前沿的 Coding 能力、1M 的上下文窗口,还有原生的多模态

就在今天,MiniMax 发布了新一代模型 M3。

这次最值得看的地方,是 M3 终于在同一个模型里凑齐了三种能力:
前沿的 Coding 能力、1M 的上下文窗口,还有原生的多模态。
同一时间,MiniMax 还更新了配套的 Agent 产品 MiniMax Code,并放出了 M3 的技术博客。
🚥
我们第一时间看完了技术博客,也分别上手实测了 M3 和 MiniMax Code。
接下来,分享对这份技术博客的内容整理和两个实测案例。
先看这份技术博客
读完之后,一个比较直接的感受是:
M3 真正的看点,是一个国产模型同时具备了多种前沿能力。
从相关 Benchmark,比如 Terminal Bench 来看,M3 的表现已经稳定排在 Sonnet 4.6 这一档,部分编程和 Agent 任务上还要更靠前一些。但和 Opus 4.7、GPT-5.5 放在一起比,能看出还有一段差距。
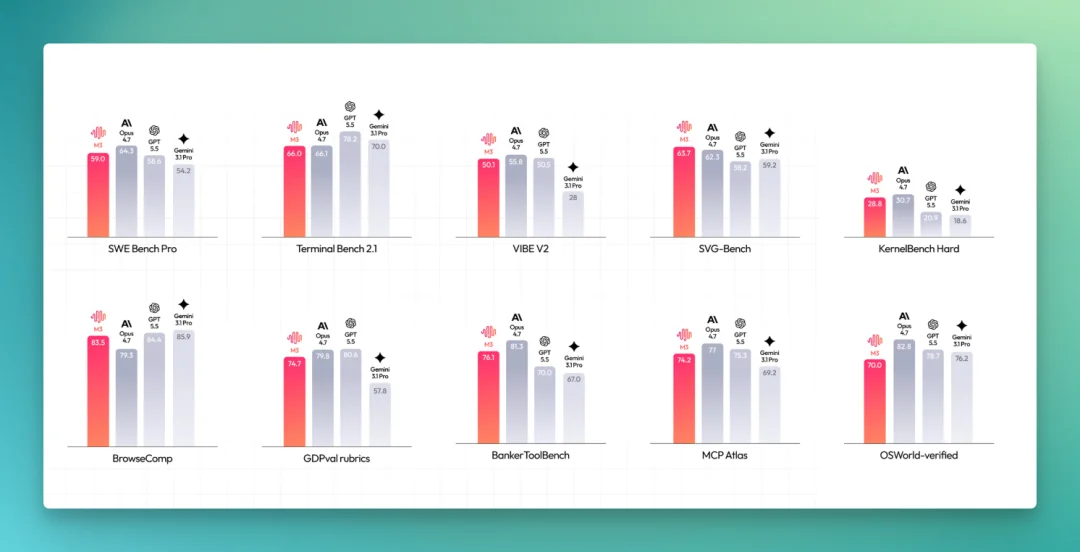
整体来说,这份技术博客给出的是 MiniMax M3 的一份扎实的成绩单,但还算不上是终点。
下面分三块来看。
1M 上下文背后的 MSA
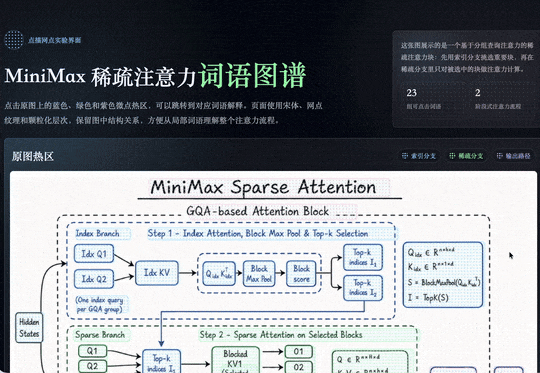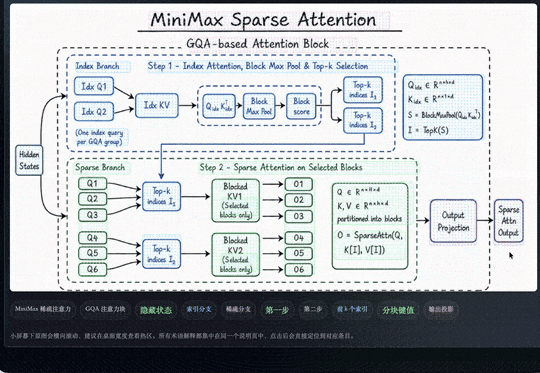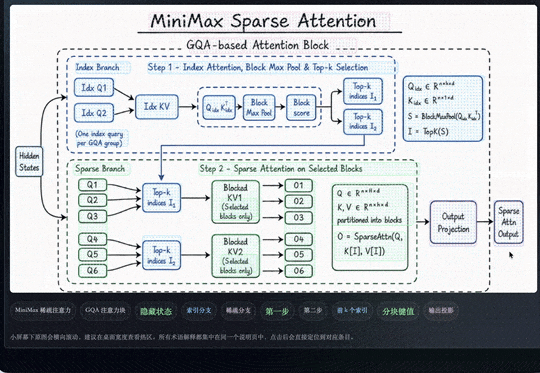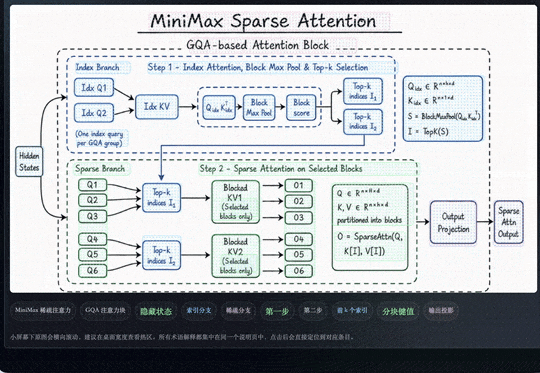
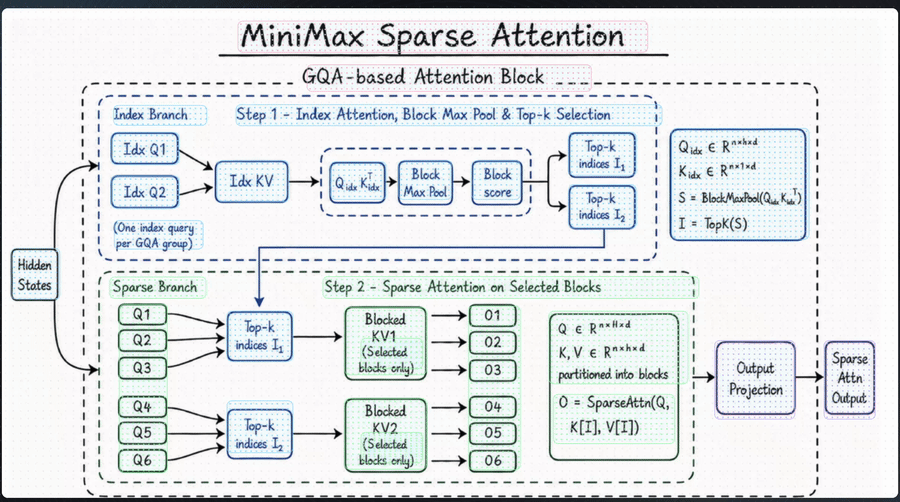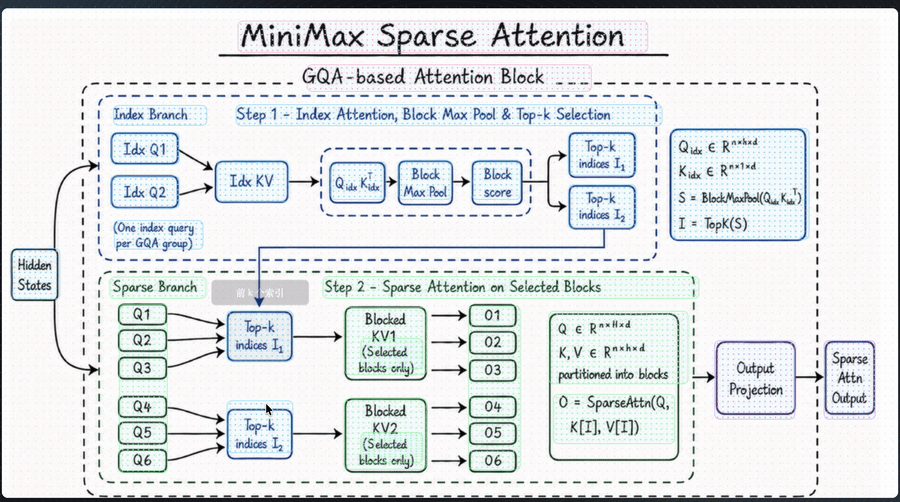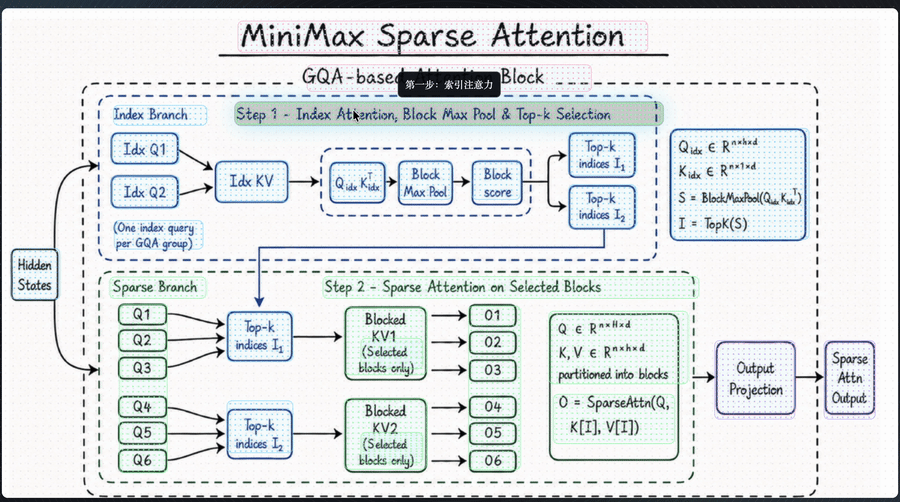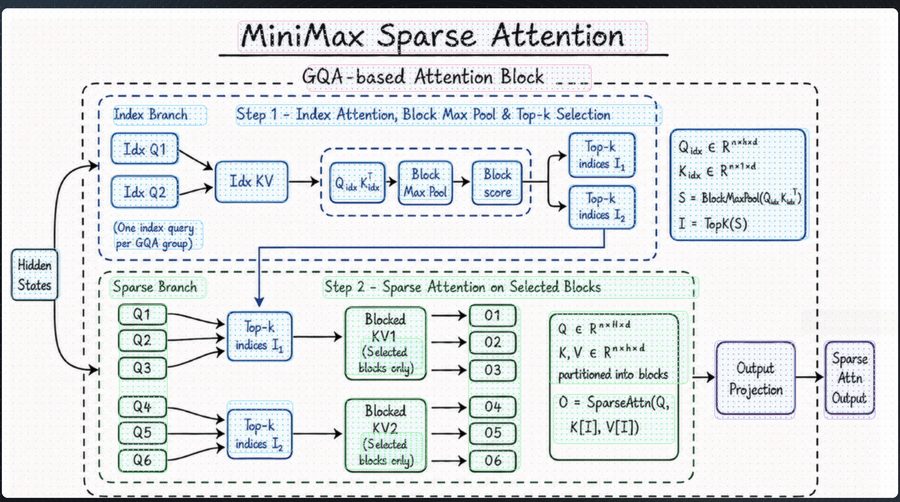
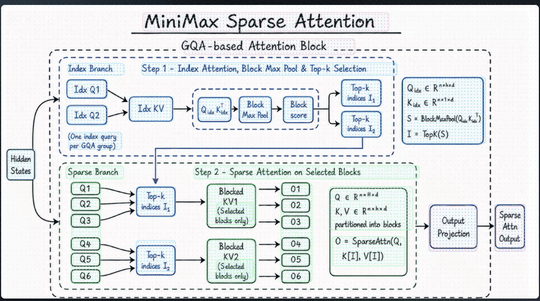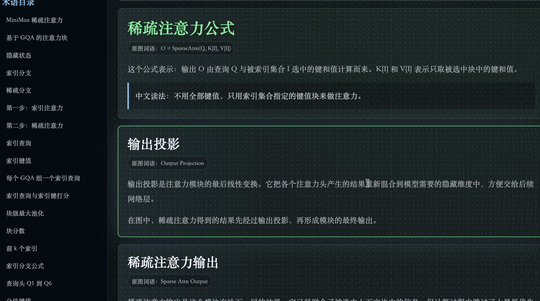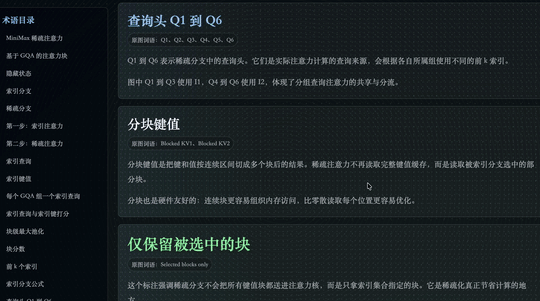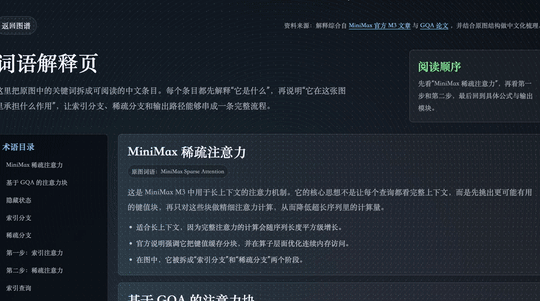
M3 这次支持 1M 上下文,背后换掉的是模型最底层的注意力模块,MiniMax 把它叫做 MSA(MiniMax Sparse Attention)。
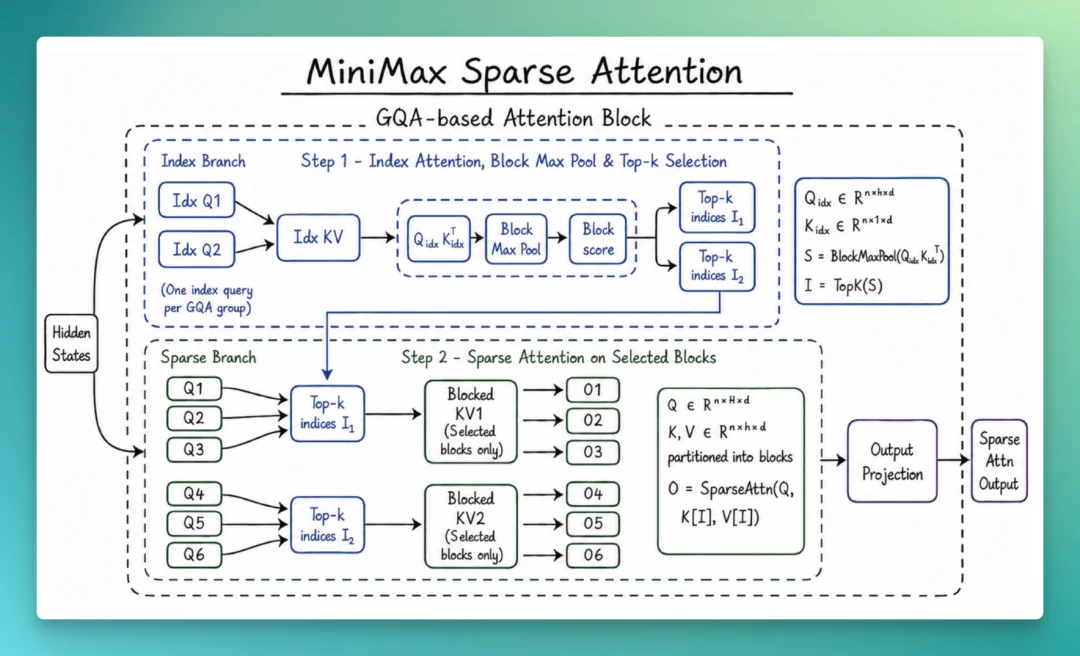
传统的全注意力机制里,每个 token 都要和前面所有 token 做一次关联计算。序列一旦变长,计算量就会以平方级别增长,很快超出硬件能够承受的范围。这也是长上下文长期难以实现的根本原因。
稀疏注意力的思路,是在正式计算前先做一道初筛,只保留真正相关的部分参与运算,从而避开平方级的复杂度爆炸。
这条路线并不新鲜:DeepSeek 在 V3.2 上采用的 DSA、月之暗面在 Kimi 上采用的 MoBA,都属于稀疏注意力,MSA 对标的也正是这一类方案。
MSA 这次比较独特的思路,集中在 2 个地方。
一是对 KV 的分块更精细,相同算力下能覆盖到的有效上下文更多;二是在算子层直接做了优化,让每一块数据只读一次、访存连续,按官方给的数据,比开源的 Flash-Sparse-Attention、flash-moba 要快 4 倍以上。
这些工程细节带来的结果还算是比较明显的:
在 100 万上下文长度下,M3 每个 token 的计算量只有上一代的 1/20,prefilling 阶段加速超过 9 倍,decoding 阶段超过 15 倍。
而在多组对照实验里,MSA 的大部分能力都与全注意力基本持平。
换句话说,长上下文不再是一个理论上可行、实际却用不起的功能。
因此,1M 现在可以理解为「更像是一项基础设施」。后面所有的长程 Agent、长程 Coding、长视频理解,都要建立在其基础之上。
Coding 提升很多
Coding 和 Agent 是 M3 这次重点提升的方向。
技术博客里有一组评测数字:SWE-Bench Pro 上 59.0%,Terminal Bench 2.1 上 66.0%,MCP Atlas 上 74.2%,还有 SWE-fficiency、KernelBench Hard 等几项。
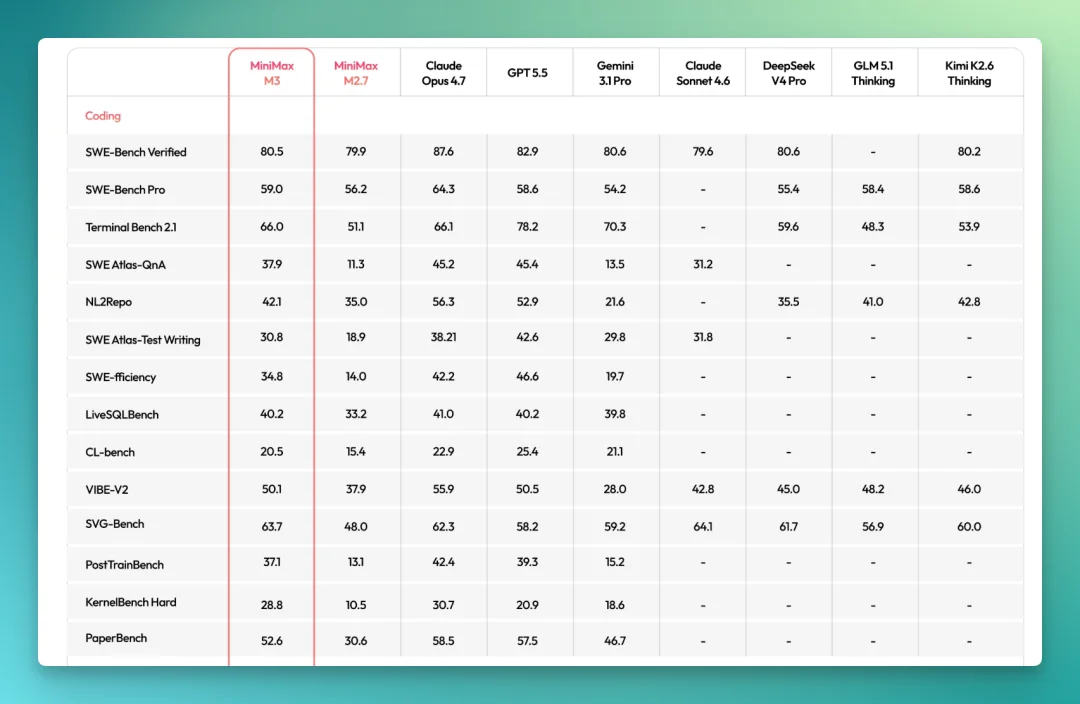
不过,比分数更有意思的是它怎么训练的。
MiniMax 在博客里明确提出了一个现在很多代码 Agent 的共性问题:训练和评测大多建立在「单轮任务」的假设上,给一个需求,生成一段代码,结束 Over。
可真实的开发与这套流程还是相当大的区别的。
我们进行开发的时候,往往是在同一个 Session 里反复来回:先说个大概,再补充需求,中途改下方案,根据中间结果再派新的任务。
为了让模型在训练阶段就见到这种场景,MiniMax 做了一个交互式的用户模拟器,去模拟开发者澄清需求、讨论方案、修正反馈、连续切换任务的过程。
整体来看,这一点其实很复杂下一代 Coding Agent 的思路:比起单纯地写代码,长期协作、规划,以及人和 Agent 配合的效率的需求,可能才是更重要的。
这个判断,从过往的社区评价来看,大家是基本认同的,一个能力强、但不会跟你来回对齐的模型,用起来真的会很累。
原生多模态
从技术博客来看,M3 是从训练的第 0 步开始就做多模态混合训练的,这种做法的好处,是文本和图像的语义空间能更自然地对齐。
博客里还提到了一个细节:他们发现 Interleaved data(图文交错排列的数据)对模型能力的帮助,比一般认为的更关键。为了把这类数据的规模提升上去,MiniMax 重做了整套数据管线,把预训练数据的整体规模扩大到 100T 量级。
以上三种能力,共同构成了这次 MiniMax M3 模型的基础。
技术博客里同步给到了几个内部案例,其中两个比较典型,值得说一下。
一个是论文复现。
他们把一篇 ICLR 2025 的获奖论文交给 M3,让它独立复现。M3 自主运行了接近 12 小时,中间产出了 18 次 commit 和 23 张实验图表,完整复现了核心实验。
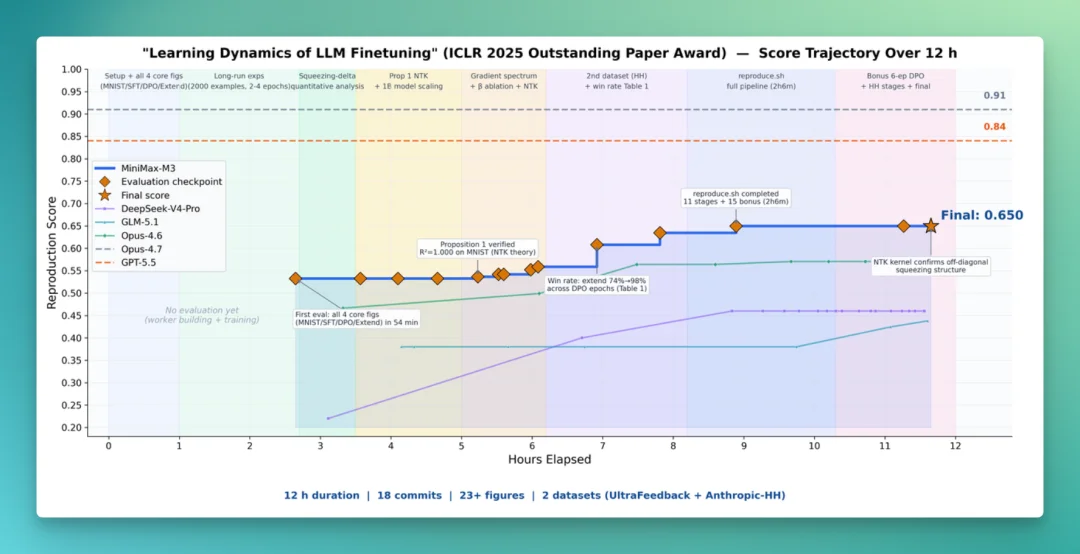
这个过程里,看懂论文里的曲线和公式需要多模态,论文加代码加实验日志能一次性进窗口要长上下文,而把整条流程连续做完要靠 Coding 和 Agent 的能力。三种能力的集合,才能让这个任务顺利完成。
另一个是 CUDA 算子优化。
任务是在 NVIDIA Hopper 架构上优化一个 FP8 矩阵乘的 kernel,这种任务,对于有一定工程经验的团队通常要花一到两周时间。
而 MiniMax 团队给 M3 的起点只有一份任务描述、一个评估脚本和一段骨架代码,没有任何现成的高性能实现可以参考。
在大约 24 小时里,M3 提交了 147 次 benchmark、调用了 1959 次工具,把硬件峰值利用率从首版的 7.6% 提升到 71.3%。
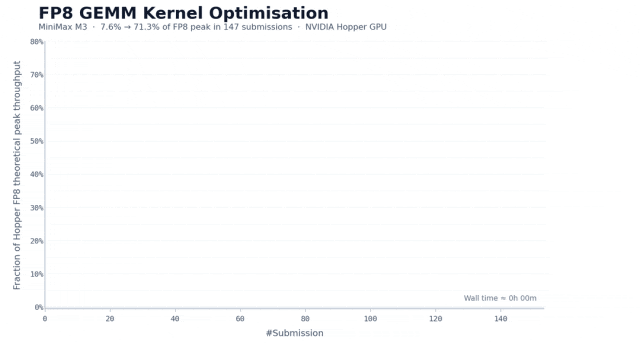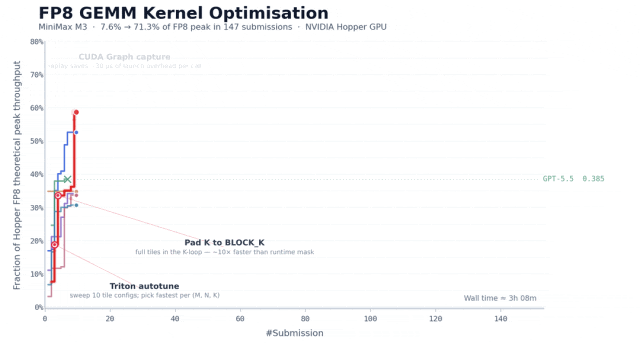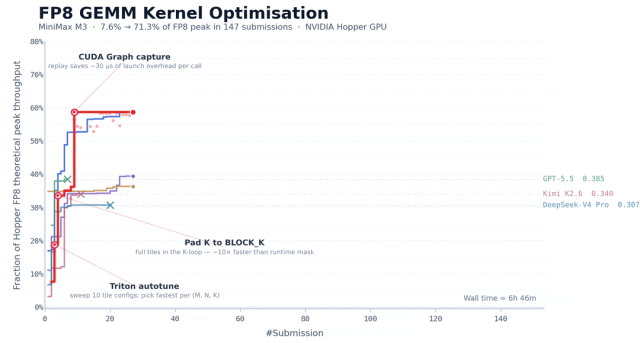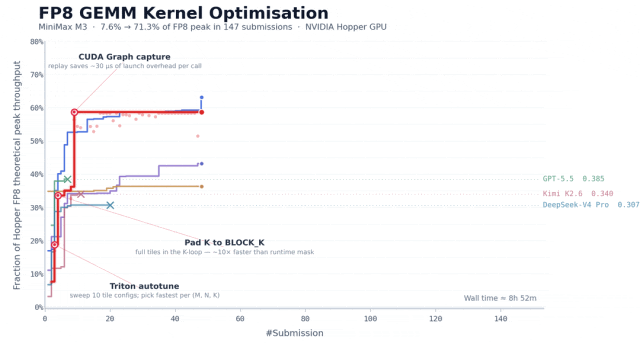
它的执行过程也很有意思,博客里提到,除了 Opus 4.7 和 M3,其余模型大多在前 30 次提交里就停住、主动退出了,而 M3 的最优解出现在第 145 次提交,在那之前它经历了好几个分数不再上涨的平台期,但还在换方向继续尝试。
这种「卡住了也不轻易放弃」的耐心,算是 M3 此次的表现亮点。
我们的实测:M3
我们也做了一番实测。目前 M3 模型已经可以在 MiniMax 开放平台的 API 里调用。
平时我一般用 CC Switch 来给 Claude Code 或 Codex 设置模型,比较方便,现在也能直接找到 M3 了。
经过多次实测后,我们发现它在长程任务上表现还不错,尤其是复刻类任务。比如先复刻一个网页的整体风格,再在此基础上给它一段很长的内容,让它做成展示页面,最终在前端的美感上,相比之前的模型有一定提升。
比如,因为它是原生多模态模型,我给了它几张图片,让它帮我做一个 MiniMax M3 MSA 的内容索引互动网页。
这次 MiniMax M3 有一个比较明显的特点,就是具备了原生多模态能力。它可以直接理解图片里的内容,而且识别速度很快。对于图片中的元素、数据和结构信息,都能快速完成分析和定位,同时结合上下文理解它们之间的关系。
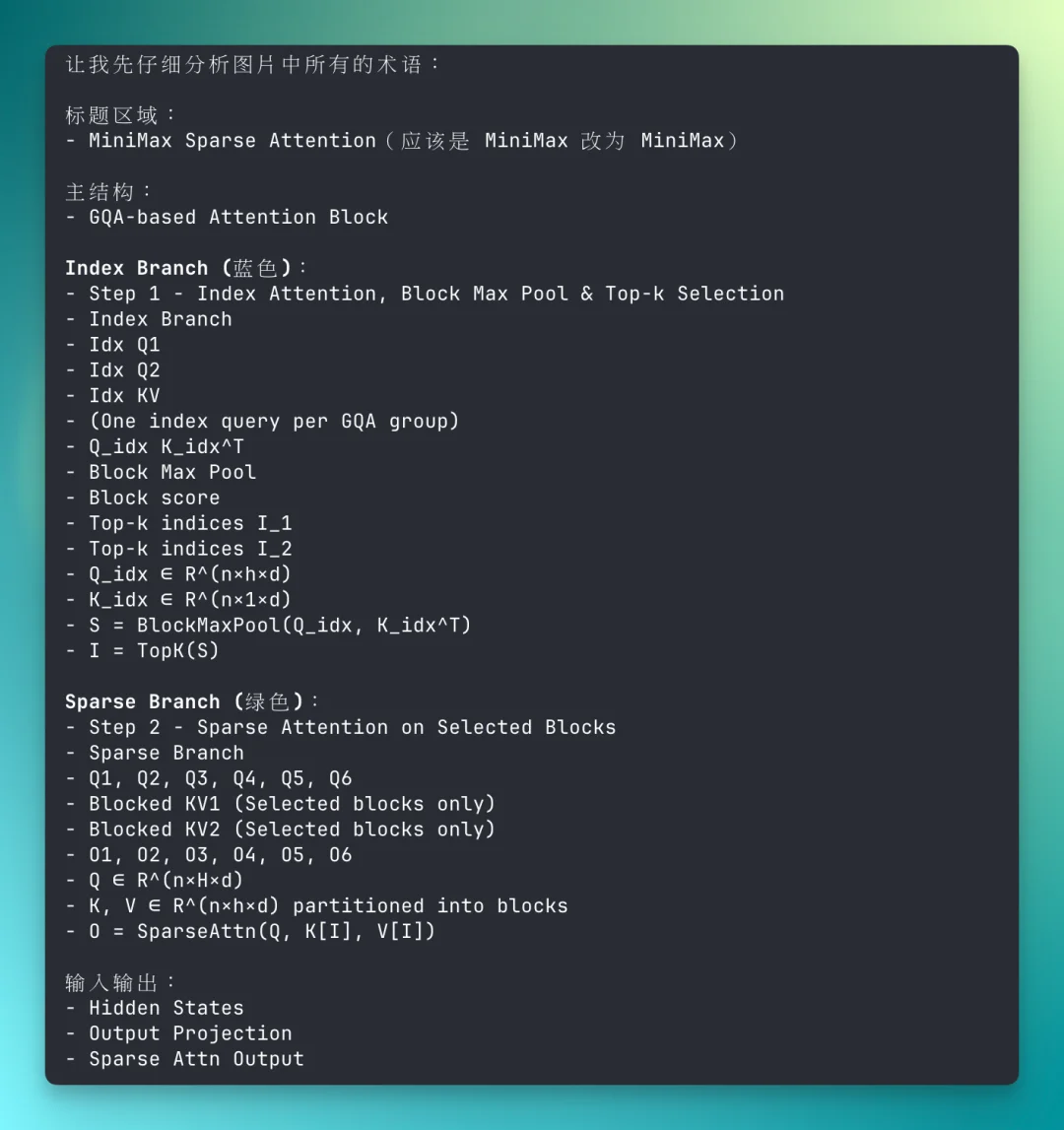
现在的 M3 在执行任务时,会有一个完整的工作流。它会自主地进行验证,检查自己的输出。会和用户的提示对齐。比如,当提示不完整时,它会先进行脑力风暴,补充和完善思路,然后再执行。
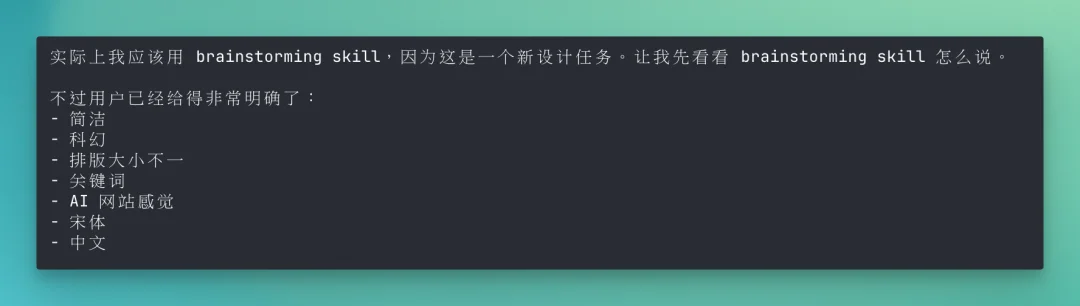
即便完成了第一轮术语识别,仍然可能会有一些遗漏。它会先把整体框架搭建出来,然后再重新梳理一遍图片里的所有可点击关键词,检查是否有遗漏或分类不合理的地方,最后再统一完成整体设计。
整个工作流衔接非常完整。通过多步验证,它会不断与我的提示词对齐。每一步都会检查前一步的结果。生成多个页面或配置时,会并行调用多个子 Agent 执行。整个流程下来,几乎不需要人工干预。
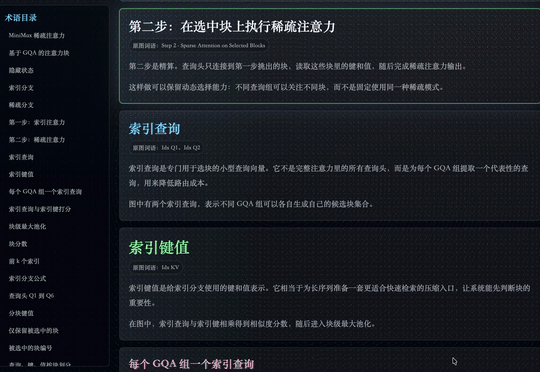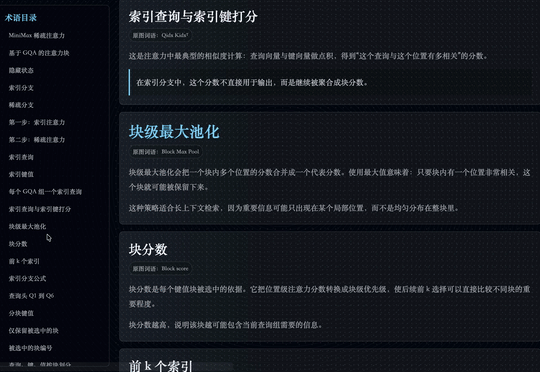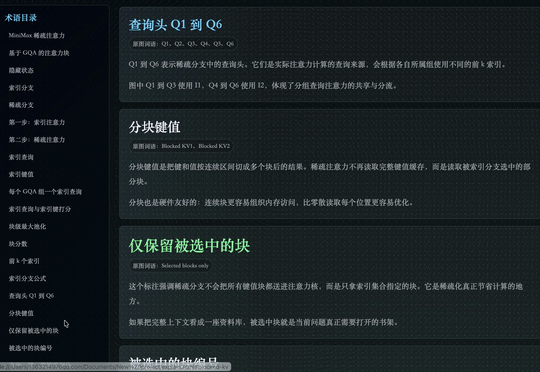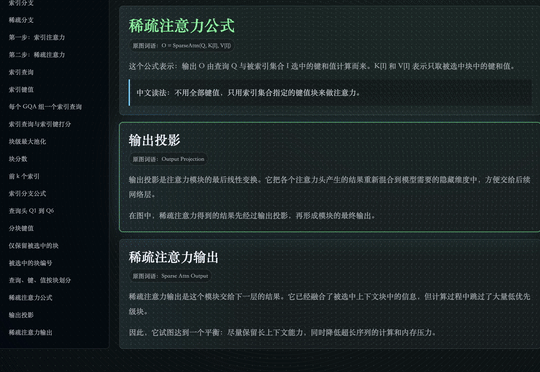
这个网站的内容就是先截一张 MSA 的截图。然后结合 Claude Code Harness 里已有的 skill 去处理。它识别图片里的每一个点,把每个点做成可互动、可点击的块。点开块,就能看到对应的术语。每个术语里有详细解释,这需要 M3 的长上下文和调研能力,也需要前端的多模态能力。
最后做出来的效果是,整张图片里的内容都会被自动识别,并圈选成可交互的模块。点击任意模块,都可以直接进入对应的下一层页面。
能看出来它做的比较细。每一个词和标签框都被标了出来。比如右上角这一部分,它不会把里边每个字单独拆开,而是会把它们识别成同一个专业术语或同一个概念,然后作为一个整体进行框选。
而且它不只是按照视觉上能看到的内容去划分。比如一个蓝色方框里的内容,在人眼看来可能就是一个模块,但它还会进一步理解里面具体写了什么。
像有些区域,它会识别出这是一个注意力机制相关的公式;有些区域,则会识别出是 MSA 这类专业术语。也就是说,它不只是看版式和颜色,而是在结合内容本身做进一步分析。
当然,如果只靠模型自身的视觉能力,效果还是有限。实际过程中更重要的还是 Harness 和 Skill 的配合。它们可以帮助模型进行多轮识别、反复校验和补充判断,让最终识别出来的结构更完整,也更准确。
最后做出来的效果是你点击任意一个专业术语,都会跳转到统一的术语目录库里。
整个目录库本质上是一个知识地图。里面的每个模块都由专业术语、关键词,以及对应的解释和调研注释组成。
这样不管是从图片里的哪个位置点进去,最后都会汇总到同一套知识体系里。既能按视觉区域浏览,也能按术语和概念进行检索。
然后在这套术语库里面,还集成了一个专门的术语目录。甚至相关的公式也会直接列出来:

这个目录支持多层级点选。每点开一个目录节点,下面还会继续展开对应的子分类和关联内容。
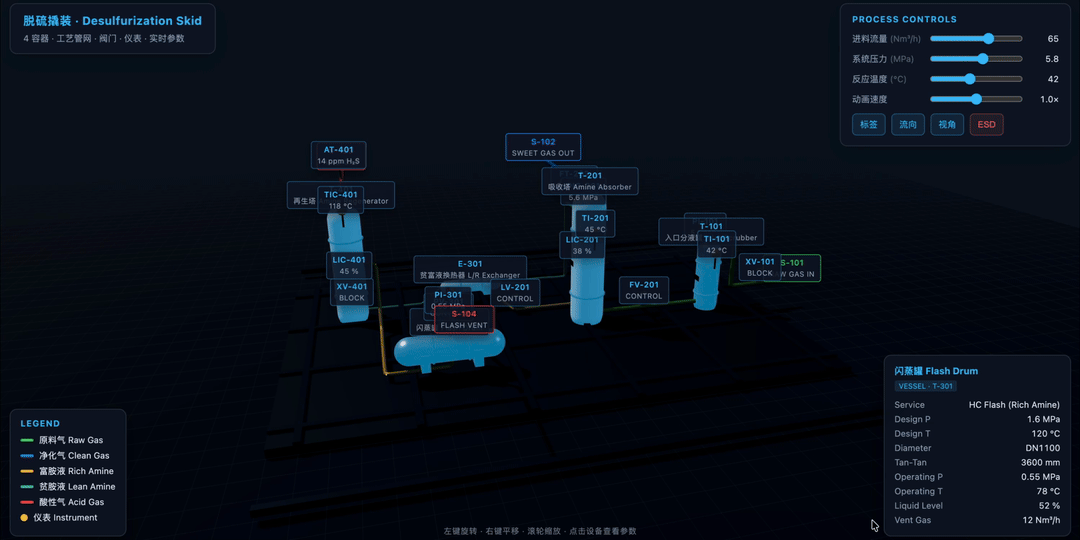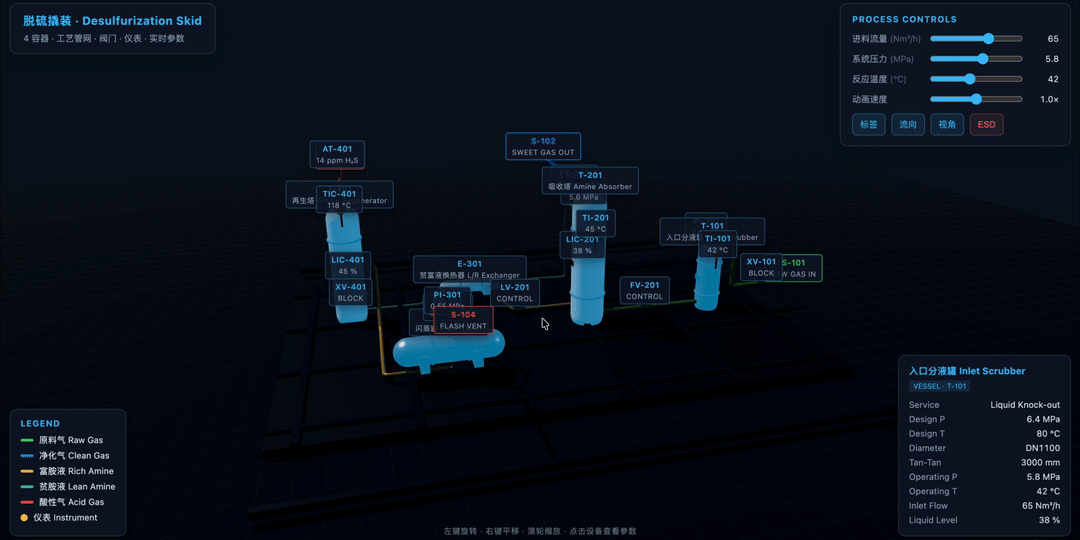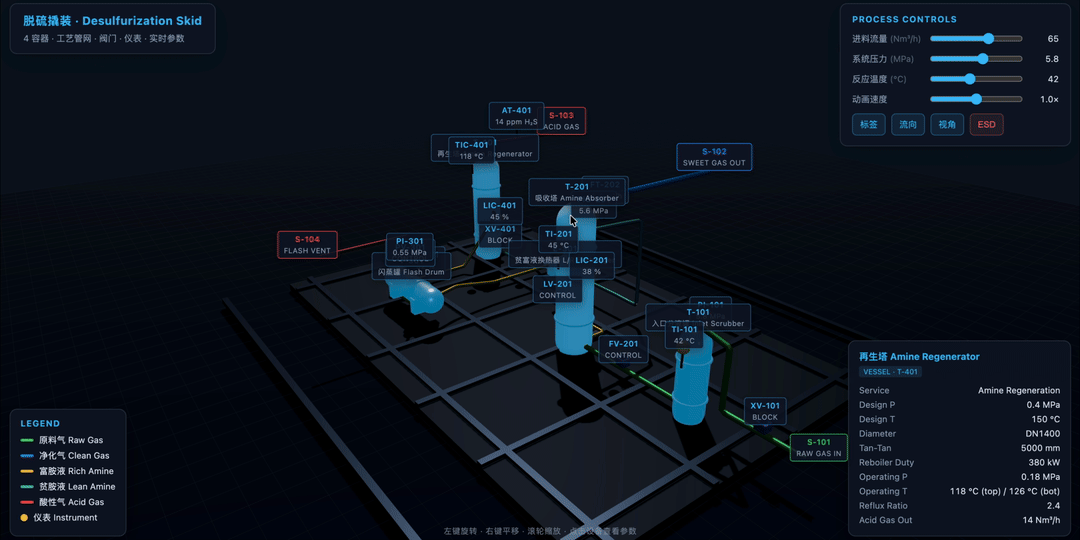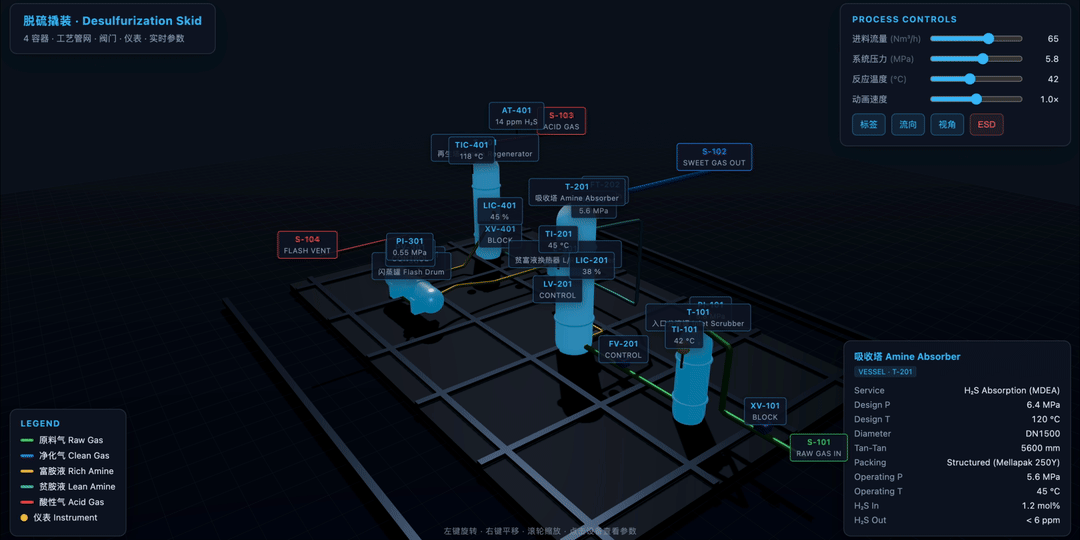
M3 也可以处理一些更立体的任务,这里其实可以和 Opus 4.7 对比一下。
比如用 Three.js 创建一个 3D 脱硫滑橇工艺流程图。里面包括水平和垂直的圆柱形容器、彩色管道网络、阀门、仪表、摄像机控制,以及设备标签和参数标注。
下面这个是 Opus 4.7 第一次做的:
整体是比较完整的,右上角还有一个滑动模块,可以实时控制画面的物理效果。
下面这个案例的效果是 M3 做的,整体的 3D 感还不错,可以通过几个关键模块,实时切换不同画面。切换过程中,整个数字孪生的效果比较完整。如果仔细看的话,会发现里面的大量容器是有光泽效果的:

和 M3 一起更新的 MiniMax Code
跟着 M3 一起更新的,还有 MiniMax Code。
它对标的是 Claude Code、Codex 这一类的 Agent 产品,思路上的关键差别在于:它是专门为 M3 设计、并且和 M3 一起训练出来的。
模型和配套的 Agent 一起训练,理论上能更好地发挥 M3 在长上下文、Coding 和原生多模态上的能力。
它最核心的一个能力叫做: Agent Team。
简单说,遇到一个大任务,它会先拆成多个阶段、可以并发、还能动态调整的 Workflow,再交给一组 Agent 协作推进。中间用 Producer 加 Verifier 的循环,一边产出一边自我检查、修正,必要时可以连续自主跑上好几天。
这里可以拉一个对照。
Claude Code 近期也发布了方向类似的 Dynamic Workflows。两者的侧重不太一样:Claude Code 更强调用 JS 代码做固定式的编排,MiniMax Code 更强调执行过程里的持续反思和纠错,会根据任务进展实时调方案、调优先级,用户也能随时插进来加需求或改方向。
哪种更好,现在下结论还太早,要看各自在真实项目里实际运行下来的稳定性。
另外,得益于 M3 的原生多模态,MiniMax Code 还自带了 Computer Use 的能力。
还有一点值得提一下:MiniMax Code 的 Harness 是基于 OpenCode 和 Pi Agent 这两个开源项目搭建的,官方也说了后续打算把这个项目开源。这和 M3 本身开源的态度是一致的。
同样,我们也用一个案例实测了一下。
我们的实测:MiniMax Code
按照官方口径,MiniMax Code 专门针对 M3 做了适配,更适合多 Agent 调用,整体运行也更适合长程、偏复杂的任务。
举个例子,我之前看到一张图片,是英伟达 GTC 大会的展位图,里面有大量展位和比较细小的文字,正好可以和 M3 的原生多模态能力结合起来用。

我可以直接把这张图片发给 MiniMax Code,在里面调用 M3 模型,让它分析图中所有厂商,再根据各家的业务以及在上游、中游、下游的位置做整体分析,最后做成一个网页来展示。
具体做法是,直接在 MiniMax Code 里上传这张展会地图,让它整理成一份 AI 基础设施的展会情报报告。
在这类复杂任务里,它执行了大量工作流,识别出图中相当多的厂商,并按照 AI 产业链的业态定位给出对应的展位号和公司名。当然,作为原生多模态模型,识别这种展位时还是会出现一些误差,所以它会再做一遍 review,并给出置信度。

最终给出的这份交互式展会地图情报报告比较完整,所有厂商都按上下游做了标注,原图也作为一张可放大的地图单独放进了报告里。
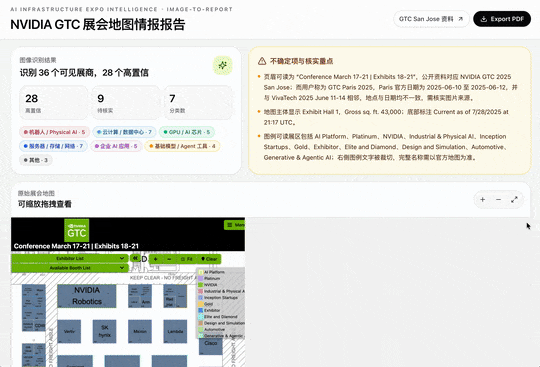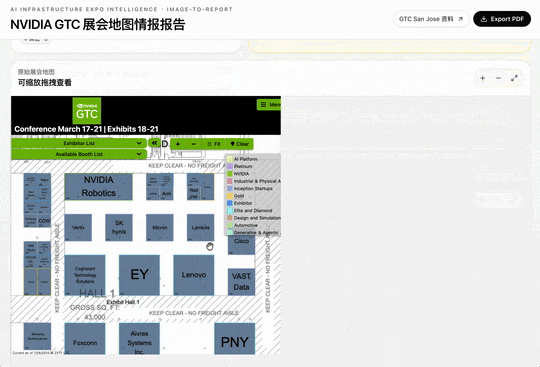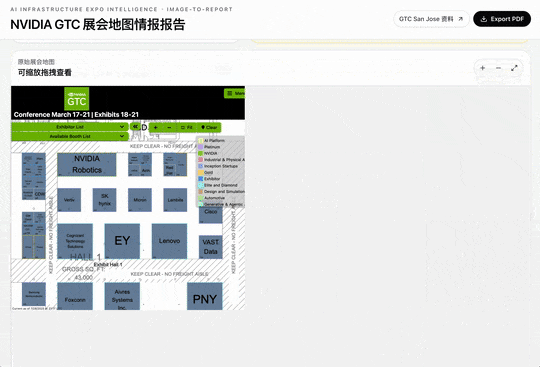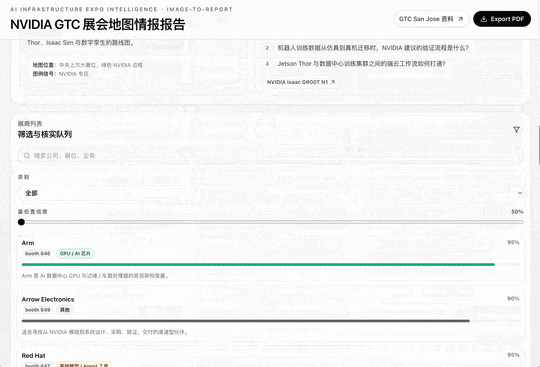
它还会按照置信度来匹配公司。比如在某个置信度之上,有 36 家公司被匹配出来,像英伟达的 Robotics、Vertiv 等关键词都被标注了出来。置信度的高低,取决于 M3 模型对这张图片中相应内容的识别情况。
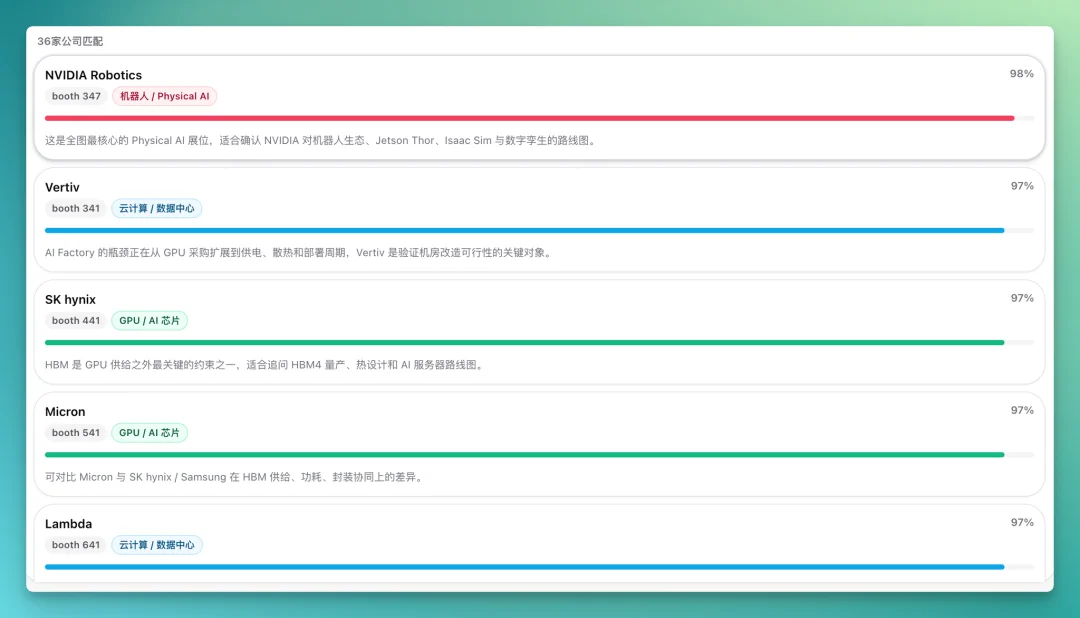
所有可识别到的公司,都会按照公司名称、Booth、分类、在产业中的位置、置信度以及 Verification 来组织。Verification 分为可直接采用、可作初步线索、待核实等几类。

整个产业地图则按照上游基础设施、中游平台、下游应用,给出了一个简要的概览:

Token Plan
最后说说定价,涉及到钱相关的,不能不看。我们大致整理了下,这次 MiniMax 同步更新了 Token Plan,一共有三档:
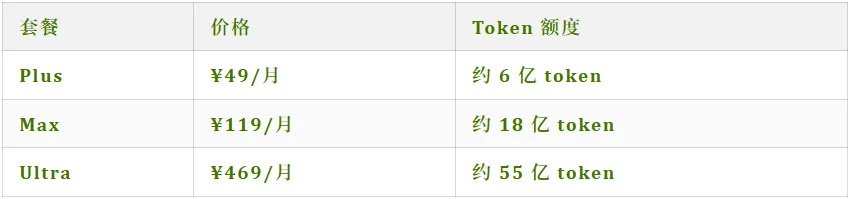
横向对比一下,按官方给的口径,相同价格下的用量会比同档 Claude 便宜很多。
🚥
回头看这次更新,M3、MiniMax Code 和 Token Plan 是 MiniMax 给开发者提供的一套组合:一个能打的模型,一个配套的 Agent,加上一个用得起的价格。
当然,M3 和 Opus 4.7、GPT-5.5 之间的体感差距、1M 上下文的实际表现,还需要开发者们用时间和真实使用来回答。
不过放在更长的时间线上看,从 M2 到 M3,MiniMax 这一年的更新节奏并不慢。
这次也一样:新模型、配套的 Agent、技术博客、新的 Token Plan,几乎是一起放出来的。按官方说法,模型权重也会在十天内开源。
模型更新得越来越快,快到容易让人忘记:
把一个模型做扎实,本来是件慢功夫的事。
或许,对于能走得远的团队来说,能不能按着自己的节奏、思路,稳定地将模型迭代下去。

本文来自转载十字路口Crossing ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫