2026 年上半年,国产大模型赛道正式告别了纯粹的参数竞赛,进入了工程落地与商业性价比的贴身肉搏阶段。
智谱 AI、通义千问与月之暗面推出的三款最新旗舰,分别在自主编程、通用智能以及多智能体协作领域建立了显著优势。
为了协助企业和开发者完成技术选型,根据当前已公布的信息,对这三款已正式发布的模型进行横向拆解。
一、 核心指标数据
-
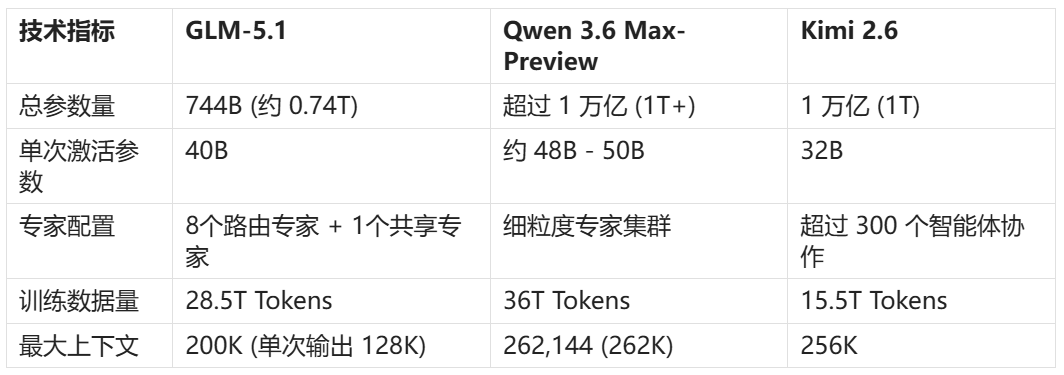
核心技术参数
当前的顶尖模型均采用 MoE 混合专家架构,但各家的专家配置与训练规模体现了不同的技术路径。
-
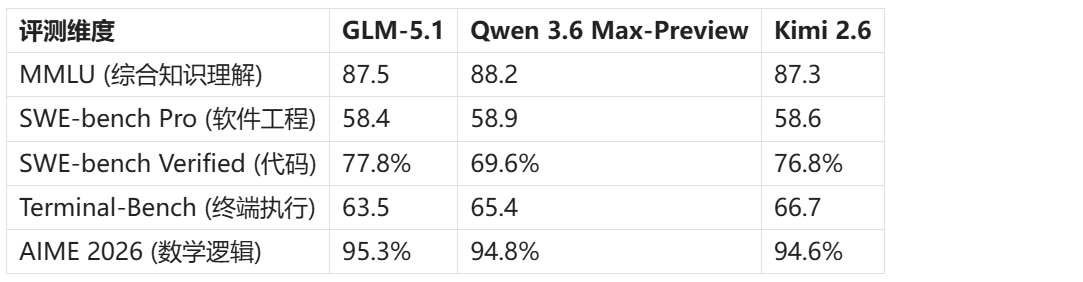
核心能力评测 (2026.04)
数据来源于各厂商技术白皮书及第三方公开评测。
-
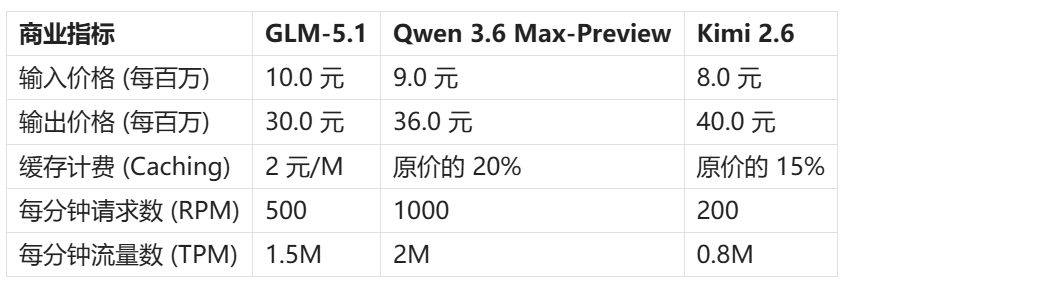
商业定价与并发能力
这是决定业务能否跑通、成本能否覆盖的关键指标。
二、 模型能力深度分析与选型参考
-
GLM-5.1:逻辑严密的工程专家
智谱本次发布的 5.1 版本采用了异步强化学习框架,其核心突破在于长时间、高强度的自主工作能力。它在代码修复这一细分领域表现最出色。
它生成的代码规范、标准,极少出现多余的废话或逻辑漏洞。
点评:GLM-5.1 的输出单价是三者中最低的,对于那些需要大批量产出代码、脚本或技术文档的研发场景,它能帮企业省下不少钱。
适用场景:自动化代码重构、复杂算法开发、长达数小时的自主任务处理。
-
Qwen 3.6 Max-Preview:反应迅速的全能选手
阿里通义千问 3.6 依托 36T 的庞大训练数据,在知识储备的广度上几乎没有死角,是目前国产模型中综合素质最平衡的一款。
得益于阿里云百炼平台的算力储备,它的并发承受能力极强,响应速度也最稳定。在处理含糊不清的中文指令时,它的理解力非常到位。
点评:1000 RPM 的并发额度意味着它能够应对大规模的线上流量,不需要像其他模型那样频繁申请扩容。
适用场景:高并发的在线客服、大流量的业务助手、多语言全球化业务。
-
Kimi 2.6:善于协作的深度智囊
Kimi 2.6 的特色在于多智能体协作能力,它在真实终端操作(比如执行数据库命令或系统指令)时准确率最高。
Kimi 采取了极其进取的定价策略。它的输入价格最低,且缓存计费仅为原价的 15%。这摆明了是在吸引那些需要反复读取几百份 PDF 或长篇财报的用户。
点评:虽然它的并发限制比较紧,响应速度也不算最快,但它在处理超长文档时的召回极其精准,是复杂调研的一把好手。
适用场景:海量法律文书分析、科研调研对比、需要高精度执行的复杂工作流。
三、 总结与决策建议
国产大模型已经从能不能用进化到了好不好用的阶段。
建议根据您业务中输入输出的比例,以及对逻辑深度的要求进行针对性部署。
看重代码质量和输出性价比
选 GLM-5.1。它的代码逻辑最硬,且输出费用最划算。
看重并发稳定和全能表现
选 Qwen 3.6 Max-Preview。它是目前商业落地最稳的选择,适合作为企业级的基础底座。
看重长文本分析和深度搜索
选 Kimi 2.6。利用它的缓存优惠政策,可以大幅降低处理海量资料的成本。
本文来自转载yishan ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫