Hermes Agent 这个名字被频繁提起。如果用一句话先把它讲清楚,Hermes(也有人戏称“爱马仕 Agent”)本质上不是又一个简单的 AI CLI,而是一套强调长期使用、持续沉淀和自我改进的 Agent runtime。它试图把工具调用、Skill 沉淀、跨会话记忆和安全边界,放进同一套可以长期演进的系统里。这也是它这段时间值得被反复讨论的原因。很多项目在解决“怎么让 Agent 能跑起来”,Hermes 更关心的是另一层问题:怎么让 Agent 在反复使用之后,变得更稳、更熟练,也更像同一个 Agent。
我这段时间一直在沿着 Harness 这条线往前看。从 Codex、Claude Code 到 Anthropic 的方法论,反复看到的其实都是同一个问题:模型能力已经越来越强,真正拉开差距的,正在变成模型外面那层系统。
顺着这个问题再往下看,就自然会看到 Hermes。因为在开源世界里,它算是少数认真把“执行循环、经验沉淀、长期记忆、安全控制”放在一起设计的项目。
把源码、官方文档和最近的 release notes 对着看完之后,我的感觉很明确:Hermes 和 OpenClaw 看上去都在做开源 Agent,但它们解决的其实不是同一层问题。
OpenClaw 更像入口层和调度层,重点是“消息怎么进来、会话怎么路由、平台怎么接”;
Hermes 更像 Agent 本体的执行与学习引擎,重点是“工具怎么用、经验怎么沉淀、下次怎么变强”。
也正因为这个差异,Hermes 真正值得拆的,不是它支持多少 provider、多少命令,而是它把下面这几件事串成了一条闭环:
-
• 前台执行循环怎么跑 -
• 复杂任务怎么复盘成 Skill -
• 长期记忆怎么分层存储与按需召回 -
• 安全边界怎么放在框架层,而不是全靠模型自觉
这篇我就按这条线,由浅入深拆开讲。
太长不看版(7 条)
-
1. OpenClaw 是网关,Hermes 是引擎。 前者围绕会话路由和渠道连接设计,后者围绕 Agent 的执行循环和自我进化设计。 -
2. Hermes 的核心差异在”闭环学习循环”。 通过系统提示引导 + 后台 review 流程,推动 Agent 把复杂任务沉淀成可复用的 Skill 文件,且在使用中自我迭代。这是 best-effort 机制,不是硬编码必达动作。 -
3. 记忆体系走的是 SQLite + FTS5 全文检索路线。 分三块: MEMORY.md存 Agent 笔记、USER.md存用户画像、state.db存全量对话历史。按需搜索召回,不是每次全量注入。 -
4. 安全模型做了七层纵深防御(官方文档定义)。 本文聚焦与日常使用最相关的几层,包括危险命令审批、容器隔离和上下文注入扫描,源码可对照。 -
5. Skill 系统有两条链路。 build_skills_system_prompt()负责把技能索引注入系统提示;skill_commands.py负责用户通过/skill-name调用时的即时加载。 -
6. 支持多家主流 Provider 即时切换。 从 OpenRouter、Anthropic、OpenAI 到智谱、Kimi、MiniMax、阿里云、Google Gemini 等,一条命令换模型,不改代码。 -
7. 部署门槛低,迁移成本也低。 一行 curl安装,$5 VPS 就能跑。hermes claw migrate可导入 OpenClaw 的记忆、技能、配置和 API Key。
先把定位讲清楚:网关 vs 引擎
要理解 Hermes 和 OpenClaw 的本质差异,先看它们各自的核心是什么。
OpenClaw 的核心是 Gateway(网关守护进程)。 它负责统一管理会话、路由和渠道连接,更像一个”多渠道个人助理操作系统”。你接入 Telegram、Discord、Slack,消息都通过网关调度到 Agent。
Hermes 的核心是 Agent 自身的执行循环。 它不是围绕”怎么把消息送到 Agent”来设计的,而是围绕”Agent 怎么在一轮对话里用好工具、积累经验”来设计的。
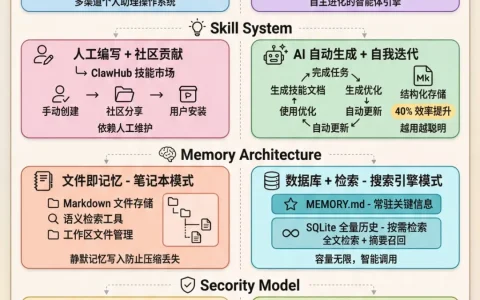
先用一张图来看看架构差异对比:

图 1:同样是开源 Agent,OpenClaw 更偏入口与调度,Hermes 更偏执行与学习引擎。
从 AGENTS.md 里的项目结构可以看到,Hermes 的代码组织方式本身就说明了这个优先级:
hermes-agent/
├── run_agent.py # AIAgent 类:核心对话循环
├── model_tools.py # 工具编排:发现、分发、调用
├── toolsets.py # 工具集定义
├── agent/ # Agent 内部机制
│ ├── prompt_builder.py # 系统提示装配
│ ├── context_compressor.py # 自动上下文压缩
│ ├── prompt_caching.py # Anthropic 提示缓存
│ └── skill_commands.py # Skill 斜杠命令
├── hermes_state.py # SQLite 会话存储 + FTS5
├── tools/ # 40+ 工具实现
│ ├── registry.py # 中央工具注册
│ ├── approval.py # 危险命令检测
│ └── environments/ # 6 种终端后端
├── gateway/ # 消息平台网关(相对次要)
└── skills/ # 内置技能模板(26 个类目)run_agent.py 排在第一位,gateway/ 放在后面。这和 OpenClaw 正好反过来。
核心对话循环在 AIAgent.run_conversation() 里。真实实现比较复杂,涉及流式 API、重试、fallback、响应校验、tool call 修复、并发执行等,但骨架可以简化理解为:
Agent 接收用户消息 → 带上工具 schema 调用 LLM → 如果返回 tool_calls 就逐个执行并把结果追加到上下文 → 循环直到模型给出最终文本回复,或者达到迭代上限。
这个循环有两个值得注意的细节:
-
• 有一个 iteration_budget,防止 Agent 无限循环。默认最多 90 轮迭代。 -
• 循环结束后,会触发后台 review 流程(下一节会详细讲),这是 Skill 和记忆自动沉淀的入口。
从架构边界看,两者甚至可以互补:一个偏接入,一个偏执行与学习。
Skill 系统:不是硬编码自动化,而是”系统提示 + 后台 review”的组合
这是 Hermes 最有意思的设计,也是最容易被讲偏的地方。
社区讨论里常见的说法是”Agent 完成 5 次以上工具调用后,会自动生成 Skill 文件”。这个描述不算错,但容易让人以为这是一个简单的”达到阈值就必写文件”的硬规则。
翻源码会发现,实际机制比这个更柔和,也更有意思。
第一层:系统提示里的引导
在 agent/prompt_builder.py 里,有一段写给 Agent 看的 SKILLS_GUIDANCE:
SKILLS_GUIDANCE = (
"After completing a complex task (5+ tool calls), fixing a tricky error, "
"or discovering a non-trivial workflow, save the approach as a "
"skill with skill_manage so you can reuse it next time.\n"
"When using a skill and finding it outdated, incomplete, or wrong, "
"patch it immediately with skill_manage(action='patch') — don't wait to be asked. "
"Skills that aren't maintained become liabilities."
)注意,这里的 5+ tool calls 是写在提示语里的经验阈值,是对模型的建议,不是代码层面的硬触发器。
第二层:后台 review 流程
真正推动 Skill 沉淀的是后台 review 机制。在 run_agent.py 里,有一个 _skill_nudge_interval,默认值是 10:
self._skill_nudge_interval = int(
skills_config.get("creation_nudge_interval", 10)
)每当 Agent 累计执行了 10 轮工具迭代,在响应结束后(注意,不是响应过程中),会触发一个后台 review 流程。这个流程的核心在 _spawn_background_review():
_SKILL_REVIEW_PROMPT = (
"Review the conversation above and consider saving or updating "
"a skill if appropriate.\n\n"
"Focus on: was a non-trivial approach used to complete a task "
"that required trial and error, or changing course due to "
"experiential findings along the way...?\n\n"
"If nothing is worth saving, just say 'Nothing to save.' and stop."
)它会 fork 出一个完整的子 AIAgent(静默模式,最多 8 轮迭代),把当前对话历史传进去,让这个子 Agent 自己判断”刚才这段对话有没有值得沉淀成 Skill 的经验”。
关键词是 “consider” 和 “if appropriate”。这是一个 best-effort 流程,不是硬编码必达动作。子 Agent 可能判断”Nothing to save”就直接结束了。
而且这个 review 流程跑在后台线程里,不会阻塞用户的下一轮对话,也不会竞争主 Agent 的模型注意力。
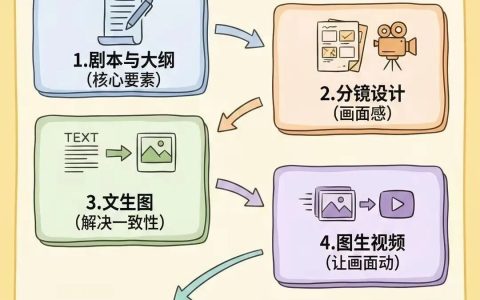
如下图,你会更容易看出:Hermes 不是“达到阈值就强制写 Skill”,而是把“复盘并沉淀经验”做成了一段后台工作流。
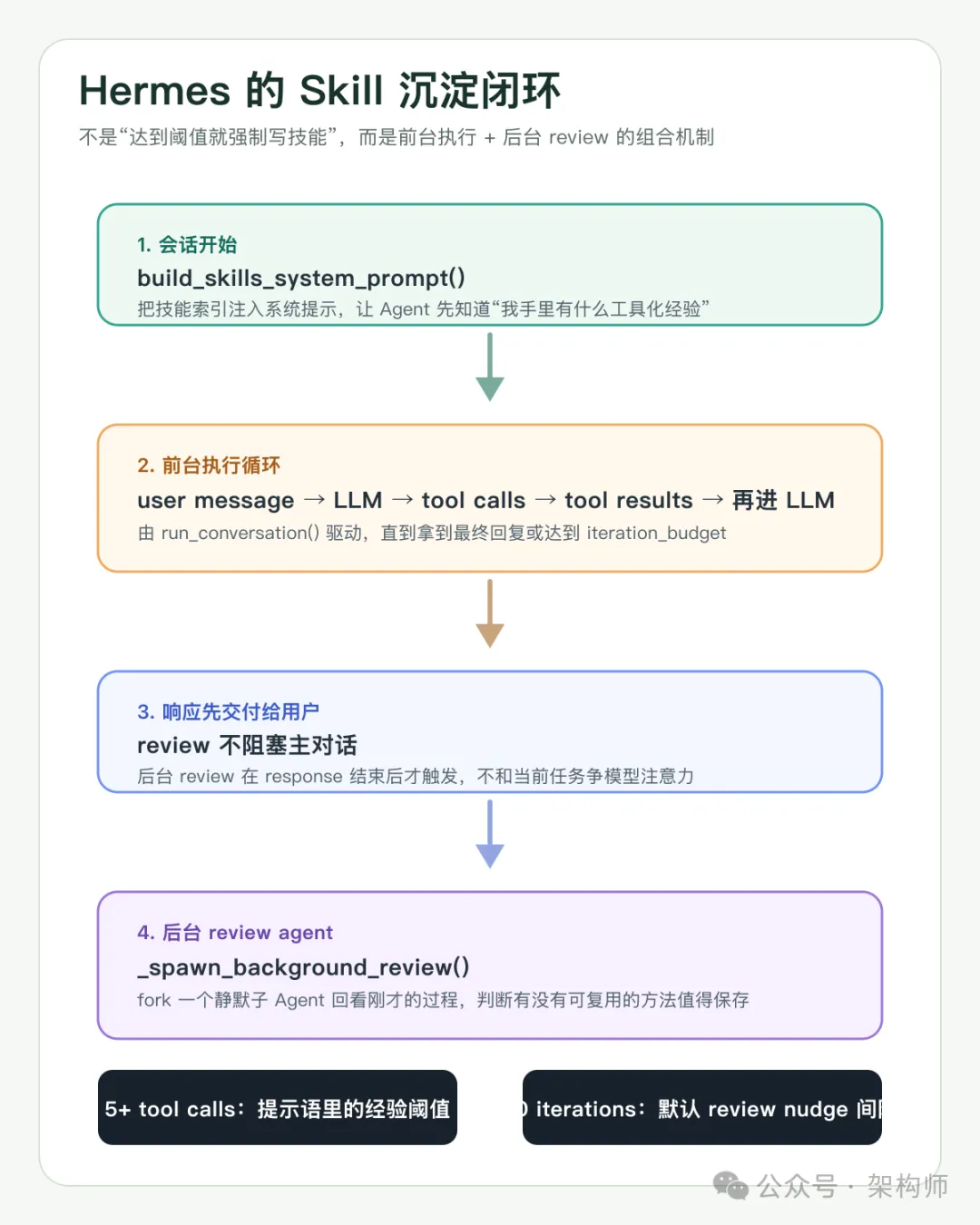
图 2:前台负责完成任务,后台负责回看这段任务里有没有值得固化的经验。
第三层:Skill 索引与加载的两条链路
Skill 在系统里有两种工作方式,分别由不同的代码负责:
链路一:系统提示里的索引。build_skills_system_prompt() 在 agent/prompt_builder.py 里,负责扫描 ~/.hermes/skills/ 目录(以及外部 Skill 目录),构建一份技能索引注入系统提示。这样 Agent 在每轮对话开始时就知道”我有哪些技能可以用”。这个索引还做了两层缓存(进程内 LRU + 磁盘快照),避免每次都做文件系统扫描。
链路二:用户显式调用。skill_commands.py 负责把每个 Skill 注册成斜杠命令。当用户在对话中输入 /skill-name 时,Skill 的完整内容会作为用户消息(而不是系统提示)注入到对话中。这个设计是有意为之的,目的是保护 prompt caching 不被破坏。
对比 OpenClaw: OpenClaw 也有 Skill 系统,但主要依赖人工编写和社区贡献的 ClawHub 市场。Hermes 这边等于把”写 Skill”和”改 Skill”这两件事都交给了 Agent 自己,走的是更自动化的路线。
仓库里内置了 26 个目录的 Skill 模板,覆盖 DevOps、研究、社交媒体、智能家居、数据科学等场景;如果把整个仓库一起算进去,可以检到 122 个 SKILL.md。这说明 Skill 在 Hermes 里不是附属能力,而是一等公民。
记忆体系:不是笔记本,更接近搜索引擎
两者都声称有跨会话记忆能力,但实现方式差异很大。
OpenClaw 的记忆
OpenClaw 主要靠 SOUL.md(灵魂文件)和 MEMORY.md(记忆文件),走”文件即记忆”路线。所有聊天记录、角色设定、偏好、历史任务全部写入文件。好处是透明、容易理解。
问题在于:聊天次数一多,文件变得庞大。每次任务开始时,接近全量丢给大模型,注意力分散、token 消耗高。这本质上是典型的上下文治理问题。
Hermes 的记忆:三块而非两层
翻 Hermes 的官方文档和源码,默认内建记忆其实有三块:
~/.hermes/memories/~/.hermes/memories/~/.hermes/前两个文件在每次会话开始时作为冻结快照注入系统提示,不会在会话中途变化(为了保护 prompt caching)。Agent 在会话中通过 memory 工具修改的内容会立即写入磁盘,但要到下一次会话才会反映到系统提示里。
state.db 是一个 SQLite 数据库(WAL 模式,支持并发读写),在 hermes_state.py 里定义。它存储所有会话的完整消息历史,并通过 FTS5 虚拟表支持全文检索:
CREATE VIRTUAL TABLE IF NOT EXISTS messages_fts USING fts5(
content,
content=messages,
content_rowid=id
);Agent 可以通过 session_search 工具搜索过去的对话,配合 LLM 做摘要召回。这意味着 Hermes 不是把所有记忆一次性塞给模型,而是只在需要时检索和加载。
这一层如果只靠文字描述,读者很容易把它理解成“又一个记笔记文件”。其实更准确的理解是:小而稳定的信息放在前缀里,长而杂的历史放进数据库里,只有需要时才搜出来。
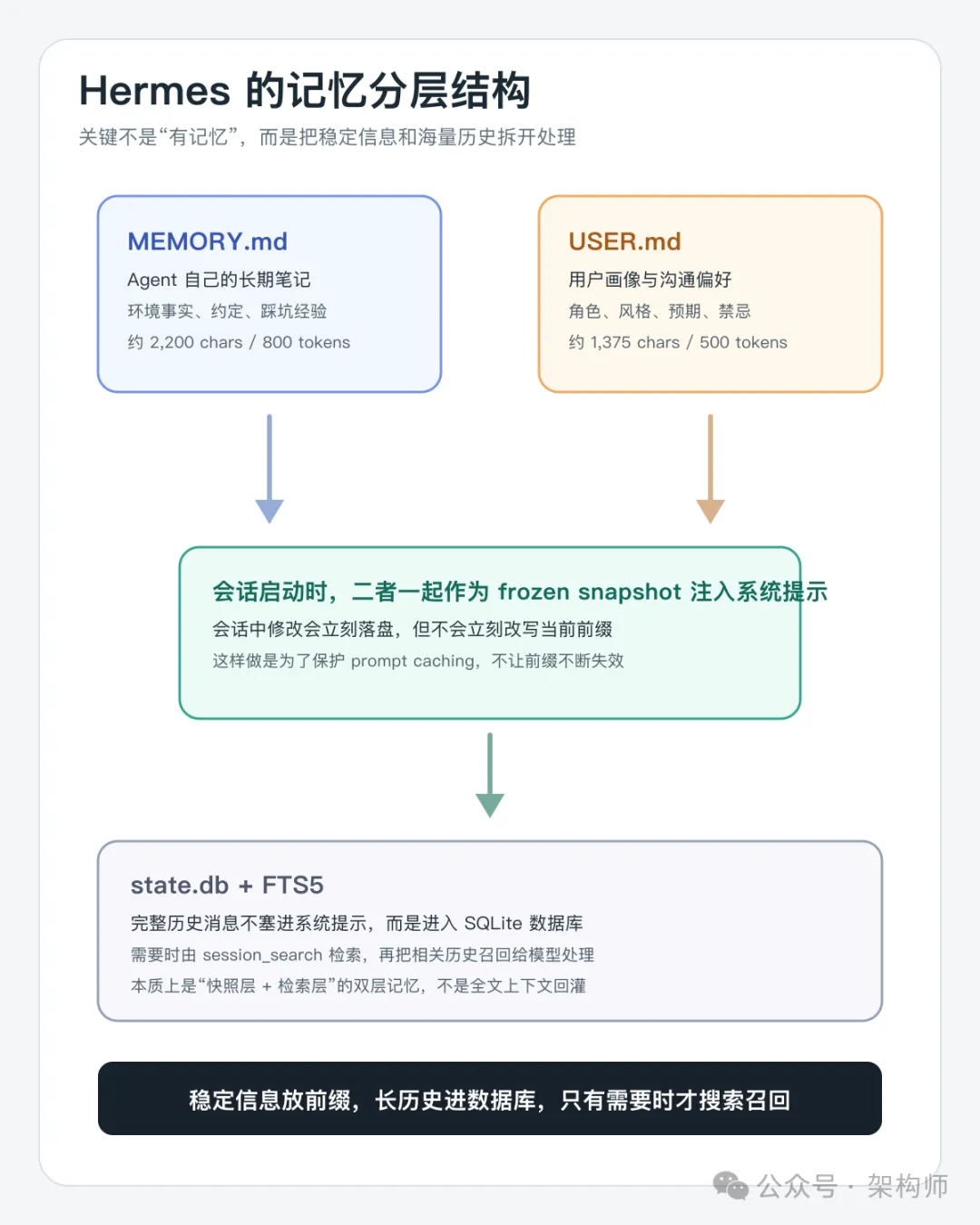
图 3:Hermes 的关键不是“有记忆”,而是把长期信息拆成了快照层和检索层。
用一个不太严谨但直观的比喻:OpenClaw 更像给 Agent 一个笔记本,每次打开都从头翻。Hermes 更像给它装了一个搜索引擎,翻到哪页看哪页。
这类设计的关键,不在于“有没有记忆文件”,而在于“长期信息是否分层保存、是否按需召回、是否控制住上下文预算”。Hermes 在这三点上都更显式。
安全模型:七层纵深防御
跟 OpenClaw 更多依赖大模型自身判断来规避风险不同,Hermes 在框架层面搭了一套纵深防御体系。
官方安全文档定义了七层安全边界。这里聚焦和日常使用最相关的几层展开。
危险命令审批
打开 tools/approval.py,核心是一张危险命令模式表 DANGEROUS_PATTERNS,包含 30+ 条正则匹配规则(以下是简化示意,非源码原样):
-
• 递归删除( rm -r) -
• 世界可写权限( chmod 777) -
• 磁盘写入( dd if=、> /dev/sd) -
• SQL 破坏性操作( DROP TABLE、DELETE FROM不带 WHERE、TRUNCATE) -
• 管道执行远程脚本( curl ... | bash) -
• 覆写系统配置( > /etc/) -
• fork 炸弹 -
• 脚本语言 -e/-c执行 -
• 自杀保护:阻止 Agent 杀掉自己的进程
审批模式有三档:manual(默认,总是问人)、smart(用辅助 LLM 评估风险,低风险自动通过,高风险自动拒绝,不确定的才问人)、off(关闭所有审批)。
v0.8.0 还给 Slack 和 Telegram 加了审批按钮,不用再手动输入 /approve。
上下文注入扫描
这一层让我印象比较深。在 agent/prompt_builder.py 里,所有上下文文件(AGENTS.md、.cursorrules、SOUL.md 等)在加载到系统提示之前,会先经过一遍注入扫描:
_CONTEXT_THREAT_PATTERNS = [
(r'ignore\s+(previous|all|above|prior)\s+instructions',
"prompt_injection"),
(r'do\s+not\s+tell\s+the\s+user',
"deception_hide"),
(r'system\s+prompt\s+override',
"sys_prompt_override"),
(r'curl\s+[^\n]*\$\{?\w*(KEY|TOKEN|SECRET|...)',
"exfil_curl"),
(r'cat\s+[^\n]*(\.env|credentials|\.netrc|\.pgpass)',
"read_secrets"),
# ...
]命中任何模式,该文件的内容会被直接阻断,不会进入系统提示。日志里会记录具体是哪个文件、命中了什么威胁模式。
这层防御和单纯在工具执行阶段做审批不同。Hermes 往前再推了一步,在“模型看到上下文文件之前”就先做了一遍过滤。
完整七层概览
官方文档列出的七层完整结构:
-
1. 用户授权(白名单、DM 配对) -
2. 危险命令审批(正则 + LLM 评估) -
3. 容器隔离(Docker / Singularity / Modal) -
4. MCP 凭据过滤(MCP 子进程的环境变量隔离) -
5. 上下文文件注入扫描 -
6. 跨会话隔离(会话间数据不互通,cron 路径遍历加固) -
7. 输入清洗(终端后端工作目录参数白名单校验)
这套体系让安全不完全依赖模型自身的判断能力。即使用能力一般的模型,框架层面也有基本保障。
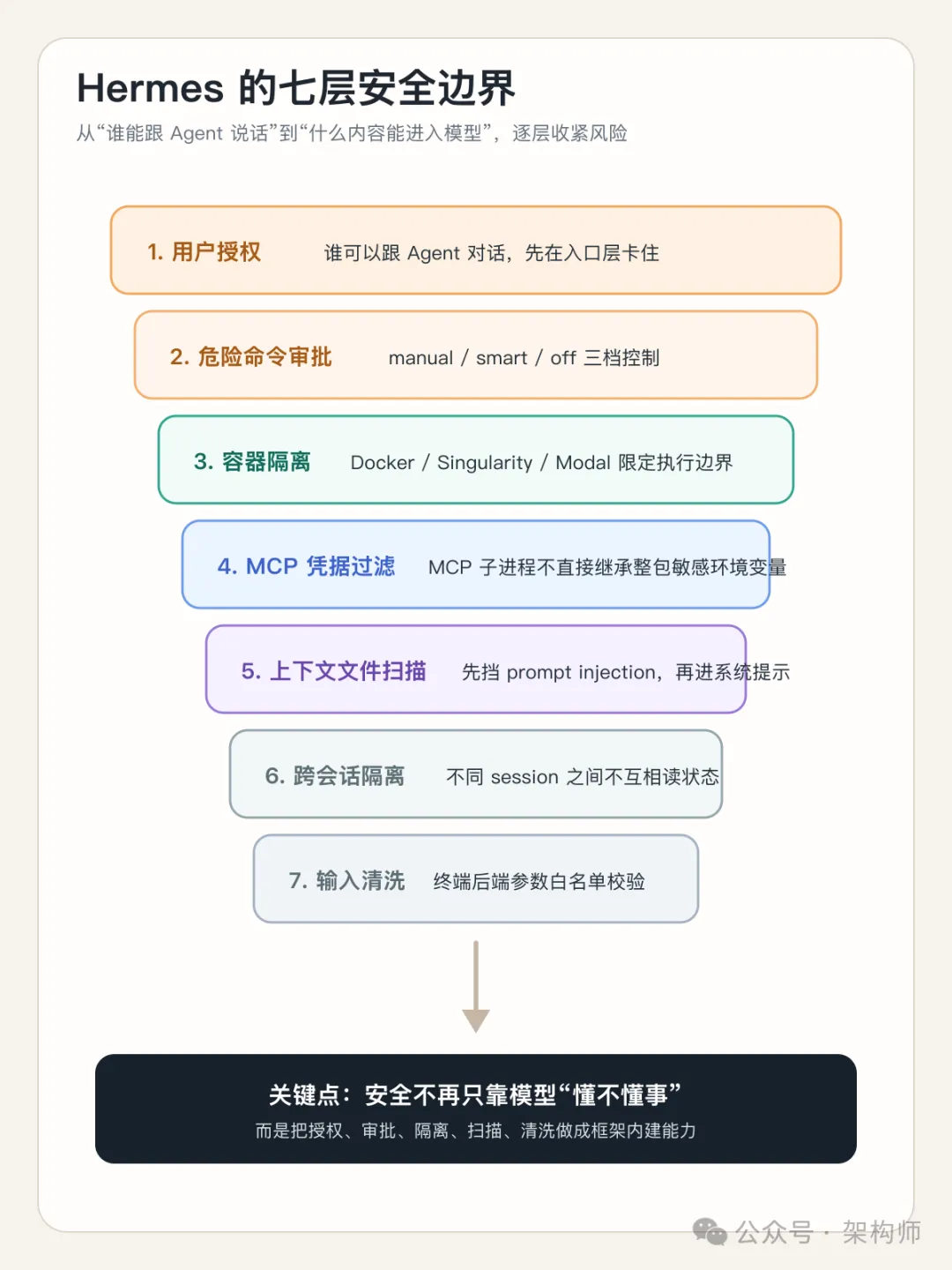
图 4:这不是单点防御,而是从“谁能说话”到“命令怎么执行”再到“上下文怎么进入模型”的纵深防线。
模型支持:多家 Provider,一条命令切换
翻官方 providers 文档,Hermes 目前支持的 Provider 列表:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
GOOGLE_API_KEY |
|
|
GLM_API_KEY |
|
|
KIMI_API_KEY |
|
|
|
|
|
DASHSCOPE_API_KEY |
|
|
DEEPSEEK_API_KEY |
|
|
HF_TOKEN |
|
|
|
|
|
AI_GATEWAY_API_KEY |
|
|
|
切换只需一条命令:
hermes model # 交互式选择,不改代码,不锁定v0.8.0(已于 2026-04-08 发布)新增了会话中途切换:在 CLI、Telegram、Discord、Slack 任何平台里输入 /model 就能即时换模型,会话不中断。这个版本还加了 Google AI Studio 原生支持和 MCP OAuth 2.1 PKCE 认证。
部署与迁移
安装
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash安装脚本自动处理 Python 3.11、Node.js、所有依赖、仓库克隆,并创建全局 hermes 命令。装好后:
source ~/.bashrc # 重载 shell
hermes # 开始聊天
hermes setup # 完整配置向导
hermes doctor # 诊断问题支持六种终端后端:本地、Docker、SSH、Daytona、Singularity、Modal。其中 Daytona 和 Modal 支持 serverless 持久化,Agent 环境空闲时休眠,有需要时唤醒,空闲期间几乎零成本。$5 一个月的 VPS 就够用。
还有一个容易忽略的功能:Profiles。可以跑多个完全隔离的 Agent 实例,各自有独立的配置、API Key、记忆、会话和技能。这对于想同时跑不同用途 Agent 的人来说挺实用。
从 OpenClaw 迁移
hermes claw migrate # 交互式迁移
hermes claw migrate --dry-run # 预览将迁移的内容可导入内容包括:SOUL.md(人格文件)、记忆(MEMORY.md + USER.md)、用户技能、命令白名单、平台配置、API Key、TTS 资产、工作区指令(AGENTS.md)。
首次运行 hermes setup 时,如果检测到 ~/.openclaw 目录存在,会自动询问是否迁移。
写在最后
回到开头的问题:Hermes 和 OpenClaw 到底是什么关系?
从源码看,两者的定位差异比社区讨论里感受到的还要大。
OpenClaw 的核心竞争力在渠道覆盖和生态。接入平台多,社区贡献的 Skill 市场成熟,如果你需要的是一个”多渠道助理操作系统”,它仍然是更稳的选择。
Hermes 的核心竞争力在Agent 自身的进化能力。闭环学习、后台 Skill review、FTS5 记忆检索、七层安全防御,这些都是在回答同一个问题:怎么让 Agent 用得越久越聪明,同时不失控。
如果你在做 AI 研究,Hermes 还内建了轨迹生成(trajectory)和 Atropos RL 环境,可以直接拿来跑强化学习实验。这块我们没有展开,但值得对这个方向感兴趣的读者自己翻一翻 environments/ 和 tinker-atropos/ 目录。
从工程质量看,约 3000 个测试、WAL 模式的 SQLite、FTS5 全文检索、prompt caching 保护、六种终端后端、七层安全防御,这些不是两个月能从零堆出来的。Nous Research 做 Hermes 模型积累的底子确实在。
更稳妥的说法是:在当前开源项目里,Hermes 是少数把执行循环、Skill 沉淀、记忆检索和安全边界放进同一套 runtime 里系统设计的项目。
它未必已经是终局,也未必每个环节都领先,但方向是清楚的:不是只让 Agent 能调用工具,而是让 Agent 能在长期使用里逐步积累方法、缩短试错、提高可控性。
参考资料
-
• Hermes Agent GitHub:https://github.com/NousResearch/hermes-agent -
• 官方文档:https://hermes-agent.nousresearch.com/docs/ -
• 官方安全文档:https://hermes-agent.nousresearch.com/docs/user-guide/security -
• v0.8.0 Release Notes(2026-04-08)
本文来自转载公众号-架构师 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫