Token是什么,Token已经成为一种新的基础的经济要素和战略资源。
AI浪潮奔涌,应用层出不穷,版本迭代日新月异。已经没有人会怀疑“AI将深入我们每个人的生活”这句话的正确性了。但在所有关于AI的讨论中,你一定频繁听到一个词—“Token”。那么,Token到底是什么?
在计算机和互联网技术中,Token是一个非常核心的概念。要讲清楚Token,我们必须知道Token的三个不同的应用场景:
1.身份验证中的Token(又叫做访问令牌)
2.大语言模型(LLM)中的Token(以纯文本语言模型为例进行讲解,此时Token为文本单位) 【这一个应用场景是今天讲的重点】
3.区块链与加密货币中的 Token(代币)
我们先来看第一个应用场景:身份验证中的Token(又叫做访问令牌)
这是我们日常上网最常遇到的。当我们登录一个网站或者App 后,服务器会发给你一个Token
例如:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VySWQiOjEsIm5hbWUiOiJKb2huIERvZSIsImV4cCI6MTcxNjI3MjAwMH0.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
当然你也可能看到更短的Token,显然我给的这个Token比较长。虽然Token有行业通用的格式范式,但是,身份验证中的访问令牌(Access Token)没有统一“固定外观”的。我们不用纠结Token的外观格式是否统一,就简单的理解成一串字母符号的构成。
其工作原理为如下:
1. 你输入账号密码登录
2. 服务器验证通过,生成一个加密字符串(即 Token)发还给你的浏览器或 App。
3. 此后你每次请求数据(比如刷新朋友圈),都会自动带上这个 Token。
4. 服务器看到 Token,就知道“哦,这是张三,他已经登录过了”,而不需要你每次操作都重新输密码。
看了工作原理后,是不是发现作为访问令牌的Token也没那么神秘,就是加密的令牌,方便你有权限在登录成功后访问网站或者APP信息资源的。
下面我们再来看第二个应用场景:大语言模型(LLM)中的Token(以纯文本语言模型为例进行讲解)
当我们和deepseek、ChatGPT 或 Gemini 对话时,我们需要将我们让AI帮我们干的事儿用文字描述给他,这个时候 ,AI 并不是直接按我们常规意义上的“字”或者“词”来进行阅读的。因为计算机是无法直接理解汉字或者英文单词的,我们必须先进行文本拆解。拆解一般分为两种,下面我们就简单的来说明一下。
对于英文而言是比较简单的,因为英文单词通常由空格或标点符号进行分隔的,因此拆解的时候按照空格和标点符号进行拆分即可。比如:句子”I love AI!”会被初步拆成 [“I”, “love”, “AI”, “!”]。

当然英语里面也有比较麻烦的地方,就是一些没有被收录的单词或者比较长麻烦的字,为了省事儿和精确,大模型也会按照前后缀的方式进行拆解,比如:unhappily,就可能会被拆解成[“un”, “happi”, “ly”](前缀“un-”、词根“happi”、后缀“-ly”)。
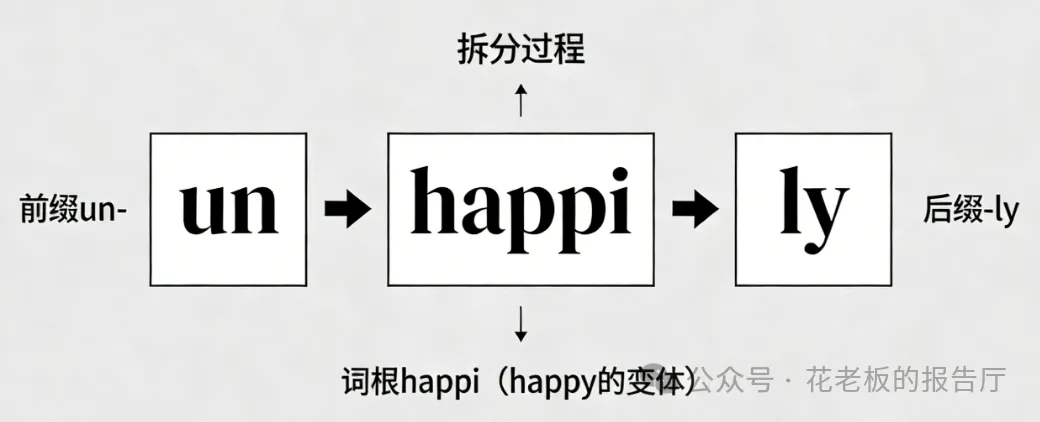
下面我们来讲一下中文,中文拆起来就比较复杂了,因为中文句子是连续的文字,那么拆解的任务就变成了按照意思找到正确的词的边界。
举例:我爱人工智能这句话。我、爱、人、人工、爱人、智能、人工智能等等都是存在的且有意义的独立的词,甚至“智”这一个字都可以是一个词。这时候就需要更强大的算法才能被正确的拆解为[“我”, “爱”, “人工智能”],这就是分词技术。这里就不多讲了,第一是因为它比较晦涩,第二是因为它不是本次讨论话题的重点,你只需要知道我们需要更复杂的算法才有可能将中文拆解的合理。

同样,中文中也有这个字没被收录的情况,比如:“烎”,那他就被拆解为更小的数字编码,如开和火的编码(注:我这边只是举例,实际情况可能有出处,我们只需要知道它被大模型按照自己的规则拆解成更小单位的编码就可以了)。我们要知道,模型只认识数字,所以,当你输入一句话的时候,先执行了上面的拆解步骤,被拆解成字的序列(如:[“我”, “爱”, “人工智能”]),会进行一个关键步骤:查字典,并对应唯一ID。具体方式如下:
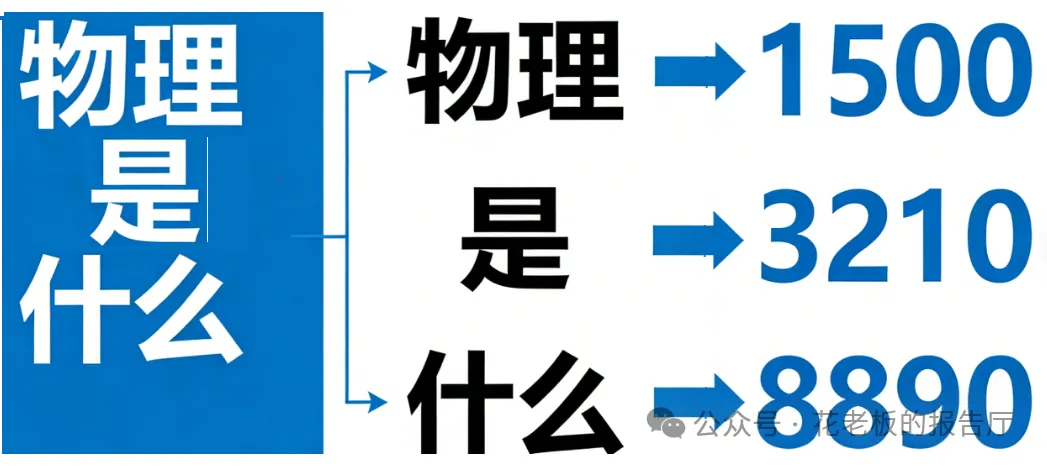
大模型有一个固定的“词表”(Vocabulary)库,一般会包含3万到10万个 Token(也许更多)。每个Token 对应一个唯一的索引数字。说白了就是一个字典一样的表,举例:“我”这个词对应“1500”这个数字,“爱”这个词对应的是3210这个数字,“物理”对应的是8890这个数字。大家注意了,这个数字是我假设的。总之,我们需要理解的是每个词都有自己对应的数字,我们叫他们为Token ID。下面我举个例子方便大家理解:
当你输入“物理是什么” 这句话时,会先被拆成 [“物理”, “是”, “什么”] 三个独立的词(也就是 Token),我们将这个叫做Token序列。通过刚才的讲解,我们了解了,大模型里面有一个 “映射词表”,每个词都对应一个唯一的数字ID,这三个词会通过映射表匹配成[1500, 3210, 8890]这样的数字串。
这些数字ID只是“词的代号”,计算机能处理但不懂它们的意思 —— 接下来会把这些ID送入Embedding层,这一步其实也很容易理解。举例:“物理”这个词如果没有经过Embedding这一层,那么他就是一个空洞的符号,独立的和别的词汇没有关系的词,如果“物理”这个词不能和其他信息相关联,那么我们是不能处理任何任务的。举例:一个人脑子里面只有“物理”两个字,你问他:“物理是什么?”,他能回答你的问题吗?很显然是不能的。大模型也是一样的。所以,这一步相当的重要,他要让物理这个词不再是一个空洞的独立的符号,而是要让它带上“数千个维度的特征”。举例:物理是独立的,但是它的特征有科学、实验、公式等等。在这,物理的坐标会和力学、量子、万有引力、磁场等靠的非常的近,而离苹果、跑步等靠的非常的远。
现在,请大家闭上眼睛,想象一张网,这个网上有很多交织的点,每个点上都有特征词,它们是力学、量子、万有引力、磁场、苹果、跑步、小狗等等。而“物理”这个词,此时在你大脑的中心位置,请想象并将这些词填在这个以“物理”这个词为中心的网络中,那么哪一些词离它更近,哪一些词应该离它更远一些呢。同理,大模型就是这样,将不同远近的特征分布在“物理”这个词为中心的网络中,这样大模型就可以通过远近来计算这些词和词之间的关系了。
现在这些词较之前虽然有了远近。但是,它们之间还没有联系,此时大模型就会通过一个叫“注意力机制”的东西分析词和词之间的关系,并将相关的词联系起来。就拿“物理是什么”这句话来讲,分析后就知道“物理”是主语,“什么”是宾语,“是”将他们联系了起来。此时,模型才会将三个独立的向量融合在一起,这些词再也不是孤立的个体,而是通过注意力机制,融合成了一个带语境的语义整体(在技术上我们叫它“表征”),至此,模型才读懂了我们的问题,“物理是什么”。
这之后,模型就开始进入预测环节,它在数学空间里进行复杂的运算,根据当前的语境向量,计算出概率最大的下一个Token是什么。比如:它预测下一个词是“实验”或“相互关系”等等。模型会将计算出的概率向量重新映射回ID(对应的是一个数字),再通过词的映射表转回人类能懂的文字。这就是我们要的结果了。
下面我通过一个交互流程与Token分解的示例进行进一步的说明:
第一步:您的输入(Prompt)
你输入文本“请帮我用猫造句,给出两个猫的句子”,大模型进行分词和Token化后:
[“请”, “帮”, “我”, “用”, “猫”, “造”, “句”, “,”, “给出”, “两个”, “猫”, “的”, “句子”]
所以,输入的Token数量:13个
第二步:模型输出(Reponse)
文本:“我特别喜欢小猫” 和 “小猫真的是一种非常可爱的生物” 。分词与Token化(示例):
第一句:[“我”, “特别”, “喜欢”, “小猫”]→ 4个Token
连接词:[“和”]→ 1个Token
第二句:[“小猫”, “真的”, “是”, “一种”, “非常”, “可爱”, “的”, “生物”, “。”]→ 9个Token
输出Token数量:4 + 1 + 9 = 14个
所以,本次交互的Token总消耗等于输入Token数 + 输出Token数 = 13 + 14 = 27个Tokens。顺带补充一句,缓存也会随着对话变长而增加消耗,这就是为什么对话越久越贵。
在上面这个例子中,您为总共27个文本单元(Tokens)付费。模型在内部将这27个单元(如“请”、“猫”、“小猫”、“可爱”等)分别转换为27个ID和27组高维向量,并基于它们进行计算,最终生成了您看到的两个句子。每一个您能读到的字、词、标点,只要它占用了模型的一个处理单元,就是一个Token。
Token在转换为数字前的样子如下:
输入端(13个):请 | 帮 | 我 | 用 | 猫 | 造 | 句 | , | 给出 | 两个 | 猫 | 的 | 句子
输出端(14个):“ | 我 | 特别 | 喜欢 | 小猫 | ” | 和 | “ | 小猫 | 真的 | 是 | 一种 | 非常 | 可爱 … (以此类推)
对应转换为Token ID后的样子如下:[ 67854, 45212, 2543, 1209, 78431, 3321, 908, 123, 5542, 1029, 78431, 882, 14520, … ]它就是一串只有机器能看懂的编号。每个数字通常占用 2 字节(16位)或 4 字节(32位)的存储空间。
如果你去翻看大模型的后台日志,你会看到这27 个 Token 的最终消费凭证长这样:

最后,我们再来看第三种场景应用:区块链与加密货币中的Token(代币)
在区块链中的Token和我们上面的含义完全不同,你可以把它理解为数字世界里的“凭证”或“数字物品”。用一个简单的比喻,区块链是一个巨大的、公开的、不可篡改的数字账本。Token可以理解成这个账本上记录的一行唯一的信息,用来代表某种东西的所有权或权益。
以上我已经把Token的三种应用场景全部讲完了,我相信大家已经明白了。而在AI大模型应用领域中,Token就是计算成本和使用量的基本单位,直接对应您消耗的输入和输出文本的总处理量。
掌握了上面我讲的,我想大家就知道为什么说Token已经成为一种新的基础的经济要素和战略资源了。在工业时代,电力是基础,我们按“度”付费;在信息时代,流量是基础,我们按“GB”付费。在人工智能时代,Token是智能的最小计量单位。无论是个人创作、企业自动化还是国家级的算力竞争,本质上都在消耗和生产Token。谁拥有的Token成本更低、处理Token的效率更高,谁就掌握了“智能生产力”的定价权。
Token 让“知识”不再只是书本上的文字,而是变成了可以直接参与生产的“语义资产”。这种资产可以被无限复制、瞬间传输并精准调用。当我们为 27个Token付费时,我们买的不仅仅是文字,而是“被处理过的智能”。正如我们现在已经不再关注发电机如何转动了,而只关注电费单,道理是一样的。我相信,未来社会的所有智力劳动,都会被精准地量化为Token进行流转。它已经不是简单的技术名词了,而是像石油、稀土一样的战略资源。
在物理世界,能量守恒是基本定律;但在数字世界,Token是智能守恒的度量。每一单位Token的背后,本质上都是算力、电力和人类知识密度的总和。
本文来自转载花老板的报告厅 ,不代表发现AI立场,如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫