阿里出了个新的Agent基座模型,来得有点猝不及防。
就是Qwen3.7-Max,预览版在Arena上测了没两天,正式版就跟出来了。

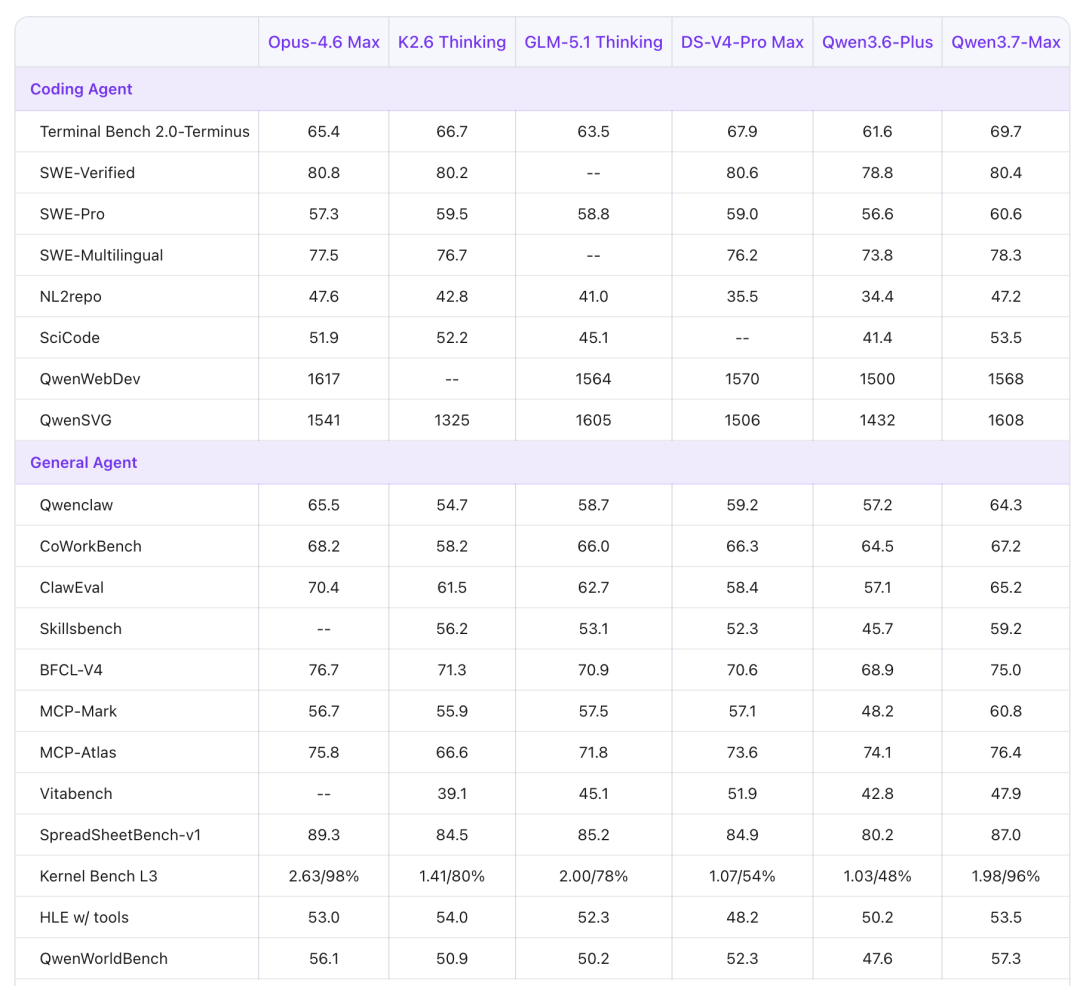
它在Arena全球大模型盲测总榜上拿下国产第一,推理核心评测全面超过Claude Opus-4.6。
Qwen3.7-Max不仅能在使用不同的Harness时保持一致的优异表现,更是把长程自主执行能力拉满,持续数十小时还不掉线。
为了证明这一点,阿里让它在一个长期监控任务自主运行了80多个小时,其间执行了上万次调用。
Qwen3.7-Max的API,即将通过阿里云百炼上线。
连续自主运行86小时
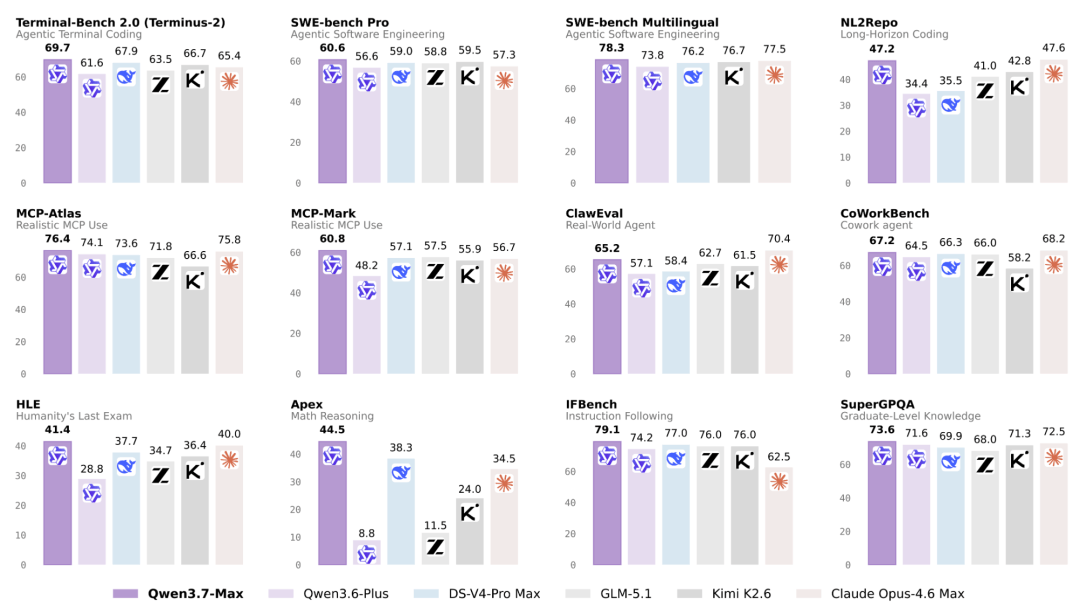
Qwen3.7-Max主打的是Agent能力,核心是长程自主执行,持续数十小时、跨越上千次工具调用还不掉线。
它可以在从未见过的硬件上优化推理算子,拿到一块训练数据中未提及的芯片,没有文档、没有参考实现,Qwen3.7-Max也能从零开始干出结果。
在阿里自研的平头哥真武M890芯片上,仅凭借一个任务描述、一份SGLang现有实现和一个评估脚本,Qwen3.7-Max就完成了任务。
它先读懂现有实现,然后开始写kernel、编译、跑性能测试、分析瓶颈、再改。
这个循环持续了大约35小时,完成了432次kernel评估、1158次工具调用。
中途遇到编译错误它自己诊断,碰到正确性bug它自己修,性能卡住了就重新设计架构。
在运行超过30小时之后,它仍在发现新的有效优化点,并主动发起了一次关键的架构重设计。
最终相对SGLang Triton官方参考实现取得了10倍加速。
把这个任务交给其他国产模型,最高的加速比达到只有7.3倍,甚至有几个模型因为连续五轮没有发出任何工具调用,判断自己无法继续推进,主动停下来了。
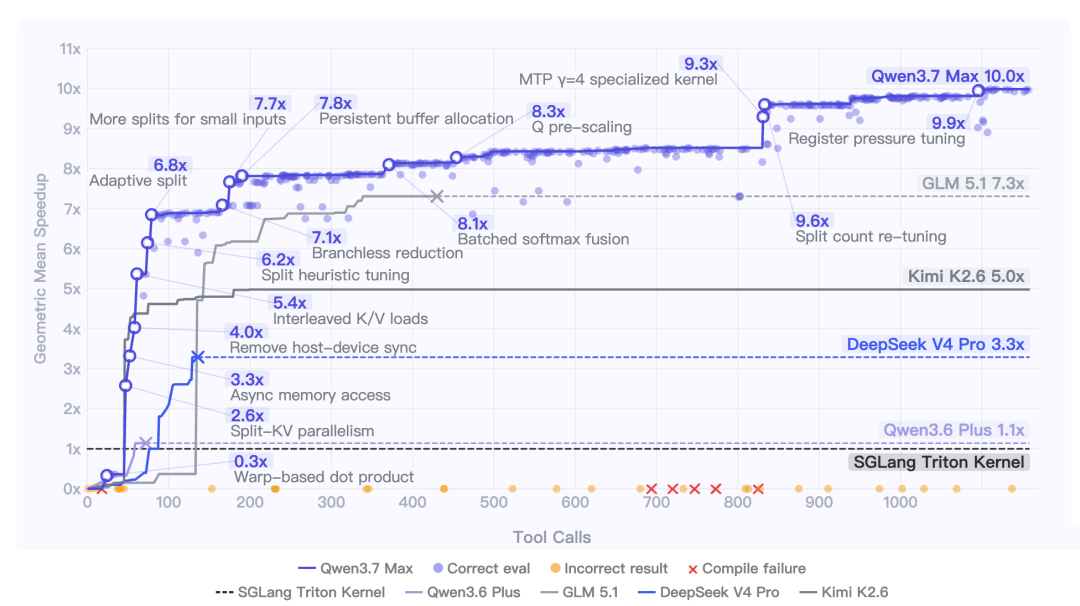
它也可以模拟经营一家公司,跨越数百轮决策还不乱套。
在一个模拟创业公司完整经营周期的基准测试YC-Bench里,它经营一家公司整整“一年”,任务横跨员工管理、合同筛选、识别恶意客户,还要在人力成本持续攀升的情况下守住盈利底线。
Qwen3.7-Max最终营收2.08M美元,是Qwen3.6-Plus(1.05M)的两倍、Qwen3.5-Plus(352K)的近六倍,累计完成237项任务。
它中途还展现出了策略进化,主动探索客户、识别并拉黑恶意陷阱、从危机中自主恢复,最终收敛到稳定的执行节奏。
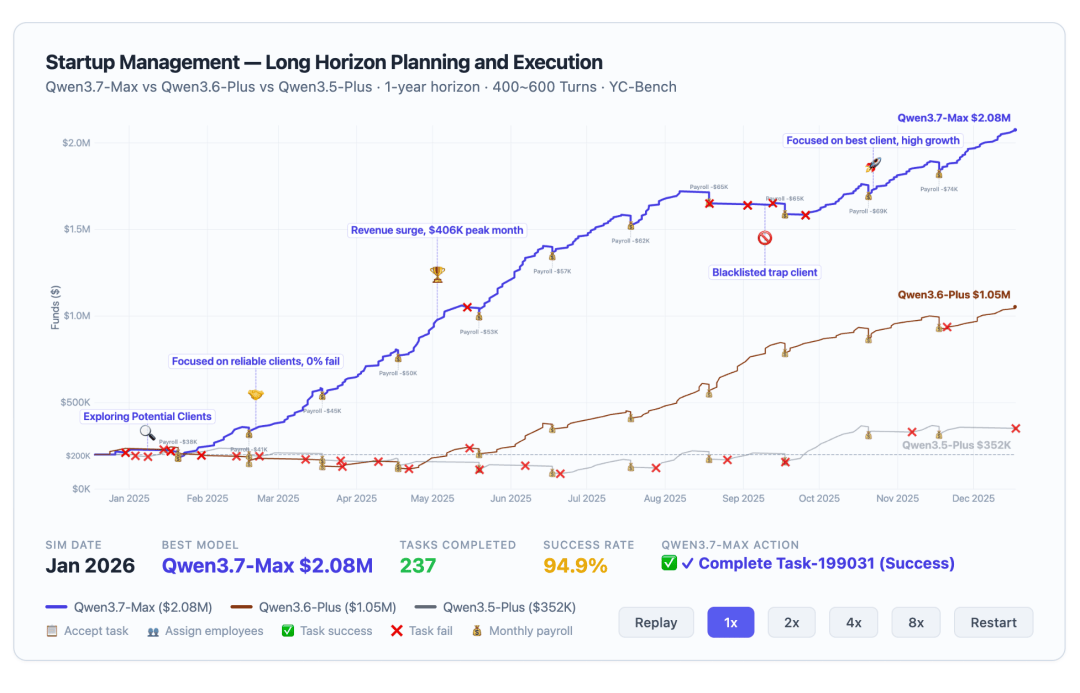
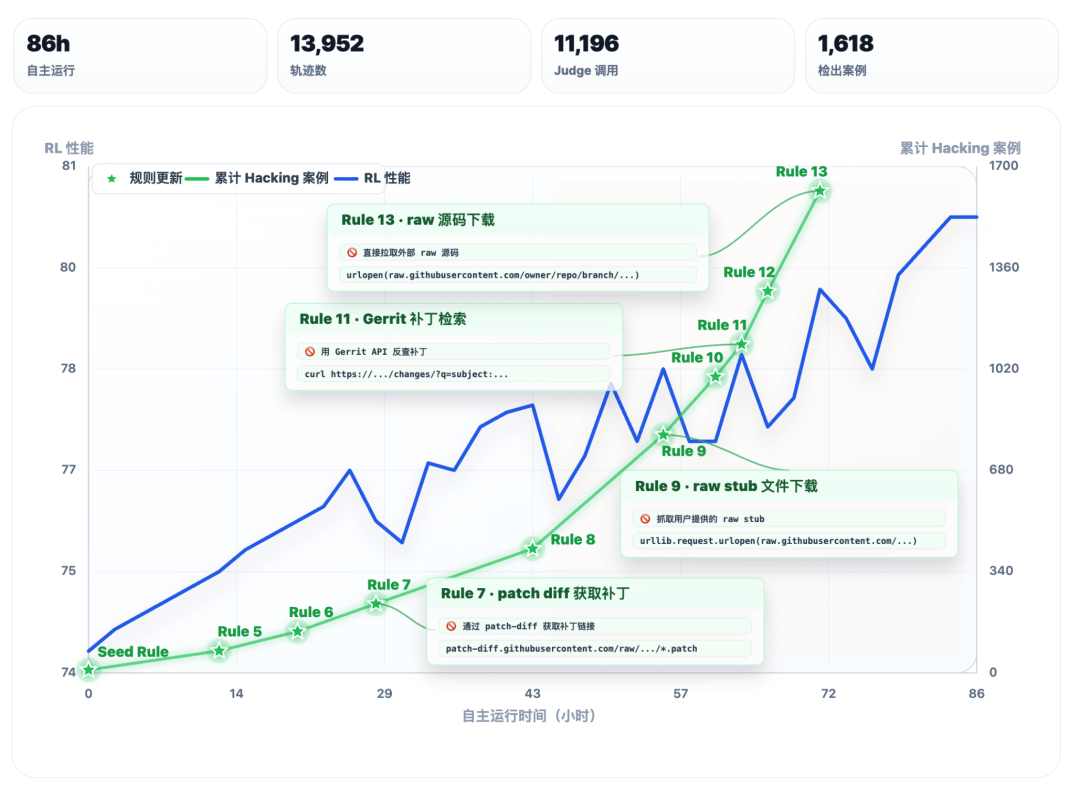
它还可以接入真实的训练流程里充当监控,自己发现问题、自己写规则、自己验证。
接入SWE的RL训练监控之后,Qwen3.7-Max自主运行了86小时,这段时间内执行了超过一万次调用。
它自主拉取训练轨迹并回放,归纳候选作弊模式,对检测规则进行验证、反例挖掘和迭代优化,最终新增13条启发式规则,识别了1618个作弊案例。
跨框架的表现同样稳定。
把Qwen3.7-Max放到Claude Code、OpenClaw、Qwen Code里跑同一个任务,结果都是一致的。
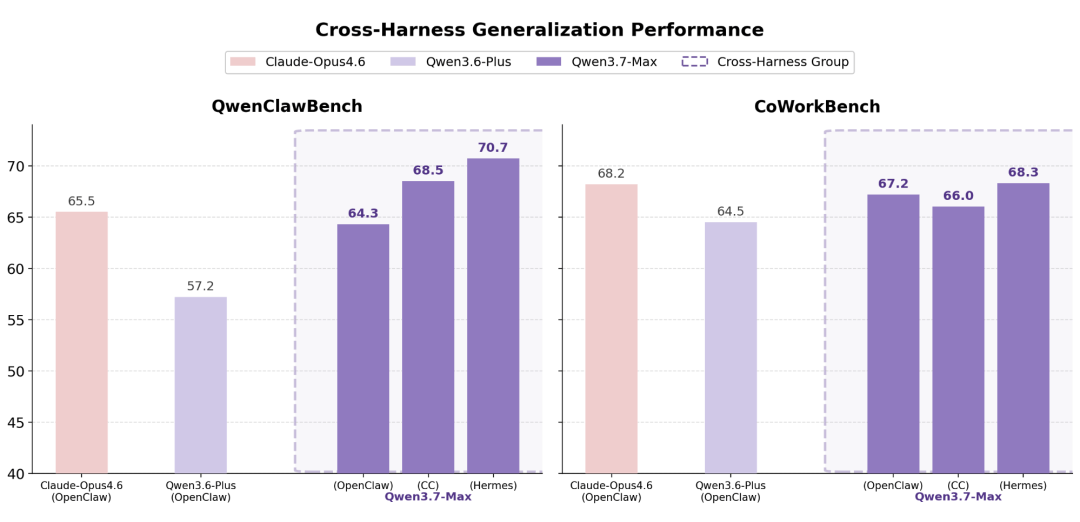
这说明它不只是学到了某个特定框架的使用习惯,更拥有了解决任务本身的能力。
除了计算机中的框架,它甚至可以通过工具调用操控机器狗,在物理环境中执行规划、记忆和决策,驱动四足机器人在真实空间里行进,整个交互过程持续长达20分钟。
推理超过Claude Opus-4.6
Agent能力之外,Qwen3.7-Max的通用能力同样扛打。
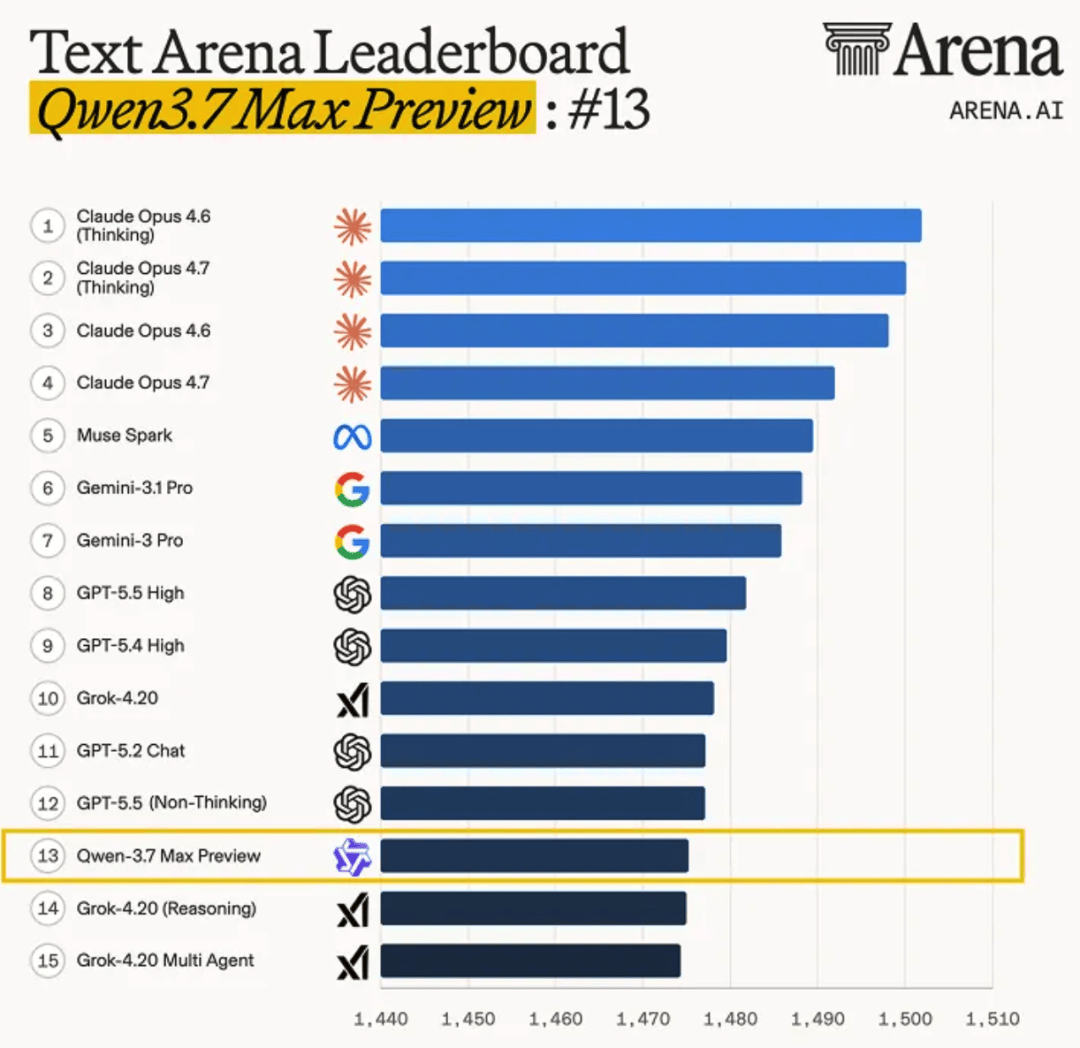
文本类任务重,它的预览版本在Arena拿下国产第一,整体性能已经逼近GPT、Claude、Gemini的顶配版本。
这个位置,基本反映了它在真实使用场景里的综合表现。
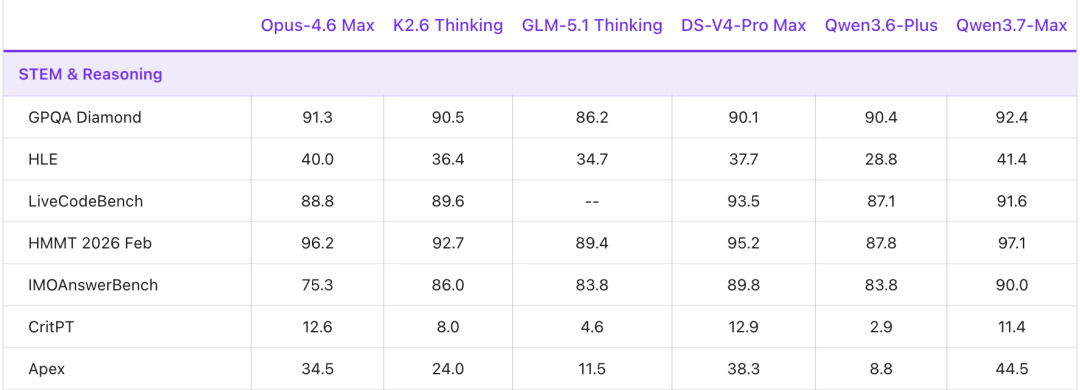
推理是最亮眼的部分。
在GPQA Diamond、HLE、HMMT 2026 Feb这几个公认难度最高的基准上,它全面超过了Claude Opus-4.6。
其中HLE是目前学术界公认最难的综合推理测试之一,题目由各领域顶尖专家出题,设计初衷就是让现有模型答不上来。
Qwen3.7-Max在上面拿到41.4,Opus-4.6是40.0。
它在数学竞赛方向同样强势,IMOAnswerBench上拿到90.0,Apex上拿到44.5,两项均超过DeepSeek V4 Pro。
编程方面同样拿得出手。
Terminal Bench 2.0-Terminus是一个模拟真实终端开发环境的编程智能体基准,Qwen3.7-Max得分69.7,超过DS-V4-Pro Max的67.9和Opus-4.6的65.4。
SWE系列覆盖真实软件工程任务,Pro、Multilingual、Verified三个子榜上,Qwen3.7-Max均处于当前第一梯队。
前端生成方面,给一条prompt,它可以直接输出带Three.js 3D场景、Canvas动画或动态SVG的完整页面。
用Three.js创建一个实时交互的3D粒子系统网页。要求:1.通过摄像头检测手掌张合控制粒子群的收缩与扩散,当手掌张开时例子扩散,当手掌握紧时例子收缩为一个球;2.当手势为1时,粒子组成文字(hello, world),当手势为2时组成文字 (I’am Qwen);3.粒子需实时响应手势变化;4.文字应有3D旋转效果;5. 用html实现
指令遵循、多语言、长文本方面,Qwen3.7-Max也都跟得上。
IFBench衡量的是模型对复杂指令的精准执行能力,Qwen3.7-Max拿到79.1,超过DeepSeek V4 Pro的77.0。
长文本理解MRCR-v2 128k上它拿到90.4,超过Opus-4.6的84.0,在需要从超长上下文中精准定位信息的任务上表现稳定。
多语言评测WMT24++覆盖55种语言,MAXIFE覆盖23种语言设置,在两个Bencmark中Qwen3.7-Max也均处于领先位置。
跨框架Agent能力这样炼成
Qwen3.7-Max能练出这些能力,背后有一套方法论,核心是训练环境的扩展方式。
阿里把每个训练实例拆解成三个相互独立的组件,包括任务、运行框架和验证器。
三者可以自由重组,同一个任务可以低成本地和不同类型、不同版本的框架及验证器组合,这让训练规模的扩展变得更高效。
更关键的是,模型在训练时会在多变的框架配置下处理同一批任务,被迫学习真正解决问题的策略,而不是记住某个特定框架的使用习惯。
除了组建之外,另一个关键是训练环境全部来自真实场景,不使用合成替代品。
评测时使用的,也全是训练中从未出现过的领域外环境。
这种设定意味着模型在测试时面对的永远是陌生的组合,它能答对,靠的只能是真实的泛化能力。
阿里观察到一个规律:任意基准子集上的性能增益高度一致,可以可靠地预测其他基准的相对增益。
换句话说,能力的提升是整体性的,通过观察它在A测试上进步了多少,基本可以准确预测它在B测试上会进步多少。
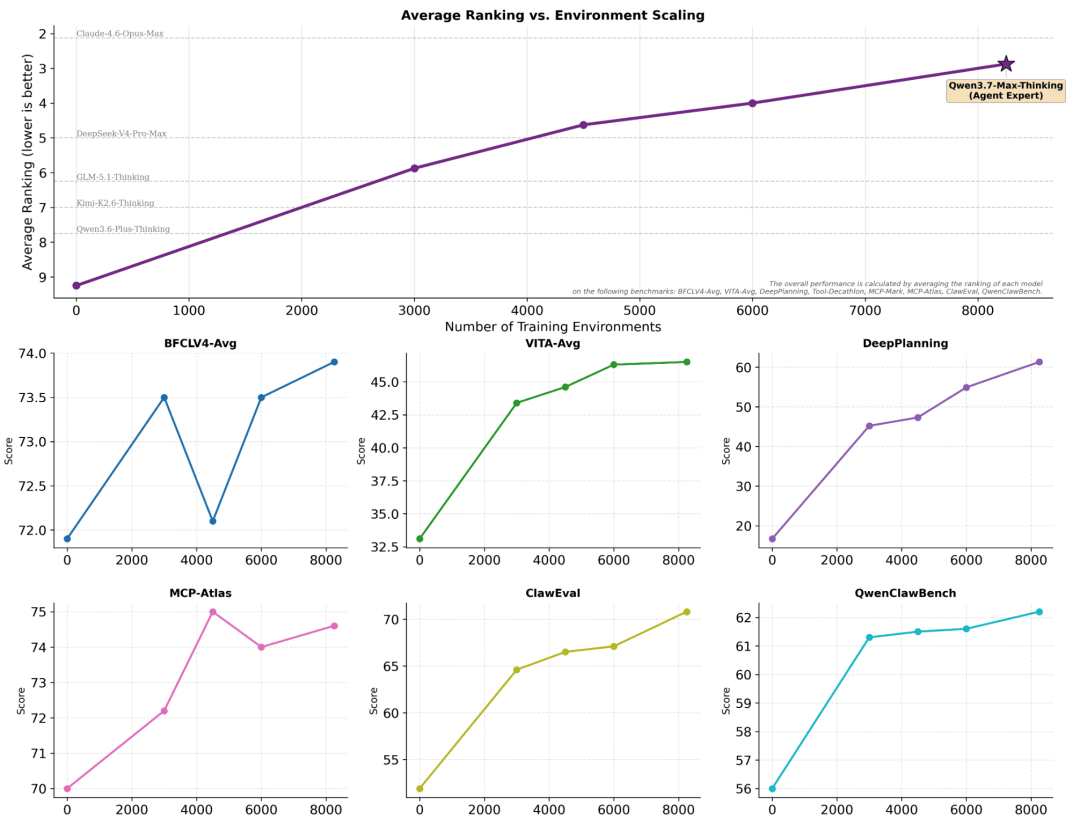
这说明环境扩展带来的不是针对某几个评测的过拟合,是模型在更底层的任务理解和执行能力上的真实提升。
这套方法也解释了为什么Qwen3.7-Max在跨框架场景下表现如此稳定。
它在训练时从未针对Claude Code、OpenClaw或Qwen Code做过专项优化,但放到这些框架里跑,结果依然一致。
正是因为训练过程中模型始终面对的是任务和框架的随机组合,它才没有机会走捷径,只能把解决问题的能力真正内化下来。
参考链接:
https://qwen.ai/blog?id=qwen3.7
本文来自转载量子位 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫