作者:一个被”网络错误”骗了很久的 Max 用户
作者:一个被”网络错误”骗了很久的 Max 用户/loop、/batch、/debug、/simplify、/claude-api……不管你用不用它们,它们的元数据都在那次请求里。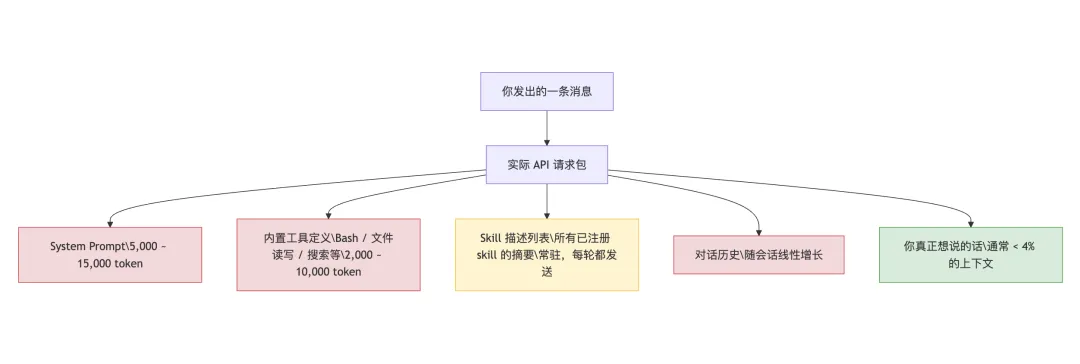
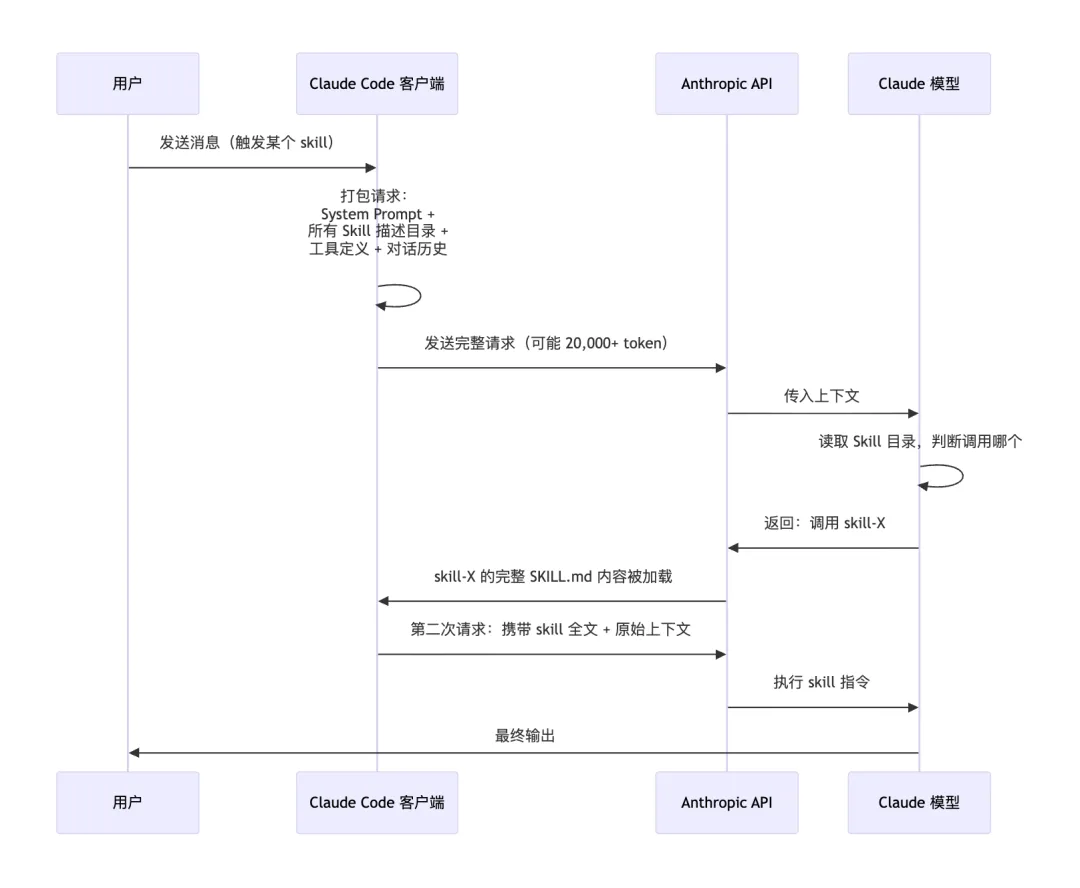
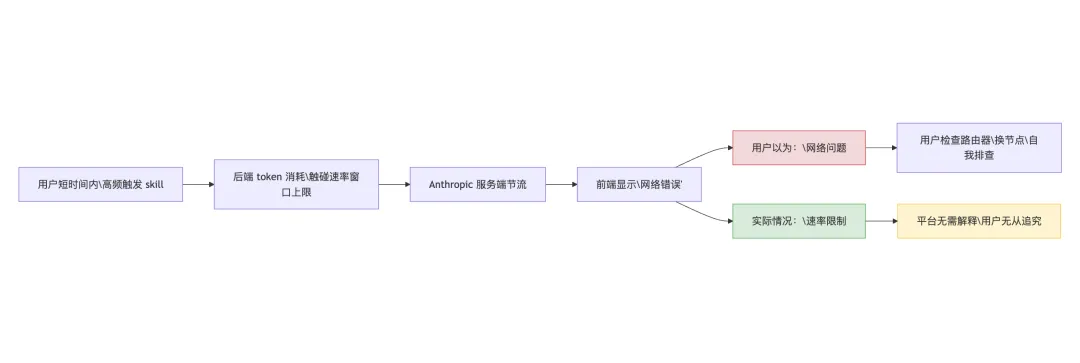
/loop 和 /batch 的描述常驻在你的上下文里。但你没有选择。这些内置 skill 是硬编码的,用户无法完全关闭它们对 token 的占用。/clear 重置上下文。 对话历史会线性累积,不同任务之间如果不清空,你会把上一个任务的所有上下文带入下一个任务,白白消耗 token。disable-model-invocation: true。 这样它们不会出现在常驻描述列表里,只有你手动调用时才会被加载。这是目前用户能做的最有效的 skill 瘦身操作。/cost 和 /context 命令监控实际消耗。 在不知道钱花在哪里之前,先搞清楚钱花在哪里。这两个命令是你的财务报表,应该定期查看。本文来自转载悠酱AI ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫