一个从没剪过视频的人,能做出一条有剧情、有台词、有镜头切换的 AI 短视频吗?
能,而且整个流程不超过半天。
这篇文章教你从:想一个故事 → 拆成分镜 → 生成视频 → 剪辑成片。
不需要任何基础,跟着做一遍,你会得到一条完整的 AI 短视频。
很多人做 AI 视频的第一步是打开即梦,对着输入框发呆,不知道该写什么。打出几个字,生成出来的东西跟想象里差很远,然后开始怀疑是不是工具不好用,或者是不是自己不会写提示词。
比如说「我想做一个Biteye 小师妹重生在币圈当大佬」,这是一个想法,不是一个故事。
想法是一个方向,它告诉你大概要做什么。故事是一个结构,它告诉你每一个画面该拍什么。从想法到故事,中间有一段工作要做,这段工作就是脚本策划。
最简单的方式是打开任意的 LLM ,把你脑子里那个模糊的想法直接告诉它,让它帮你把故事撑起来。你不需要自己想清楚所有细节,你只需要提供一个方向,剩下的可以和它一起推导。
故事线确定之后,不要直接拆分镜,先按照叙事节奏把它切成几个大的段落,每个段落明确一件核心的事是什么。这一步是为了控制整体节奏,防止某一段太拖或者太仓促。
即梦单条视频最长 15 秒,实际操作中 12 秒以下是最稳定的,画面出问题的概率最低。1min 秒的成片,按照每个片段平均 10 秒计算,大概需要 5 个片段。
我们把的故事切成五个段落:
段落一:开场,核心任务是交代场景和角色。
段落二:穿越,核心任务是交代时间线。
段落三:展现角色从困惑到清醒的转变。
段落四:计算财富,把情绪推向高潮。
段落五:完成反转,与开场形成闭环。

段落确定之后,把每个段落进一步拆成具体的镜头描述。每个镜头写四个要素:画面主体、所在位置、正在做什么、拍摄角度。不要在分镜里写运动,只描述静止的瞬间。
将段落一的脚本复制到 AI 聊天框中,输入「帮我根据场景一的脚本,生成分镜描述」,得到的效果如下👇
这一章是整个流程里最核心的一章,你在这里生成的图片质量,直接决定最终视频的质量上限。
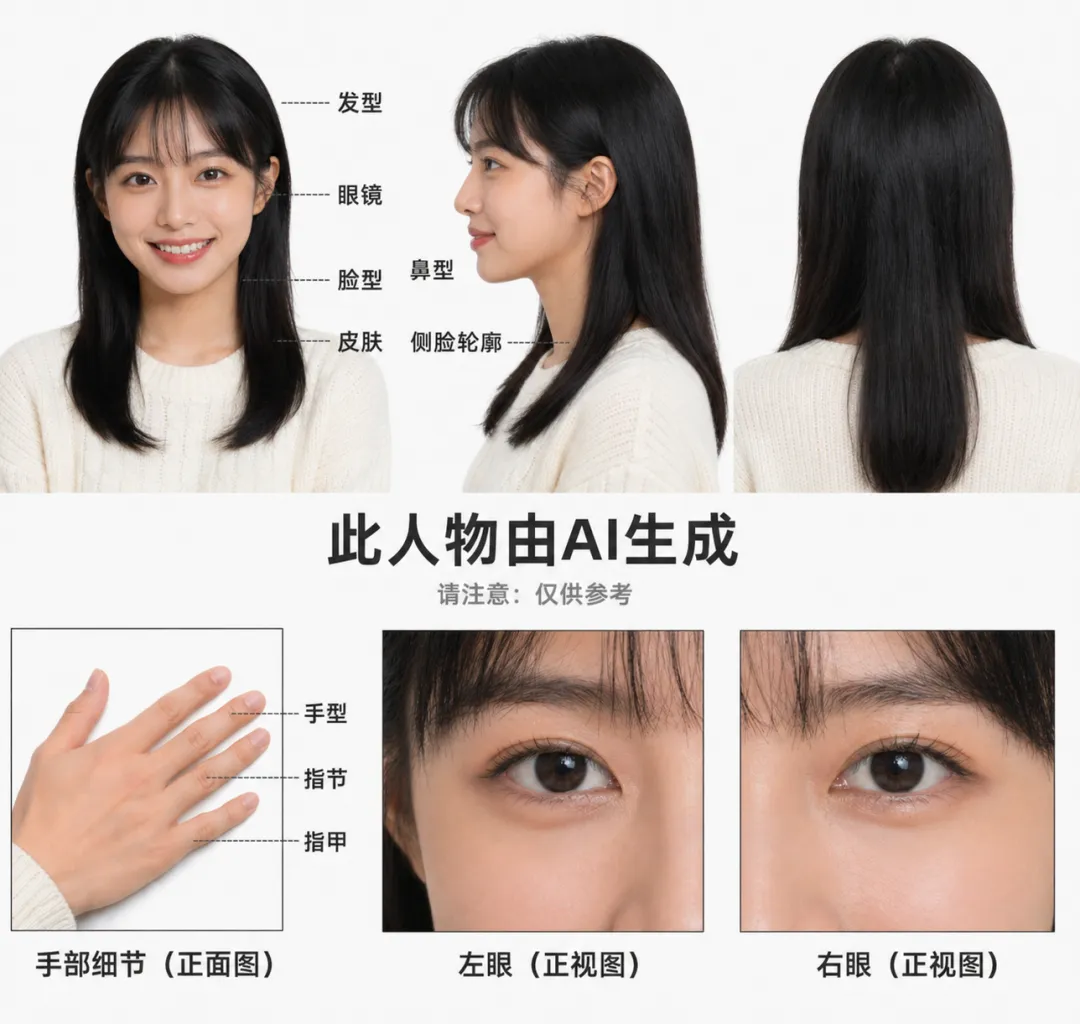
先做三视图,锁定你的主角
在生成任何分镜图之前,第一件事是先把主角的三视图做出来。
三视图就是同一个角色的正面、侧面、背面三张图,目的是把这个人的外形固定下来,后面不管生成什么场景,都参考这三张图来保持角色一致。
跳过这一步直接生成分镜图的话,你会发现每次生成出来的角色都长得不一样,发型变了,脸型变了,这条视频就完全做不下去了。
打开ChatGPT,在对话框里输入:
「帮我生成一张Biteye 小师妹的三视图」
AI会生成一张图,里面有三个角度的同一个人物,如果生成出来的人和你想要的差距大,可以上传参考图。
三视图满意之后,把这张图下载下来,后面每次生成视频都要把它上传回去作为参考。
再做场景参考图,锁定你的背景
角色确定之后,同样的逻辑,把你的场景也先单独生成一张参考图,对话框输入「帮我生成一张办公室的图片」

在正式开始生成分镜图之前,需要先理解一个基础概念:镜头是视频最小的表达单位。
镜头也是会说话的,不同的镜头景别,传递的信息是不一样的,常见的景别有以下几种:
-
全景:交代信息的,观众通过全景知道这个场景在哪里、有哪些角色。
-
中景:推进剧情的,能看清楚动作和表情,是叙事里用得最多的景别。
-
特写:制造情绪的,画面只拍脸、手、或者某个关键道具,放大细节,给观众强烈的情绪冲击。
理解单个镜头之后,还需要再往上走一层:一条视频不是一个镜头,而是多个镜头按照节奏组合在一起的结果。
在实际制作中,我们通常会用「四宫格」和「九宫格」来组织一段视频的镜头结构——也就是在一段视频里,安排 4 个或 9 个镜头完成一次完整表达。
四宫格和九宫格的选择,本质上是对节奏的控制:
-
节奏慢的段落:比如开场交代环境、结尾情绪收口,用四宫格就够,四个镜头有足够的空间让每个画面呼吸。
-
节奏快的段落:比如打斗高潮,镜头需要密集切换来制造紧张感,这时候用九宫格,九个镜头压在一段视频里,剪出来的感觉完全不一样。
理解了镜头和节奏之后,就可以开始进入实际制作:把抽象的故事,变成具体的画面。
人物三视图和场景参考图都准备好之后,接下来要做的,就是把前面写好的分镜描述,一张一张变成可视化的画面。原因很简单,AI 更擅长处理「确定的单帧」,而不是「连续变化的过程」,也能大大降低抽卡率。
具体做法是:
每次生成一个镜头,先把角色三视图和对应的场景参考图上传到 ChatGPT 对话里,然后输入刚刚分镜图的生成提示词。
「帮我根据故事梗概+分镜描述(附上前面与 AI 生成的分镜词)生成一张四宫格分镜图,附上场景图+人物图」
模型会根据你提供的分镜信息,把这段镜头拆成四个画面,并且保证人物和场景的一致性,效果如下:

💡小 Tips,文生图有几个高频坑,提前知道能省很多次数:
-
想生成人物拿手机打游戏的镜头,生成的手机屏幕会自动转向观众。AI 的逻辑是让「内容可读」,打游戏成为图片的污染源。正确做法是:「双手横向持手机,屏幕朝向人物面部,手机背面朝向镜头」。
-
职业名词会让 AI 联想出整套场景:写「护士」,AI 会联想出医院、写「厨师」,AI会联想出厨房。正确做法是:只描述你真正想要的服饰,不提职业名称。
-
文生图只能生成静止画面,「正在转头」没有对应的视觉状态。正确做法是:只描述这一帧存在的东西。

分镜图都准备好了,现在我们要把它们变成会动的视频。
🌟注册即梦
打开浏览器搜索「即梦AI」,进入官网。点击右上角登录,用抖音账号或者手机号注册都可以,国内可以直接访问。
新用户可免费生成一段 15 s 的视频,如果需要开头会员,Biteye小师妹也对比了全网多平台 Seedance 2.0 的价格,详情请看:《全网最低成本订阅 Seedance 2.0 攻略来啦!》。
🌟视频提示词怎么写?
这是这一步里最关键的地方,也是新手最容易写错的地方。
先把参考图都丢进去,即梦支持同时上传多张参考图,直接把图片拖到聊天框里就可以。你在上一章准备好的所有素材,角色三视图、场景参考图、四宫格或者九宫格分镜图,一次性全部拖进去,即梦会综合这些图片的信息来生成视频。
这里很多新手会犯一个错误,就是把画面里有什么重新描述一遍。即梦已经能看到你上传的图了,不需要你再告诉它画面里有什么。
提示词要写的是:画面里什么东西在动,怎么动,镜头自己有没有在运动,以及每一段时间里发生什么。
按照下面这个模板来写,每一行对应视频里的一个时间段:
「帮我参考以上分镜图,生成一段视频。
[起始秒到结束秒],[景别],[运镜方式],[角色或主体]+[具体动作],音效:[声音描述]。」
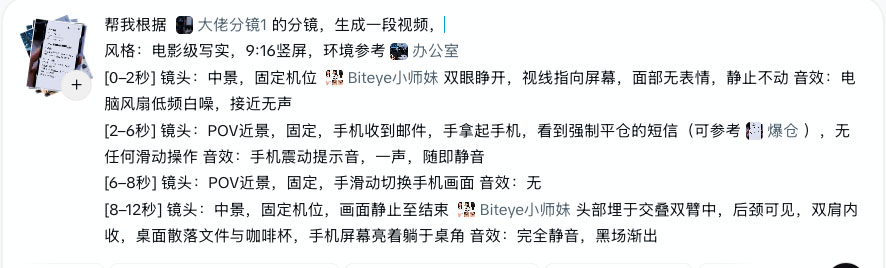
🌟声音描述是新手最容易忽略的部分,如果视频里有台词,光写「说话声」是不够的,模型会随机生成一个声音作为参考。要保证多段视频里角色声音一致,有两个方法:
1️⃣用第一段的音频做参考
先生成第一段视频,对生成结果满意之后,把这段视频的音频单独导出。后续每一段生成时,把这段音频作为声音参考上传,即梦会参考这个音色来生成后续片段的人声,保证声音一致性。
2️⃣用 Fish Audio 找参考音色
打开 Fish Audio,搜索符合角色气质的声音,试听之后下载一段作为参考音频。生成每一段视频时统一使用这个参考音频,全片声音保持一致。
🌟用标点控制 AI 配音的语气
给 AI 配音模型写台词,不是把文字打进去就完了。同样一句话,标点不同,发出来的语气可以完全不一样。
核心逻辑是:标点符号控制停顿,停顿决定情绪。
…… 省略号让声音断开但气息不断,适合思考、犹豫、话未说完的状态。
……! 组合使用,是压抑之后的突然爆发。
() 括号内的内容音量自动降低,变成气声,适合内心独白和自言自语。
*内容* 星号包围的词会变得更低、更慢、更重,用来强调关键信息。
[] 方括号里写指令而不是台词,比如 [深吸一口气]、[停顿1秒],模型会执行动作而不是念出来。
💡小 Tips:
-
AI 没有方位意识,经常分不清左右,需要另外做「位置关系参考图」告诉AI 人物是怎么运动的,如下图一。还有简单的方法:用箭头来描述人物的运动轨迹,并在最后添加上「把箭头删除」。
-
写慢不写快。模型处理缓慢动作比快速动作稳定得多。需要快节奏的片段,优先用剪辑速度来实现,而不是让模型生成快动作。
-
每段视频都要上传参考图,不要只上传一次。模型没有跨段记忆,不上传参考图的那一段,角色外貌会偏移。

剪辑和后期是整个流程里画龙点睛的一步,前面生成的每一段素材都是独立的,色调可能有差异,节奏可能不连贯,声音也是分散的,剪辑的作用就是把这些碎片捏合成一个完整的故事。
视频加上音乐后,更能带动观众的情绪、加上字幕,台词更清晰了,同样的素材,剪得好和剪得差,最终呈现可以差一个量级。
做法分四步:排列素材 → 统一色调 → 加声音 → 加字幕,最后导出。
第一步:排列素材
打开剪映,把所有片段按场景顺序拖入时间轴。先不管色调和声音,把顺序确认好,整体看一遍节奏有没有问题,太长的片段在这一步剪掉多余的部分。
第二步:统一色调
不同时间生成的片段,色温和亮度可能有细微差异,放在一起会显得割裂。处理方法:全选所有片段,在「调节」里整体加一层滤镜,场景一用冷蓝色调,场景二之后切换暖黄,保持每个场景内部色调一致就够了。
第三步:加背景音乐和音效
对白声音在生成视频时已经处理好了,这一步主要补两类声音:背景音乐和环境音效。
背景音乐决定整体情绪基调,音量压到对白的 30% 以下,不要盖过人声。
第四步:加字幕
用剪映的「智能字幕」自动识别对白,识别完之后检查一遍错别字,统一字体和位置。旁白或自言自语的台词,建议和正常对白用不同样式区分,比如斜体或不同颜色。
在上一篇文章《GPT Image 2.0 加持 Seedance 2.0:人人可拍好莱坞大片》我们认为在 AI 时代:「拍视频」的门槛被降低了,以后人人都能排除好莱坞大片。
但门槛低,不代表你就能做出来。
工具都是公开的,教程也到处都有,但大多数人卡在同一个地方:从来没有完整跑通过一遍。
本篇文章 Biteye 已经带你从一个模糊的想法,一步步剪成一条完整的成片。
过去,这个过程需要一整套专业分工: 编剧、分镜、美术、摄影、剪辑,每一个环节都是一道门槛。
而现在,这些环节没有消失,只是被压缩进了一条流程里。
这意味着一件更底层的变化:视频不再是「生产能力」的产物,而开始变成「表达能力」的产物。
本文来自转载Biteye中文 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫