/2,GPU 占用更少,运营成本自然更低。
原因二:MoE 架构天然优势。 两者都是 MoE(混合专家),每次只激活少量”专家”。Flash 的激活比例更低,推理效率更高。
原因三:长上下文架构创新。 V4 系列引入了 CSA(压缩稀疏注意力)+ HCA(高度压缩注意力),Flash 在这套架构上压缩得更激进,进一步降低成本。
实际能力差多少?——日常任务几乎无感
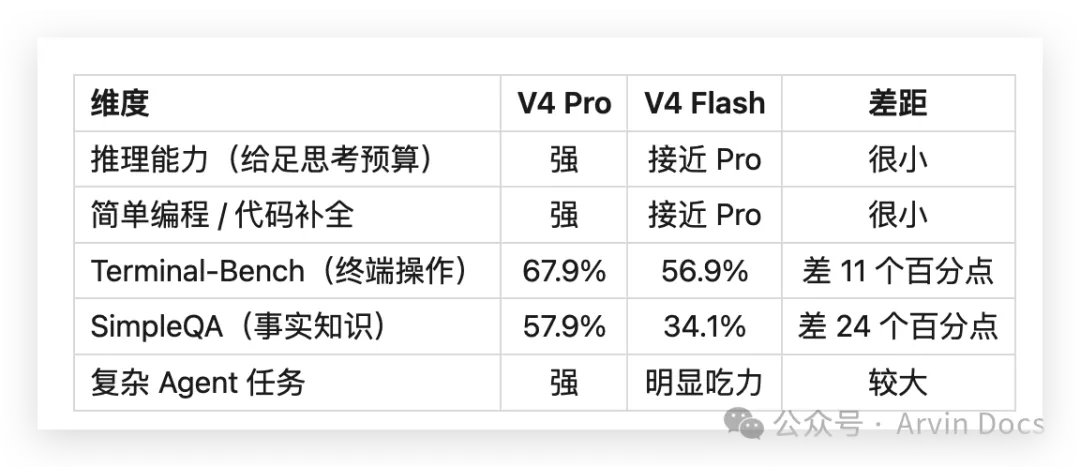
质量差约 2% 左右,价格差 12 倍。绝大多数日常场景——客服问答、文档摘要、代码补全、RAG——根本用不到那 2% 的差距。Flash 在给足思考预算后,推理能力极为接近 Pro。
差距主要在复杂 Agent 和知识密集型任务上:终端操作差了 11 个百分点,事实知识差了 24 个百分点——这是 MoE 在激活参数只有 13B 时的物理限制。
DeepSeek 官方完整定价(/百万token)
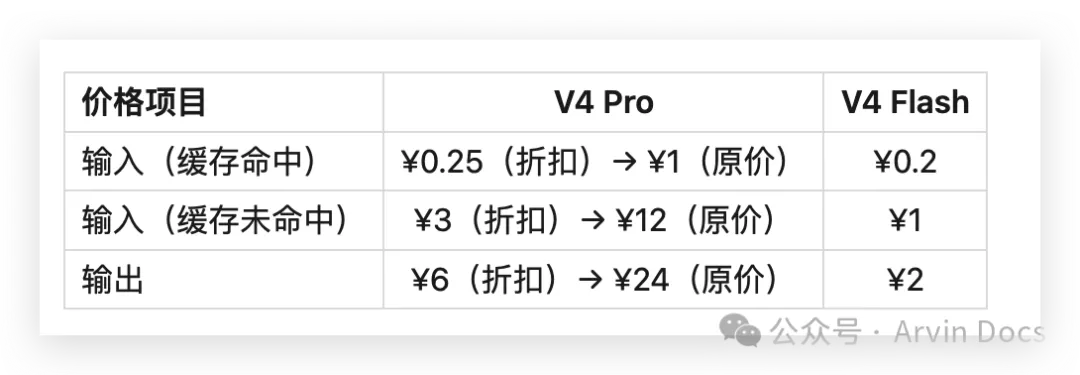
Pro 版限时 2.5 折至 2026年5月5日 23:59。Flash 价格固定,无折扣。
一句话选 Flash 还是 Pro
-
日常写代码、做 RAG、客服对话、结构化输出 → 无脑 Flash(90% 的场景都用不到 Pro 的差距) -
长链 Agent、复杂工具链编排、深度研究型任务 → 上 Pro(折扣价 ¥3/M 输入,比 Flash 高一个档次)
一点感想
这轮 AI 竞赛最令人振奋的信号是:闭源模型不再有绝对优势。DeepSeek V4 Pro、Kimi K2.6、GLM-5.1 这些国产开源模型已经可以正面硬刚最贵的闭源旗舰。而 Opus 4.7 在代码修复和工具编排上的统治力则说明,模型能力的提升远没有触顶。
对于开发者来说,选择权比以往任何时候都多。你不必再为最贵的模型买单,也能获得接近顶级的编程辅助体验。
但也要理性看待:现在的排行榜比想象中脆弱。GPT-5.5、DeepSeek V4 Pro、Kimi K2.6 都才发布几天,独立评测还很少。最佳建议永远是在自己的实际场景中对比测试。
附录:核心编程基准数据总表
以下为各模型在五大公开基准上的原始数据,供深度参考。
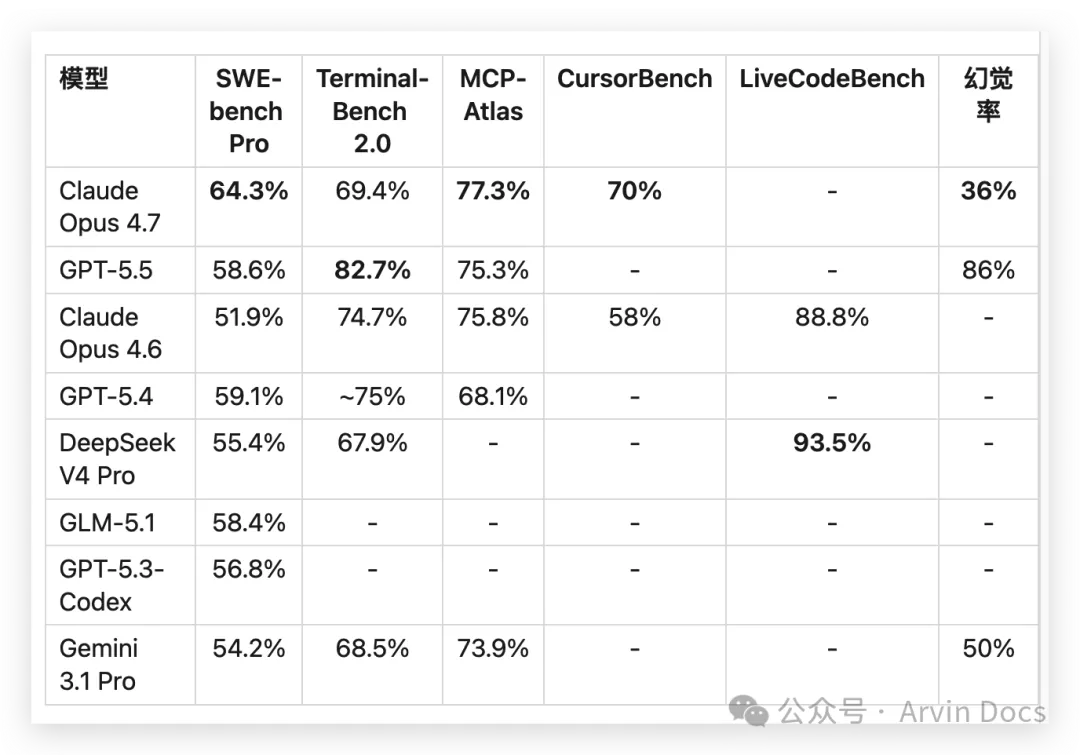
各指标含义:
SWE-bench Pro:在真实GitHub仓库中修复代码bug的能力(权威度最高) Terminal-Bench:在命令行终端中执行DevOps等实际操作的能力 MCP-Atlas:调用多个工具协同完成复杂任务的能力 CursorBench:在Cursor IDE中日常编程的体验表现 LiveCodeBench:算法编程能力(抗数据污染,动态更新题库) 幻觉率:模型生成虚假信息的概率,越低越好 “-” 表示该模型在该基准上无可靠公开数据。GPT-5.5、DeepSeek V4 Pro/Flash、Kimi K2.6 均发布于4月21-24日,独立评测还很少。
数据来源:SWE-bench 官方、Scale AI SEAL 排行榜、marc0.dev 多基准排行、BenchLM.ai、Artificial Analysis、各厂商官方发布页。采集日期 2026-04-27。GPT-5.5、DeepSeek V4 Pro/Flash、Kimi K2.6 发布于 4月21-24日,独立评测不足,排名可能随时调整。
本文来自转载微信公众号“Arvin Docs” ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫